
FxTS
FxTS는 TS,JS 기반 유틸리티 라이브러리로, 다양한 함수형 프로그래밍 도구를 제공받을 수 있다.
FxTS GitHub 페이지에 따르면, 다음 개념들을 기반으로 메서드를 제공한다.
- 지연 평가 (Lazy Evalution)
- 동시성 처리 (Handling Concurrent Requests)
- 타입 추론 (Type Inference)
- 반복 프로토콜 준수 (Follow iteration protocols Iterable / AsyncIterable)
기본 개념
지연 평가
지연 평가는 데이터를 필요로 하는 순간에만 연산을 수행하는 방식으로, 데이터 처리의 효율성을 극대화할 수 있다. 아래는 즉시 평가 방식과 지연 평가 방식에 대한 설명이다.
const original = [1, 2, 3, 4, 5]
const result = original
.map((elem) => elem + 10) // [11, 12, 13, 14, 15]
.filter((elem) => elem % 2 === 0) // [12, 14]위 코드는 JavaScript의 고차함수를 사용하여 배열의 모든 원소에 10을 더한 뒤, 그 결과가 짝수인 원소만 추려낸다. 이에 대한 비효율적인 동작에 대해 다음과 같이 정리해봤다.
즉시 평가 중 비효율적인 동작
-
중간 배열 생성
- map 호출 시 [11, 12, 13, 14, 15]라는 새로운 배열이 생성되고, 이 배열이 메모리에 저장된다.
- filter 호출 시 [12, 14]라는 또 다른 배열이 생성된다.
-
불필요한 배열 순회
- 입력 배열을 두 번 순회(map, filter 각각 한 번씩)하므로, 연산 시간이 증가한다.
-
대규모 데이터 처리의 비효율성
- 데이터 크기가 커질수록, 메모리 사용량과 처리 시간이 선형적으로 증가하게 된다.
FxTS 를 활용한 지연 평가
아래는 FxTS 라이브러리를 사용하여 지연 평가 방식을 적용한 리펙토링 코드이다.
import { pipe, map, filter, toArray } from "@fxts/core";
const original = [1, 2, 3, 4, 5];
const result = pipe(
original,
map((elem) => elem + 10), // 계산 방법만 정의, 즉시 실행 X
filter((elem) => elem % 2 === 0), // 계산 방법만 정의, 즉시 실행 X
toArray // 최종적으로 배열을 생성하며 연산 수행
);-
연산 정의
- map과 filter는 데이터를 즉시 처리하지 않고, 각각의 연산을 수행할 계산 방식만 정의한다.
-
최종 연산 수행
- toArray가 호출될 때 비로소 데이터를 순회하며 연산을 수행한다.
- 데이터는 한 번만 순회하며 필요한 연산을 즉시 적용한다.
-
중간 결과를 저장 ❌
- map과 filter 사이에 별도의 중간 배열이 생성되지 않는다.
평가 메서드
지연된 연산을 실제로 실행하여 결과를 생성하는 메서드이다.
- toArray(): 모든 연산이 실행되어 최종 배열을 생성한다.
- reduce(): 모든 요소를 하나의 값으로 집계한 결과를 반환한다.
- consume(): 결과의 반환 없이, 각 요소에 대해 특정 작업을 수행한다.
정리
지연 평가는 데이터를 한 번에 처리하지 않고, 필요한 순간에 필요한 만큼만 연산을 수행하는 방식이다. FxTS와 같은 라이브러리는 지연 평가를 통해 대규모 데이터 처리 시 메모리와 연산 시간의 효율성을 극대화할 수 있다.
동시성 처리
동시성 처리 는 여러 작업을 동시에 수행할 수 있도록 하여 데이터 처리의 속도와 효율성을 높이는 기법이다. FxTS는 비동기 데이터 처리와 동시성 제어를 쉽게 구현할 수 있는 메서드를 제공한다.
아래의 코드를 통해 동시성 처리가 없는 방식과 FxTS를 활용한 동시성 처리 방식을 비교해 보자.
