2주차는 SQL 문법인 관계로 생략
들어가기 앞서
<당부의 말>
GhatGPT
- 프롬프트를 잘 써줘야한다. 테스트케이스를 잘 생각해서 검증을 해줘야함
- 생산성은 좋은데 주니어 개발자의 느낌 (융통성이 조금 떨어짐)
<질문 1>
DW에서 Primary key uniqueness가 보장이 안되는데 왜 이 속성 지정이 필요한가?
- DW의 SQL optimizer에게 힌트를 주는것
- Data Warehouse Primary key uniqueness를 보장을 못하지만
- 개발자가 보장을 한다는 전재하에 이것이 unique하다는 힌트로 SQL 쿼리를 수행할때 최적화를 해라
<질문 2>
AWS Redshift의 데이터 복구는 어떻게 하나요?
- AWS console에서 Action이라는 메뉴에 가보면 Restore table이라는 것이 있다.
- 특정 snapshot을 찾고 새로운 테이블로 저장
- default로 이전 하루의 snapshot만 저장 (최대 36일까지 지정가능)
비구조화된 데이터 처리
<시나리오 1> : 비구조화된 데이터를 데이터 웨어하우스에 적제
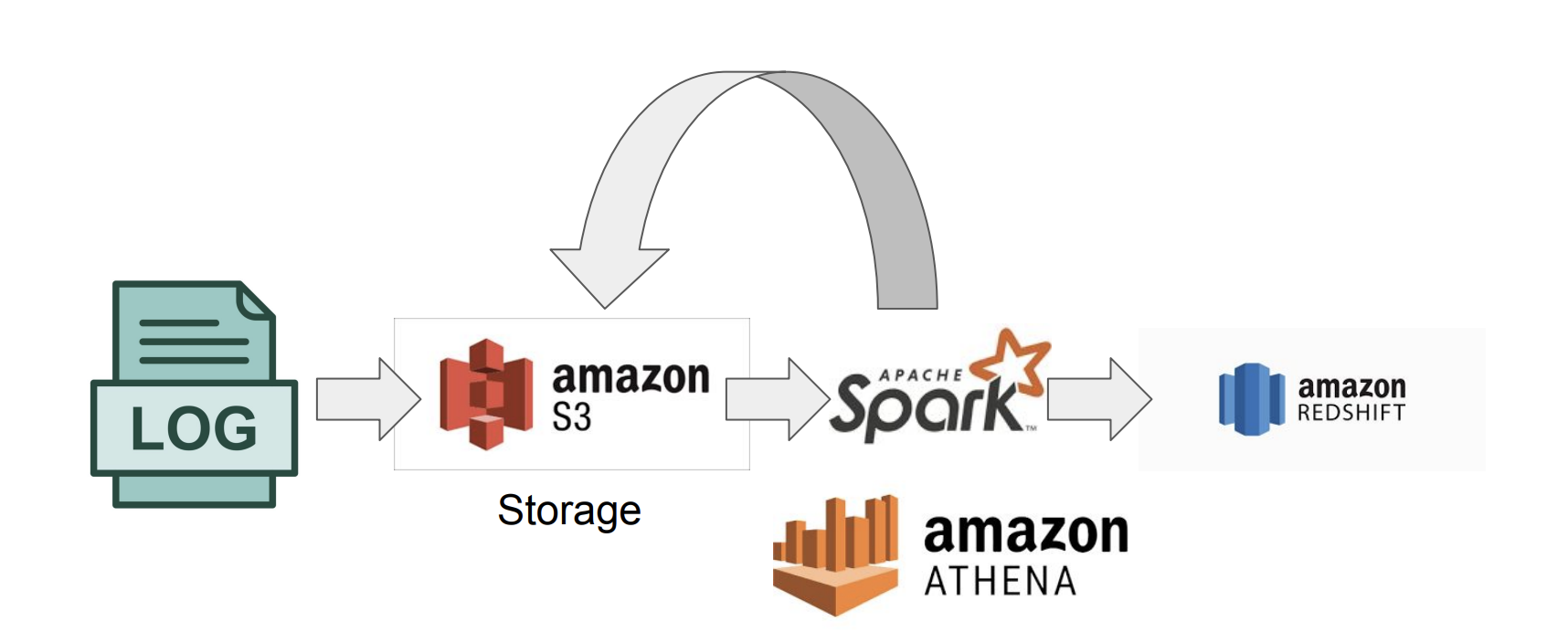
- 대용량이며 비구조화된 데이터의 대표적인 예가 Log 데이터
- log를 S3(data lake)에 저장
- S3!=datalake, S3를 data lake 개념으로 사용 O
- S3는 굉장히 싸다 1TB쓰는데 한달에 만원정도
- SparkSQL, amzon ATHENA(presto) 정제 (원하는 정보만 추출하는 단계, 보통 크기가 작아짐)
- Redshift와 같은 데이터 웨어하우스에 저장
- Spark을 통해 비구조화된 데이터를 처리하는 방법은 다양함
