논문 제목: Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
DeepLab v3+ 개요
Spatial pyramid pooling(SPP)와 encoder-decoder 구조는 semantic segmentation에서 사용된다. SPP는 multi-scale contextual 정보를 encode할 수 있게 한다. Encoder-decoder 구조는 객체 경계를 더 섬세하게 포착할 수 있게 한다.
본 논문의 저자들은 두 방법의 이점들을 결합을 제안하며 특히 이전 버전인 DeepLab v3에 간단하지만 효과적인 decoder를 추가하므로써 DeepLab v3+를 제안한다. 또한 추가적으로 Xception model을 연구하고 depthwise separable convolution을 Atrous Spatial Pyramid Pooling과 decoder에 적용했다.
논문의 저자들은 자신들의 기여를 다음과 같이 소개한다.
- DeepLab v3라는 강력한 encoder와 간단하지만 효과적인 decoder를 사용한 새로운 encoder-decoder 구조를 제안한다.
- Atrous convolution을 통해 추출된 encoder features의 해상도를 임의로 조절할 수 있다. 기존의 encoder-decoder 구조에서는 불가능하다.
- Xception model을 채택하고, depthwise separable convolution을 atrous spatial pyramid pooling(ASPP module)과 decoder에 적용했다. 이는 빠르고 강력한 encoder-decoder network를 만든다.
- 제안된 모델은 PASCAL VOC 2012와 Cityscapes dataset들에서 sota의 성능을 보여준다.
Methods
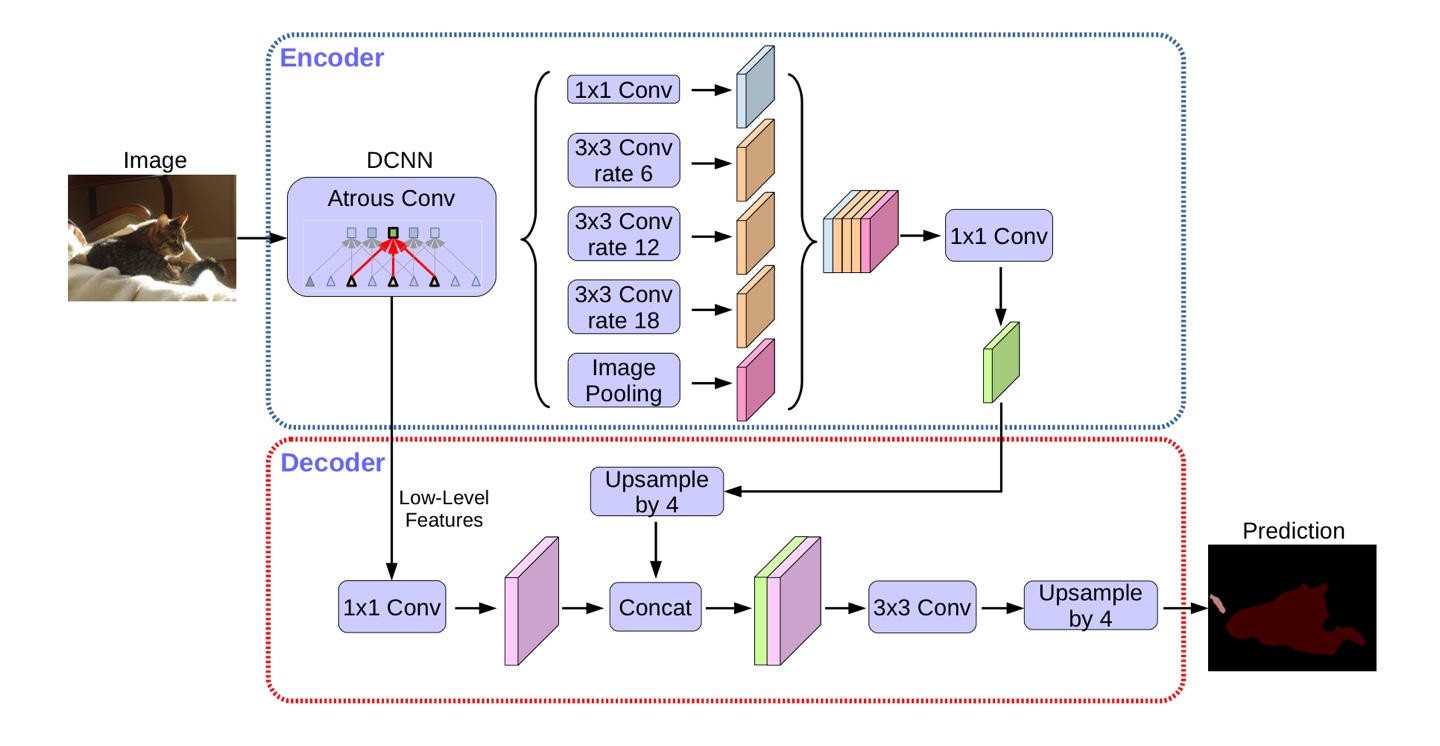
 사진 1. DeepLab v3+ architecture
사진 1. DeepLab v3+ architecture
1. Encoder-Decoder with Atrous Convolution
Atrous convolution
 사진 2. atrous convolution
사진 2. atrous convolution
