HDFS
HDFS 개요
- Hadoop을 지탱하는 데이터 저장소
- large file을 handling 하는데 최적화됨
- reliable manner로 big data(from sensor,webserver...)를 저장
- application이 data를 빠르고 reliable하게 데이터에 접근하게 해줌
HDFS의 장점
- large file을 block 단위(128MB)로 나눠서 분산 저장
→ single hard drive의 용량을 넘겨서 저장가능 - 분산처리로 효율적인 데이터 처리 가능
- block을 하나만 저장하는 것이 아니라 복제해서 여러개 저장
→ failure handling이 쉬움
→ 굳이 high availablity를 가진 장비를 사용하지 않아도 됨
HDFS의 동작
HDFS의 구성
- client node
- 사용자를 대신해 name node와 data node에 통신하고 파일시스템에 접근
- POSIX와 유사한 파일 시스템 인터페이스를 제공해서 name node, data node에 관련된 함수를 몰라도 코드 작성 가능
- name node
- 저장되는 데이터에 대한 메타데이터 정보를 담고있다.
- 메타데이터 정보는 edit log 와 namespace image(fsimage)에 나눠 저장됨
- namespace image는 파일시스템 데이터의 영속적인 체크포인트 파일, 하지만 개별 쓰기 동작 때마다 갱신되지는 않는다.
- edit log는 파일의 변경사항이 있을 때 transaction log를 기록하는 곳
- 파일의 정확한 위치는 디스크에 저장하지 않고 시스템이 시작될때 data node로 부터 위치정보를 받는다.
- data node
- client 나 name node의 요청이 있을때 그 요청을 처리하는 실질적인 일꾼
- 저장하고 있는 블록의 목록을 name node에게 주기적으로 보고한다.
Read
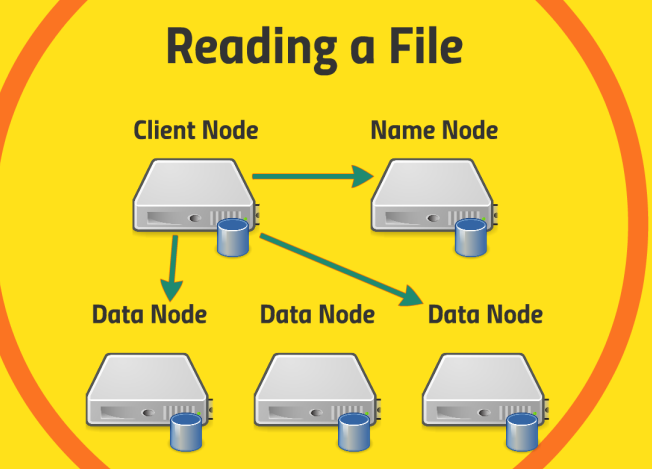
- client node가 name node에게 읽으려는 파일의 위치를 요청
- name node로부터 받은 위치정보를 이용해서 client node는 data node로부터 데이터를 가져옴
Write
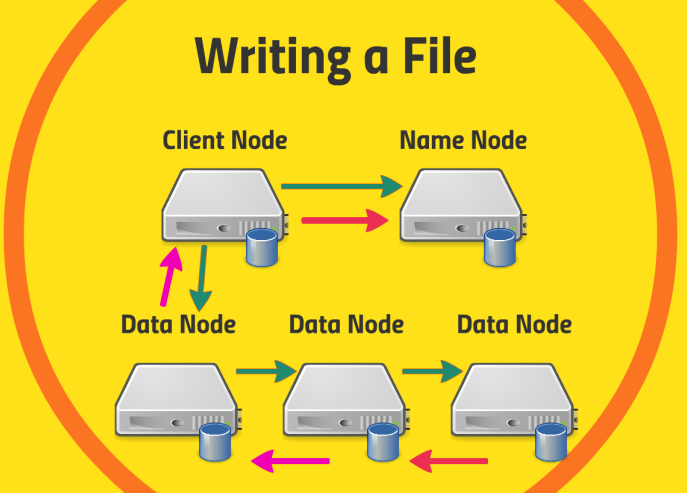
- client node가 name node에게 쓰기를 시작하겠다고 알림
- client node는 해당 file을 data node에게 전달
- data node는 data node들끼리 정보를 공유하며 파일을 분산해서 저장(파일의 복사본 포함)
- 쓰기 작업이 완료되면 client node에 성공적으로 끝났다고 알림
- client node는 이어서 name node에게 해당 파일이 replicated manner로 잘 저장되었다고 알림
Namenode resilience
- Back up Metadata : Namenode에 저장되는 정보를 local, NFS에 동시에 백업
- Secondary Namenode
- Primary Namenode의 edit log가 일정 용량에 도달하거나 일정 주기에 맞춰 namespace image와 edit log를 Secondary namenode에 보낸다.