- SparkSQl을 쓰는 방법, 아니면 Pandas의 dataframe을 쓰는 방법
- SparkSQL을 쓰는 방법은 SQL로 데이터를 다루는 방법이여서 declarative language(원하는게 한큐에 보임)
- Dataframe을 쓰는 방법은 procedure language(Step by Step)하게 한땀한땀 코딩하는 방법이다. 코드양도 많아지고 readability가 떨어지는 단점이 있다.
- 실제로 현업에서는 dataframe을 다루는 경우보다 SQL을 이용하는 경우가 많다.
- 하지만 dataframe을 쓰는 특별한 경우가 있다. 복잡한 비구조화된 데이터를 로딩해서 파싱하는 복잡한 일을 할때는 dataframe을 쓴다.
<시나리오 2> : 머신러닝 모델의 feature를 대용량, 주기적으로 생성
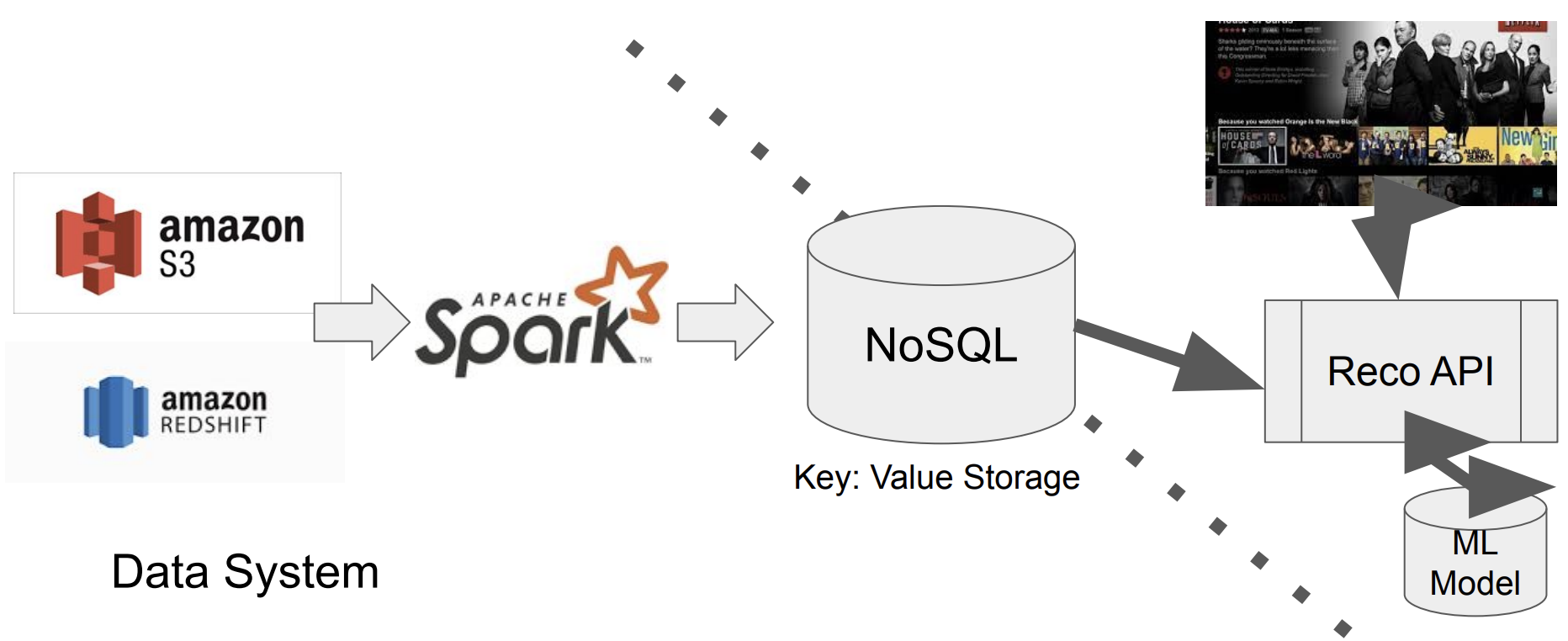
- 데이터 웨어하우스, 레이크에 저장된 대규모 데이터에서 머신러닝 모델에 쓰일 feature를 주기적으로 computation하는 작업은 보통 Spark을 쓴다.
- 위의 경우를 생각해보자.
- Airflow를 통해 "spark로 job을 돌려서 cassandra와 같은 NoSQL에 모델이 필요한 feature를 계산"하는 task를 daily로 수행하는 DAG을 생성
- runtime에 사용자가 login 하면 추천 API를 통해 NoSQL에 저장된 feature를 추천모델에 넣어 결과를 반환해준다.
- Spark에는 기능이 굉장히 많다.
- dataframe, SQL, streaming, MLlib, Graph
- 빅데이터 프로세스 종합 선물세트 😆
데이터 파이프라인
데이터 파이프라인 이란?