Atrous convolution은 DCNN에 계산되는 features의 해상도를 명시적으로 조절할 수 있게 하고, 다양한 크기의 정보를 포착하기 위해 convolution filter의 field-of-view를 조절할 수 있게 한다.
Trous는 프랑스말로 구멍을 뜻한다. 위의 사진 2와 같이 convolution 연산시 rate에 따라 filter에 구멍을 뚫어 연산을 진행한다. Atrous convolution은 dilated convolution이라고도 한다. 수식으로 표현하면 다음과 같다.
: each location in feature map
: output feature map
: input feature map
: convolution filter
: dilate rate
: kernel size
r(dilate rate)이 1인 경우 기존의 convolution 연산을 나타낸다.
Atrous convolution은 pooling을 수행하지 않고도 receptive field를 크게 가져갈 수 있어서 spatial 정보의 손실이 적고 대부분의 weight가 0이기 때문에 연산의 효율이 좋다. Spatial 정보를 유지하기 때문에 segmentation에서 자주 사용된다.
Depthwise separable convolution
 사진 3. depthwise separable convolution
사진 3. depthwise separable convolution
Depthwise separable convolution은 depthwise convolution(사진 3.a)과 pointwise convolution(i.e. 1x1 convolution)(사진 3.b)의 연속된 구조로 구성되고, 연산량을 굉장히 줄인다. 특히, depthwise convolution은 각각 channel에 대해 spatial correlation에 대한 연산을 수행하고, pointwise convolution은 depthwise convolution의 결과를 결합시키는 channel correlation에 대한 연산을 수행한다. 논문의 저자들은 atrous depthwise convolution(사진 3.c)과 pointwise convolution(사진 3.b)를 결합시킨 atrous separable convolution을 사용했다. Atrous separable convolution은 제안된 모델의 성능을 유지하면서(혹은 좋게하면서) 연산 복잡도를 상당히 감소시킨다.