동시성 처리를 하지 않은 경우
const fetchData = async (id: number) => {
return new Promise((resolve) => {
return setTimeout(() => {
return resolve(`${id}: Math.random()`), 1000)
}
}
}
const ids = [1, 2, 3, 4, 5];
const fetchAll = async () => {
const results = [];
for (const id of ids) {
const response = await fetchData(id); // 각 요청이 순차적으로 처리됨
results.push(response);
}
return results;
};각 ID에 대한 데이터를 가져오는 예시 코드이다.
fetchAll()은 ids 배열을 순회하며 각 ID에 대해 fetchData를 호출하고, 그 결과를 results 배열에 저장한다. 이는 동시성 처리가 되지 않았음으로 다음의 비효율을 야기한다.
- 순차적 요청 처리
- 각 fetchData 호출이 완료된 후 다음 호출이 이루어지므로 총 처리 시간이 요청 수에 비례하여 증가한다.
- 비효율적인 자원 사용
- 모든 요청이 순차적으로 실행되기 때문에 CPU와 네트워크 자원의 병렬 활용이 불가능하다.
FxTS를 활용한 동시성 처리
FxTS는 concurrent() 메서드를 사용하여 비동기 작업의 동시 실행을 제어할 수 있다.
concurrent()비동기 작업의 동시 실행을 제어할 수는 메서드이다.
구체적으로, concurrent(n) 을 사용하면 최대 n개의 비동기 작업이 동시에 실행되도록 제어할 수 있다.
아래는 동시성 처리를 적용한 예시이다.
import { pipe, toAsync, map, concurrent, toArray } from "@fxts/core";
const fetchData = async (id: number) => {
return new Promise((resolve) => {
return setTimeout(() => {
return resolve(`${id}: Math.random()`), 1000)
}
}
}
const ids = [1, 2, 3, 4, 5]
const fetchAll = async () => {
const results = await pipe(
toAsync(ids), // 비동기 데이터로 변환
map(fetchData), // 각 ID에 대해 비동기 작업 수행
concurrent(2), // 최대 2개의 요청을 동시에 처리
toArray // 최종 결과를 배열로 반환
);
return results
};
fetchAll().then(console.log);동시성 처리 결과
-
작업 처리 시간 개선
- 이전 코드에서는 5초가 걸렸지만, 동시성 처리를 통해 요청 시간이 약 3초로 줄어든다.
-
동시 요청 제어
concurrent를 사용하여, 최대 2개의 요청이 동시에 실행되도록 제어.- 시스템 성능에 맞게 최적의 동시 작업 개수를 설정 가능.
- 네트워크 대기 시간을 병렬로 처리하므로 CPU 및 네트워크 자원을 더 효율적으로 활용.
정리
동시성 처리는 여러 작업을 병렬로 실행하여 처리 속도와 자원 활용도를 최적화하는 방식이다.
타입 추론

FxTS 공식문서 의 내용 중, 타입 추론 관련 요약글이다. TypeScript의 타입 시스템과 통합되도록 설계됐기 때문에, 각 메서드의 입력과 출력 타입이 자동으로 적절히 추론된다.
🤔 내 생각...
FxTS 의 장점인가?
타입 추론은 Typescript 의 장점 중 하나이다.
FxTS 메서드를 사용 여부와 관련없이 Typescript 로 코드를 작성했다면, 그 장점을 이미 누리고 있지 않나 싶다.