- ETL, ELT, Data Workflow, DAG → 데이터 파이프라인을 부르는 다양한 말
- 데이터파이프라인을 작성/관리하기 쉽게 해주는 것이 Airflow
- ETL : 데이터를 데이터 웨어하우스 외부에서 내부로 가져오는 프로세스
- ELT : 데이터 웨어하우스,레이크 내부 데이터를 조작해서 (보통은 좀더 추상화되고 요약된) 새로운
데이터를 만드는 프로세스- ELT 과정은 dbt라는 tool을 사용하는 것이 일반적, 이러한 일을 하는 직군을 Analytics Engineer라고 한다.
- 데이터 파이프라인의 목적은 소스를 목적지로 복사, 기본적으로는 목적지 데이터 웨어하우스
- 캐시 시스템 (Redis, Memcache), 프로덕션 데이터베이스, NoSQL, S3, ...도 목적지가 될 수 있음
Data Lake
- 구조화, 비구조화 데이터를 담음
- 보존 기한이 없는 모든 데이터를 raw data형태로 저장하는 스토리지(S3:웹 storage)
- 보통 데이터 웨어하우스보다 몇배 큼
- 굉장히 크기가 큰 소스는 바로 데이터 웨어하우스에 들어가는게 아니라 데이터 레이크에 일단 적제
Spark, Athena.. 와같은 것으로 처리해서 웨어하우스, 마트에 적제
data warehouse
- 보존 기한이 있는 구조화된 데이터를 저장하는 스토리지
- BI툴들은 데이터 웨어하우스를 백엔드로 사용함
<질문 3>
S3를 data lake라고 하신건 비구조, 구조화 데이터가 함께 쌓일 수 있지만, REDSHIFT를 DW라고 하는 것은 RDB 여서 그런걸까요?(ㅒ)
<질문 4>
Data warehouse, Datalake외에 Data mart 라는 용어의 정의는 어떻게 될까요?