import torch
import torch.nn as nn
class AtrousSeparableConv2d(nn.Module):
def __init__(self, inplanes, planes, kernel_size=3, stride=1, dilation=1, bias=False):
super(AtrousSeparableConv2d, self).__init__()
self.conv1 = nn.Conv2d(inplanes, inplanes, kernel_size, stride, padding=0, dilation=dilation,
groups=inplanes, bias=bias)
self.bn = nn.BatchNorm2d(inplanes)
self.pointwise = nn.Conv2d(inplanes, planes, kernel_size=1, stride=1, padding=0, dilation=0,
groups=1, bias=bias)
def forward(self, x):
x = fixed_padding(x, self.conv1.kernel_size[0], self.conv1.dilation[0]) # feature map HxW 유지하기 위한 padding
x = self.conv1(x)
x = self.bn(x)
x = self.pointwise(x)
return xDeepLab v3 as encoder
 사진 4. deeplab v3
사진 4. deeplab v3
DeepLab v3는 위의 사진 4와 같은 구조이고, atrous convolution을 이용해 임의의 해상도 feature들을 추출한다. 논문의 저자들은 output stride를 입력의 해상도와 마지막 출력의 해상도의 비율로 정의한다.(이때, 마지막 출력은 global pooling 또는 fully connected 이전의 출력)
대체로 classification의 경우 output stride가 32이다. 반면에 semantic segmentation을 위한 denser feature 추출을 위해 마지막 1(또는 2)개의 block에서 striding을 제거하고, atrous convolution을 적용해서 output stride를 16(또는 8)로 한다.
DeepLab v3는 다양한 dilate rate의 atrous convolution 적용하므로써 다양한 크기에 대해 convolutional feature들을 탐사하는 Atrous Spatial Pyramid Pooling (ASPP) module을 image-level feature로 확장한다.
사진 4에서 block4 이후 multi-scale을 처리하는 ASPP module(사진 4.a)과 image pooling(사진 4.b)을 확인할 수 있다.
먼저 ASPP module은 기존의 adaptive pooling(output의 resolution을 고려한 pooling)을 사용해 다양한 크기의 pooling을 수행한 후 concatenate하는 spatial pyramid pooling을 atrous convolution을 사용해 변형한 것이다. 즉 다양한 크기의 pooling을 적용하는 것이 아닌 다양한 크기에 대해 연산을 수행가능한 atrous convolution을 적용해 연산을 수행하고 그 결과들을 channel wise로 concatenate 한다.
참고) ASPP module은 DeepLab v2에서 처음 나온 개념으로 SPPNet의 spatial pyramid pooling의 좋은 성능에 영감을 받아 실험을 통해 개발하게된 구조이다.
 사진 5
사진 5
ASPP module은 여러 dilate rate를 사용하는데 이때 dilate rate가 커지게 되면 atrous convolution filter의 가중치 중 유의미한 가중치의 개수가 줄어드는 것을 실험을 통해 확인할 수 있었다. 예를 들면, 3x3 filter의 atrous convolution filter에서 dilate rate가 큰 경우 유의미한 가중치의 개수가 줄어들어 3x3 filter가 단순한 1x1 filter로 퇴화되는 것을 확인할 수 있다. 해당 문제는 다음 사진 5를 통해 확인할 수 있다.
이는 DeepLab v3에서 발견한 문제로 이를 해결하고, global context 정보를 통합시키기 위해 image-level featrue들을 채택한 image pooling(사진 4.b)을 사용한다. Image pooling은 사진 4 block4에서 나온 feature map들에 global average pooling 후 256개의 1x1 filter를 적용한다. 이렇게 나온 결과를 bilinearly upsample을 해서 ASPP 모듈의 resolution과 맞춰준 후 concatenate를 한다.
Concatenate된 feature map들을 1x1 convolution을 적용하면 풍부한 semantic 정보를 갖는 256 channel의 encoder output이 된다.
Proposed decoder
사진 6. DeepLab v3+ architecture
 사진 7. Encoder-Decoder
사진 7. Encoder-Decoder
참고) 참고 그림들이 DeepLab V3와 DeepLab V3+에서 혼용되어 사용되어 각 그림마다 output stride와 설명의 output stride가 8 또는 16이 혼용되고 있는데, 이는 단지 dilate rate에 영향을 받을 뿐 네트워크 구조 차원에서는 변화가 없다.
DeepLab v3 encdoer feature들은 output stride가 16이다. DeepLab v3에서는 encoder feature들을 단순히 16배 bilinear upsample을 수행한다. 이는 naive decoder로 생각할 수 있다. 그러나 이러한 naive decoder는 object segmentation details를 복원하지 못 한다.