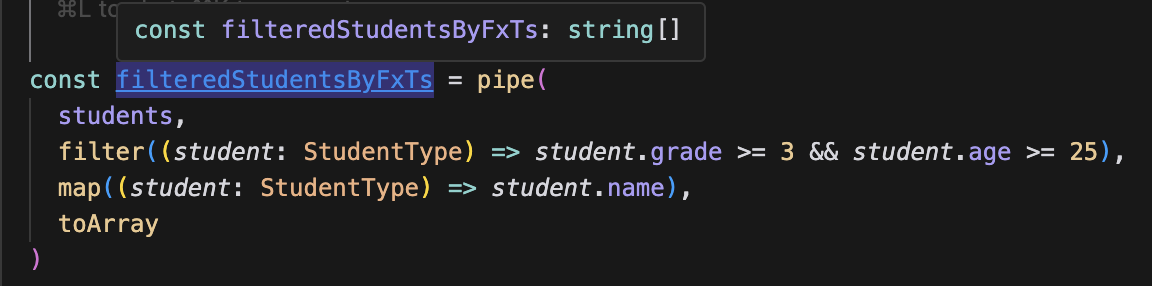
type StudentType = { age: number name: string grade: 1 | 2 | 3 | 4 }; const students: StudentType[] = [ { age: 27, name: 'jeff', grade: 4 }, { age: 26, name: 'riel', grade: 2 }, { age: 25, name: 'kei', grade: 1 }, { age: 24, name: 'wendy', grade: 3 }, { age: 23, name: 'alverick', grade: 1 }, { age: 23, name: 'jane', grade: 3 }, ];위의 구성에서, (age >= 25) && (grade >= 3) 인 학생의 이름만 추출하는 코드를 작성해보았다. FxTS 를 쓰나 안쓰나 타입추론은 정상적으로 이뤄진다.
기본 고차함수를 활용해 필터링한 경우,
FxTS 메서드를 활용해 필터링한 경우,
공식문서의 타입추론 관련 설명은 Typescript 시스템과 잘 통합된다는 걸 알리려는 설명인 듯 하다.

사용법
Installation
NPM
npm install @fxts/coreYarn
yarn add @fxts/core주요 메서드
pipe()
pipe는 여러 개의 함수를 연결하여 하나의 함수처럼 사용할 수 있게 해주는 기능을 제공한다.
pipe는 주로 동기적인 데이터 변환에 사용되며, 함수의 체인을 통해 데이터 흐름을 명확하게 표현한다.
import { pipe } from '@fxts/core';
const result = pipe(
100,
(num) => Math.pow(num, 2),
(num) => num / 2,
(num) => num + 2,
(num) => num * 2
);
console.log(result); // 10004fx()
fx는 Iterable 및 AsyncIterable 데이터를 메서드 체이닝 방식으로 처리할 수 있다.
해당 메서드의 주요 특징으로는 지연 평가(lazy evaluation) 를 사용하여 메모리 사용을 최적화하고, 불필요한 계산을 피할 수 있다.
Iterable 및 AsyncIterable 데이터
Iterable 데이터
- 반복 가능한 객체
- Array, String, Set, Map 등은 순회가 가능한 객체는 기본적으로 Iterable을 구현하고 있다.
// Iterable 데이터 처리 예시
import { fx } from '@fxts/core';
const result = fx([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
.filter((num) => num % 2 === 0)
.map((num) => Math.pow(num, 2))
.reduce((acc, val) => acc + val, 0);
console.log(result); // 120AsyncIterable
- 비동기적으로 반복 가능한 객체
// AsyncIterable 데이터 처리 예시
import { fx, toAsync } from '@fxts/core';
async function fetchAllData(urls: string[]) {
const results = await fx(toAsync(urls))
.map(async (url) => {
const response = await fetch(url);
return response.json()
})
.toArray()
return results
}
const response = fetchAllData(['https://api.example.com/data1', 'https://api.example.com/data2']);소감..
함수의 직관적으로 조립(?)하여 사용할 수 있다는 점에서 함수형 프로그래밍의 장점을 적절히 활용할 수 있는 라이브러리인 것 같다. 개인적으로 함수의 크기를 키우지 않고도 직관적인 로직을 제시할 수 있기 때문에, 함수의 계층화하는 것에 도움 것이라고 생각했다.
지연평가 라는 개념을 FxTS 를 공부하며 처음 알게 되었는데, 단순한 구현이라도 성능을 높힐 수 있는 솔류션이 있다는 것이 신기했다. 앞으로 단순한 순수함수를 정의하더라도 이러한 개념을 주의하는 편이 좋을 것 같다.