- 미국에서는 데이터 마트라는 말을 써본적이 없다.(일했던 회사들이 온라인 회사여서 그럴수 있음)
- 굉장히 구체적인 용도의 데이터 웨어하우스, 특정 부서를 위한 데이터 웨어하우스
데이터파이프라인의 종류
- ETL - 데이터 엔지니어
- 소스(보통 API)에서 Extract해서
- 포맷 변환(Transform) - spark, athena
- 데이터 웨어하우스에 Load
- ELT - 데이터 분석가
- Summary/Report Jobs 이라고 볼 수 있음
- 데이터 웨어하우스, 레이크에 있는 것을 이용해서 정보를 새로 만들어서 DW에 다시 쓰는 작업
- Dashboard에 쓰기위한 데이터를 정재하는, A/B test의 결과를 분석하는 용도
- 아주 간단하게 생각하면 CTAS 써서 이미 존재하는 데이터를 Join해서 새로운 테이블을 만든다고 생각하면된다
- CTAS의 단점이 많아서 이것을 범용화 한것이 dbt
- CTAS는 테스트를 붙일 수 없는데 dbt는 입력/출력에 대한 테스트를 만들 수 있어 데이터의 정합성을 확인 할 수 있다. (Analytics Engineer)
- production data jobs
- dw 로부터 데이터를 읽어 다른 storage(프로덕션 환경)로 쓰는 ETL
- summary 정보가 프로덕션 환경에서 성능 이유로 필요한 경우
- 머신러닝 모델에 필요한 피쳐들을 미리 계산해두는 경우
- 이 경우 흔한 타겟 스토리지는
- NoSQL(Cassandra, HBase, DynamoDB)
- OLTP(MySQL, Postgresql)
- Redis/Memcache와 같은 캐시
- ElasticSearch와 같은 검색엔진
- Summary/Report Jobs 예(Youtube like/view count)
- Youtube에서 갑자기 뜨는, 굉장히 유명한 동영상은 view/like count를 실시간으로 처리하기 어려움
- 이용자가 많아서 계산해야할 것이 많고 실시간으로 처리하게되면 시스템이 뻗어버림
- 그리고 사실 view/like count와 같은것은 굳이 실시간 처리할 필요없기도함
- 그래서 이 경우 계산 부하가 큰 건에 대해서는 batch 처리하는 것을 고려해 볼 수 있음
- batch 처리 ??? 프로덕션 db에서 수행하지말고 데이터 웨어하우스에서 쿼리를 수행하고 결과를 주기적으로 프로덕션 DB에 쏴주자
- 이런식으로 데이터 파이프라인은 서비스나 시스템의 bottleneck을 해결하는 용도로도 쓰인다.