따라서 논문의 저자들은 사진 6에 나와 있는 간단한 decoder 구조를 제안한다. Encoder에서 나온 encoder feature를 4배 bilinear upsample을 수행한다. 그 다음 backbone network 중간에서 나온 feature maps(Low-Level Features)을 1x1 convolution을 적용하여 channel을 줄인다. 이 둘을 concatenate한 다음 3x3 convolution layers를 거친 후 마지막 1x1 convolution을 거쳐 나온 output을 원래 input size로 bilinear upsample(4배)을 한다.
2. Modified Aligned Xception
 사진 8. 좌측 Xception, 우측 modified aligned Xception
사진 8. 좌측 Xception, 우측 modified aligned Xception
사진 출처: 링크
Xception 모델은 classification에서 빠른 연산과 함께 좋은 성능을 보여줬다. 최근 MSRA에서 Xception을 수정하여 object detection에서 좋은 성능을 보여준 것에 영감을 받아 논문의 저자들은 다음과 같은 수정을 거친 Xception 모델을 backbone network로 사용했다.
- Entry flow에서는 빠른 연산과 메모리 효율을 위해 수정을 하지 않았다.
- 모든 max pooling 연산은 depthwise separable convolution with striding로 대체되었다.
- 각각의 3x3 depthwise convolution 뒤에 batch normalization과 ReLU 활성화 함수를 추가했다.
DeepLab v3+에서 사용된 backbone network(modified aligned Xception)는 사진 8 우측 모델이다.
Experimental Evaluation
ImageNet-1k로 pre-train된 ResNet-101 또는 modified aligned Xception을 backbone network로 사용했다.
제안된 모델의 평가 데이터로는 PASCAL VOC 2012 semantic segmentation benchmark를 사용했다. Dataset은 1464개의 train data, 1449개의 validation data, 1456개의 test data로 구성되어 있고, train data를 data augmentation을 통해 10582개의 train data를 사용했다. 평가지표로는 pixel intersection-over-union averaged across the 21 classes(mIOU)를 사용했다.
학습방법은 DeepLab v3와 같은 방법으로 진행되었고, 다음과 같다.
- Learning rate policy: 초기 learning rate=0.007이고, "poly" learning rate policy를 사용했다.
- Crop size: Atrous convolution이 큰 dilate rate에서 효과적이기 위해 큰 crop size를 사용해야 하므로 513x513 crop image를 사용했다.
- Batch normalization: batch size = 16을 사용했다.
참고) "poly" learning rate policy
1. Decoder Design Choices
Decoder의 구조를 결정하기 위해 ResNet-101을 backbone으로 사용하는 Encoder를 사용해서 실험을 진행했다.
 사진 9. Experiments for decoder design
사진 9. Experiments for decoder design
다음은 실험을 진행할 때 고려한 사항과 각 사항에 대해 실험 결과를 통해 얻은 결정이다.
- Encoder module에서 나오는 low-level feature map에 적용하는 1x1 convolution을 통해 channel을 어떻게 줄여햐 하는지 -> 48 channel로 줄인다.
- Decoder 마지막에 사용되는 3x3 convolution을 구조를 어떻게 해야할지 -> [3x3, 256] convolution을 2번 적용한다.
- Encdoer module의 어느 부분에서 나오는 low-level feature map을 사용해야 할지 -> backbone network의 conv3 feature map을 같이 사용했을 때 성능 향상이 별로 없으므로 backbone network의 conv2 feature map만 low-level feature로 사용한다.
2. ResNet-101 as Network Backbone
 사진 10. Experiments (ResNet-101)
사진 10. Experiments (ResNet-101)
해당 실험을 통해 발견한 점
- 평가시 output stride=8 즉 denser feature map을 사용하는 것과 multi-scale inputs는 성능을 향상시킨다.
- Flip은 연산 복잡도를 2배 늘리지만 아주 약간의 성능 향상만 가져온다.
- Decoder를 사용할 때 적은 연산량의 증가로 높은 성능 향상을 가져온다.