- Secondary namenode는 namespace image를 edit log를 통해 최신화하고 namesapce image를 다시 주 네임노드에 보냄
- 주 네임노드의 edit log 용량을 관리해주고 동시에 백업의 역할도 함
- HDFS Federation
- 저장된 파일의 개수가 늘어나면 단일 네임노드로 운영이 힘들어짐
- 파일시스템을 여러개의 namespace volume으로 나누고 각 namespace에 하나의 네임노드를 배정하는 방식
- namenode가 failure되도 전체의 데이터가 날아간게 아니라 일부만 날아간다는 장점
- HDFS HA(High Availablity)
- Primary Namenode의 메모리에는 namespace image, edit log 외에 블록 매핑 정보도 담고있다.
- 그래서 단순히 namesapce image를 복구하는 것만으로 장애에 즉각적으로 대응하기 어려움
- Standby namenode를 둬서 Primary namenode와 동기화 한다.(메모리에 있는 정보까지)
- 공유 스토리지에 shared edit log를 저장해서 두 네임노드가 edit log를 공유
- data node의 block report를 두 네임노드 모두에게 보냄
- Standby namenode는 Secondary namenode의 역할까지 수행해서 활성 네임노드 namespace image를 checkpoint 작업도 주기적으로 실행한다.
- Active namenode가 다운되면 바로 standby namenode로 즉각적으로 대체가능
- standby namenode를 사용하는 경우 두 개의 namenode가 활성화되어 있다고 다른 노드들이 착각을 할 수 도있다.
- 이런 경우를 대비해 Hadoop HA는 zookeeper에게 활성 네임노드가 어떤 노드인지 확인하고 다른 네임노드의 전원을 꺼버린다.
HDFS 사용법
- UI : 파일을 단순히 복사하고 HDFS의 디렉터리 구조를 시각화하고 싶을때 사용
- CLI : HDFS 명령어를 입력하는 방식
- HTTP
- HTTP로 HDFS를 직접 or proxy 서버를 통해 다룰 수 있음
- proxy 서버는 HDFS 머신과 클라이언트 사이에 위치
- 데이터를 분석하기 위해 스크립트를 작성하거나 애플리케이션 개발을 위해 이 프락시 서버에 웹 인터페이스를 구성할 수도 있음
- Java interface
- 대부분의 언어들은 자바 코드와 소통할 수 있기 때문에 C나 Python 혹은 Scala 등을 사용해도 무관
- hadoop은 java로 작성되어서 관련 기술들에는 java client가 모두 있음
- NFS Gateway
- NFS는 네트워크 파일 시스템, remote file system을 server에 mount
- NFS 게이트웨이를 통해 HDFS를 리눅스 박스에 연결할 수 있음
- 그러면 하드 드라이브에 또 다른 마운트 지점이 생긴 것처럼 보이고 HDFS와 전혀 관련 없는 프로그램들도 사용할 수 있게 됨
명령어 실습
xshell or putty 와 같은 treminal emulator를 통해 hortworks가 설치된 VM에 SSH접속
maria_dev@127.0.0.1:2222
hadoop fs -{명령어}
hadoop fs -ls : 파일 시스템의 목록을 보여줌
hadoop fs -mkdir {dir_name}
wget http://media.sundog-soft.com/hadoop/ml-100k/u.data
wget : 웹에서 파일 다운로드를 도와주는 리눅스 command
hadoop fs -copyFromLocal {local_file_path} {hdfs_file_path}
hadoop fs -rm {hdfs_file_path}
hadoop fs -rmdir {hdfs_dir_path}
hadoop fs : 명령어 help