ETL 실습의 문제점
1. Header가 포함됨
2. 데이터의 정합성, 데이터 파이프라인 관점에서 똑같은 데이터가 반복해서 저장되서 멱등성이 깨짐
3. LOAD 하는 과정에서 중간에 중단되면 consistency가 깨짐(transaction 이용)
Airflow
Airflow 소개
Airflow 데이터 파이프라인을 관리/구현을 도와주는 가장 유명한 opensource
- python으로 구현되어 있는 데이터 파이프라인 플랫폼(단순 스케줄링만이 아님)
- 다양한 모듈(프래임워크) 제공
- Web UI 제공(Webserver)
- 시스템에 대한 연결정보를 코드에서 관리하는 것이 아니라 aiflow에서 connection object로 UI상에서 관리를 할 수 있다.(ID,PW,포트 등등의 중요정보를 object로 관리하여 숨길 수 있음) - data pipeline은 DAG라고 부름
- Worker(s) 와 a scheduler로 구성됨(하나의 서버로 구성될 수도 있고 여러개로 구성될 수도 있음)
- 여러개로 구성되는 경우 쿠버네티스 환경을 사용하는 것이 선호됨
- DAG, scheduling 정보를 저장할 별도의 DB를 가지며 SQLite가 default임(SQLite은 퍼포먼스가 별로여서 실제 프로덕션 환경에서는 MySQL, Postgres가 선호됨)
- opensource여서 다양한 3rd party services를 제공
- 모든 오픈소스는 최신버전을 사용하는 것이 최선이 아님, 큰 회사가 어떤 버전을 사용하는지 확인해보면 어떤 버전이 안정적인 버전인지 알 수 있음
- GCP : cloud composer (2018~)
- AWS : Amazon Managed Workflows for Apache Airflow(MWAA) (2020.12~)
- AZURE : Managed Airflow (2023~)
- Airflow 만든사람은 Maxime Beauchemin
- yahoo - facebook - airbnb - lyft(like uber, no 2) - dashboard tool(superset)로 창업(Preset)
- airflow(astronomer라는 회사가 사용화), superset을 만듦
Airflow 의 구성
-
Webserver : python의 flask로 구성됨
-
Scheduler
- cronjob, jenkkins처럼 원하는 시간에 실행시켜주는 역할
- 어떤 job이 끝나면 다음 job이 실행
- S3에 어떤 파일이 저장되면 이게 trigger되서(Sensor)
- worker의 수보다 datapipeline의 수가 많은 경우 job을 queue에 보냄
- Worker
- 워커는 queue에 있는 데이터파이프라인 테스크를 가져가서 실행하는 형태로 돌게됨
- 하나의 노드로 Airflow를 구성하면 보통 CPU의 수만큼 worker가 존재
- DAG의 수가 늘어남에 따라 보통 워커의 수를 scaling하는 것이 일반적
- udemy도 시리즈 C 펀팅 받을때 까지는 서버 한대를 사용
- kubernetes를 사용해서 worker pod를 scale 하는 방법도 사용할 수 있음
- Database
- 실행될때 나오는 여러가지 정보(metadata, ex.log)
- 기본은 Sqlite 퍼포먼스가 안좋아서, 보통 mysql, postgres를 씀
- Queue
- 멀티노드 구성인 경우에만 사용됨
- 이 경우 Executer가 달라짐 (CeleryExecutor, KubernetesExecut)
초기에는 서버 한대(ex. EC2)로 사용하다가 규모가 커지면 cloud service에서 관리해주는 airflow를 고려해볼 수 있음(하지만 비쌈)
Airflow의 장단점
장점
- 데이터파이프라인을 세밀하게 제어
- 다양한 데이터 소스와 데이터 웨어하우스를 지원
- 백필이 쉬워짐
단점
- 생각보다 러닝 커브가 있음
- 상대적으로 개발환경을 구성하기가 쉽지않음
- 직접 운영이 쉽지 않음. 클라우드 버전이 사용이 선호됨
Airflow의 실행단위
DAG(Directed Acyclic Graph)
- Airflow의 ETL을 부르는 명칭
- DAG에는 tags라는 파라미터가 있는데 이것을 이용해서 dag를 filtering
- DAG는 start_date과 catchup을 지정할 수 있음
- catchup을 True로 하면 start_date기준으로 실행되었어야할 job도 모조리 실행
- start_date은 최초 수행시간을 나타내는 것이 아니라 처리하고 싶은 데이터의 최초 시점임
- 최초 수행 시간은 start_date + interval이라고 할 수 있음
task : 특정 목적을 가진 일을 수행하며 여러개의 task가 모여 DAG를 구성
Operator
- task가 수행하는 연산의 종류를 나타냄, 다양한 종류의 operator가 있음
- 경우에 맞게 사용 오퍼레이터를 결정하거나 필요하다면 직접 개발(Python Operator)
- dummyoperator는 보통 시작과 끝을나타낼때 자주쓴다.