- Training시 output stride가 32인 경우, 즉 atrous convolution을 사용하지 않을 경우 computation은 줄어들지만 성능 또한 함께 떨어진다.
3. Xception as Network Backbone
 사진 11. Experiments (Xception)
사진 11. Experiments (Xception)
해당 실험을 통해 발견한 점
- Depthwise convolution을 ASPP과 Decoder module에 적용하면 성능은 비슷하게 유지하면서 연산을 줄여준다.
- 추가 pre-train한 모델을 사용할 때 성능이 향상된다.
참고) pre-train된 모델을 사용할 때, 위 사진에서 MS는 MS-COCO dataset을 이용해 DeepLab v3+ 모델 전체를 사전학습한 것이고, JFT는 ImageNet-1k와 JFT-300M dataset 모두를 이용해 backbone network를 사전학습한 것이다.
 사진 12. Qualitative results
사진 12. Qualitative results
 사진 14. model performance
사진 14. model performance
위의 사진14를 통해 DeepLab v3+가 sota 성능을 보여준다는 것을 알 수 있다.
4. Improvement along Object Boundaries
 사진 13. Evaluate Decoder
사진 13. Evaluate Decoder
위의 사진13을 통해 Decoder를 사용한 모델이 Bilinear upsample 모델보다 성능이 더 좋고, 객체의 경계선을 더 잘 포착하는 것을 확인할 수 있다.
5. Experimental Results on Cityscapes
 사진 14. Evaluate on Cityscapes dataset
사진 14. Evaluate on Cityscapes dataset
해당 실험을 통행 발견한 점
- Backbone network를 깊은 모델을 사용할 때 성능이 향상된다.
- Cityscapes dataset은 PASCAL VOC 2012 dataset과 다르게 low-level image feature를 사용하지 않을 때 성능이 더 향상된다.
- DeepLab v3+가 다른 모델들 보다 좋은 성능을 보인다.
Conclusion
DeepLab v3+ 모델은 DeepLab v3의 encoder와 간단하지만 효과적인 decoder를 사용했다. 또한 atrous convolution을 적용해 컴퓨팅 자원에 따라 임의의 해상도의 encoder feature를 추출할 수 있게 했다.
DeepLab v3+는 모델 제안 당시 PASCAL VOC 2012와 Cityscapes dataset에서 새로운 state-of-the-art의 성능을 보여줬다.
References
DeepLab v3+ 논문: Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
DeepLab v3 논문: Rethinking Atrous Convolution for Semantic Image Segmentation
DeepLab v2 논문: https://arxiv.org/abs/1606.00915
DeepLab v3+ pytorch implementation(non-official): https://github.com/jfzhang95/pytorch-deeplab-xception
DeepLab v3 pytorch tutorial:https://pytorch.org/hub/pytorch_vision_deeplabv3_resnet101/
참고한 블로그 및 유튜브
https://medium.com/hyunjulie/2%ED%8E%B8-%EB%91%90-%EC%A0%91%EA%B7%BC%EC%9D%98-%EC%A0%91%EC%A0%90-deeplab-v3-ef7316d4209d
https://www.youtube.com/watch?v=TjHR9Z9iNLA
https://m.blog.naver.com/laonple/221000648527
해당 글에 사용된 이미지 중 출처를 따로 표기하지 않은 이미지는 DeepLab v3+논문과 DeepLab v3 논문에 있는 이미지 입니다.

2개의 댓글

Really thorough breakdown of DeepLab v3+ — the clarity on semantic segmentation and encoder-decoder architecture was especially helpful. It’s interesting how precision and structure play a big role across different fields, whether in AI models or even app frameworks like https://3pattiblues.pk/
Great breakdown of DeepLab v3+ — I appreciate how you explained the encoder-decoder structure and its impact on segmentation accuracy. It’s fascinating how optimization plays a key role across different fields, from AI models to even app development like https://3patti-blue.pk/