한국에서 airflow를 가장 많이 사용하는 곳 coupang, airflow cluster가 몇개가 있음
발생할 수 있는 문제들
- 데이터파이프라인은 기본적으로 코드이기 때문에 버그가 존재
- 데이터 소스가 문제가 있으면 데이터 파이프라인이 돌지 않는다.
- 데이터 파이프라인들간의 의존도에 이해도 부족
- 데이터 파이프라인의 수가 늘어나면 유지보수 비용이 기하급수적으로 늘어남
- 이 파이프라인은 안쓰니까 삭제해야지~ → 다른 파이프라인이 안돌아가는 문제 발생;
- 누군가 데이터를 데이터 시스템안으로 가져올때 기록을 잘해둬야함
- 이 파이프라인은 누가 요청을 한것?, 뒤에서 누가 소비하는가?
- 보통 data catalogue tool을 사용해서 관리함
Best practice
- 데이터가 작을때 update해야하는 경우 기존의 테이블을 날리고 매번 테이블의 내용을 새로 갱신하는 것이 좋음(Full Refresh)
- Incremental update만 가능하다면(바뀐부분만 변경), 대상 데이터 소스가 갖춰야하는 몇가지 조건이 있음
- created(데이터 업데이트 관점에서 필요하지 않음), modified, deleted 필드가 필요
- 데이터 소스가 API라면 특정 날짜를 기준으로 새로 생성되거나 업데이트된 레코드들을 읽어올 수 있어야함
- 멱등성(Idempotency)을 보장하는 것이 중요
- 동일한 입력 데이터로 데이터 파이프라인을 다수 실행해도 최종 테이블의 내용이 달라지지 말아야함
- 예를 들어 중복 데이터가 생기지 말아야함
동일한 입력 데이터로 데이터 파이프라인을 다수 실행해도 최종 테이블의 내용이 달라지지 말아야함
- 과거 데이터를 다시 채우는 과정(backfill, 재실행)이 쉬워야 함
- Airflow는 backfill에 강점
- DAG의 catchup 파라미터가 True가 되어야하고 start_date, end_date이 적절히 설정되얗마
- 대상 테이블이 incremental update가 되는 경우에만 의미가 있음
- execution_date 파라미터를 사용해야함, 현재시간을 사용하면안됨
- execution_date : 해당 데이터 파이프라인이 실행됬어야할 시간을 나타내는 파라미터
- 데이터 파이프라인의 입력과 출력을 명확히 하고 문서화(정확하게 문서화하는 것은 힘들기 때문에 보통 data catalogue 툴을 씀)
- 주기적으로 쓸모없는 데이터들을 삭제(누가 주인인지 확인, 너무 많은 파이프라인을 관리하면 비용이 많이 발생함, storage비용, spark비용)
- 데이터 파이프라인 사고시 마다 사고 리포트(post-mortem)쓰기 (blame의 목적이 아님, 재발을 막자!) (프로젝트 수행할때 해보면 좋을거같음)
- 조용하게 동작해도 이슈가 발생할 수 있음(summary table을 만드는데 아무것도 안남더라, 100만개가 만들어져야하는데 1만개만 만들어졌더라. 입력과 출력의 조건을 확인하는 것이 굉장히 중요해짐 => dbt를 사용하면 ELT에관해선 퀄리티 체크가 쉬움)
- 다양한 체크포인트(테스트)를 생각해봐야함
<질문 5>
python operator를 통해 ETL을 할때 데이터 용량이 제한이 있다는 것으로 알고 있는데 대용량 데이터를 다룰때 어떻게 해야하나요?
- 기본적으로 하나의 서버로 구성되기 때문에 대용량 데이터를 다루는 것은 python으로 못한다.
- 보통 Spark cluster를 구성하고 SparkOperator를 사용해서 분산처리한다.
