얼마 전 이력서를 작성하고, 경험 많은 개발자 님께 이력서 피드백을 받던 도중, 다음 문장은 어떤 의도썼는지 질문을 받았다.
"코드의 가독성을 높이고 유지보수를 용이하게 하기 위해 명확하고 간결한 코드 작성을 지향합니다."
나는 지금껏, React 기반의 프로젝트를 하면서 크고 작은 일반함수를 여럿 만들었고, 그 과정에서 나름의 함수 작성 기준이 세울 수 있었다. 그런 의미에서, 내가 작성한 위의 저 한 문장은, 규칙에 근거해 코드의 가독성 및 재사용성을 고려하는 신입임을 어필(?)하기 위한 목적으로 적은 것이다.
가장 최근에 Frontend 동아리를 함께 했던 동기 중에선, 코드를 가장 잘근잘근(?) 분리시키고 싶었던 것 같다. 아래는 어떤 프로젝트의 중, 객체의
깊은 복사와얕은 복사기능을 함수로 만든 것을 보고 한 팀원과 대화했던 내용이다.
deepCopy()는 성능 이슈로 잘 사용하지 않을 것 같고,shallowCopy()는 고작 한 줄의 코드 분리한 건데 굳이 따로 선언할 필요가 있는지에 대한 댓글이 있었다.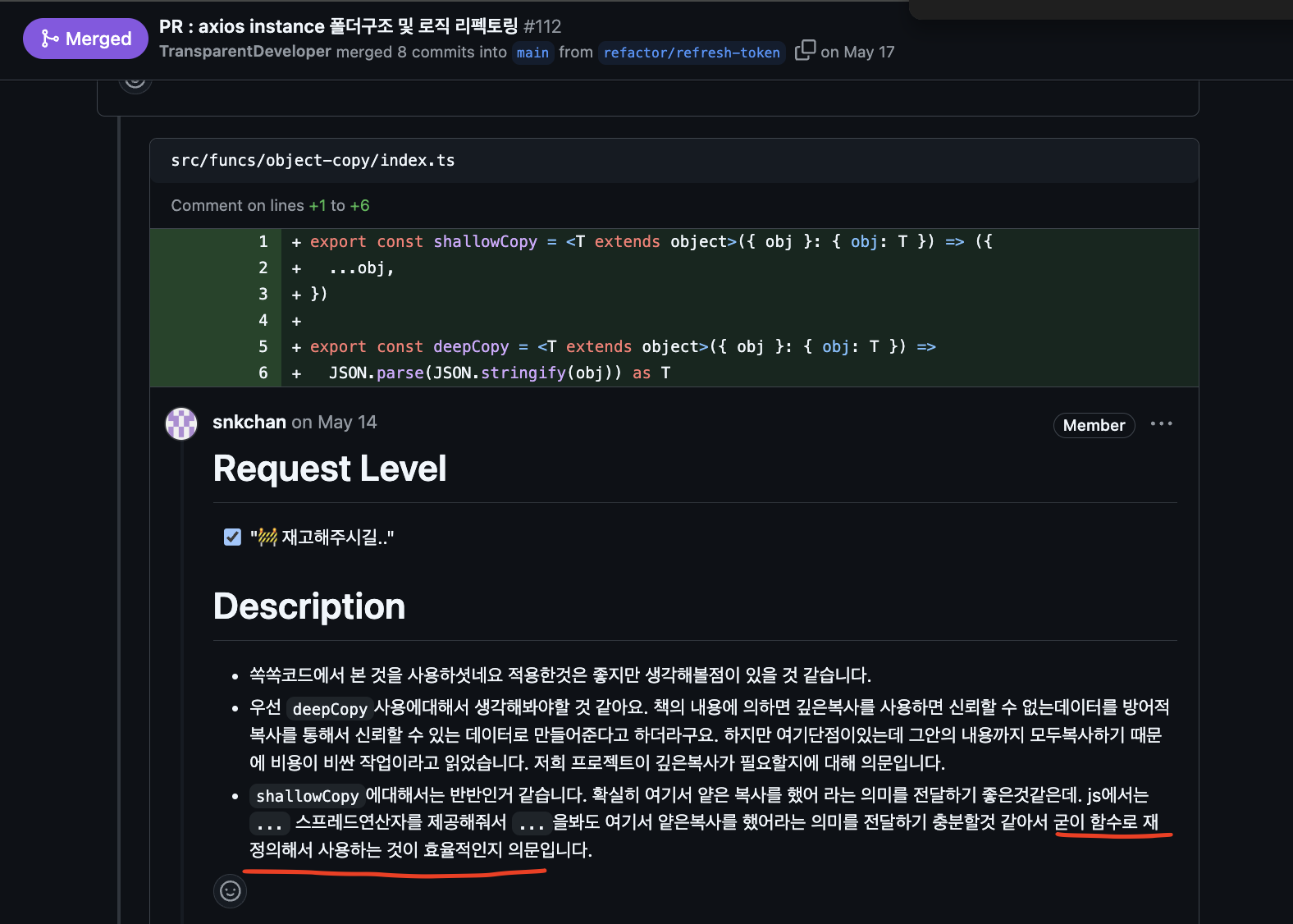
이에 대한 나의 답변은 "연산자를 활용한 구현 내용을 감추려했다." 이다.
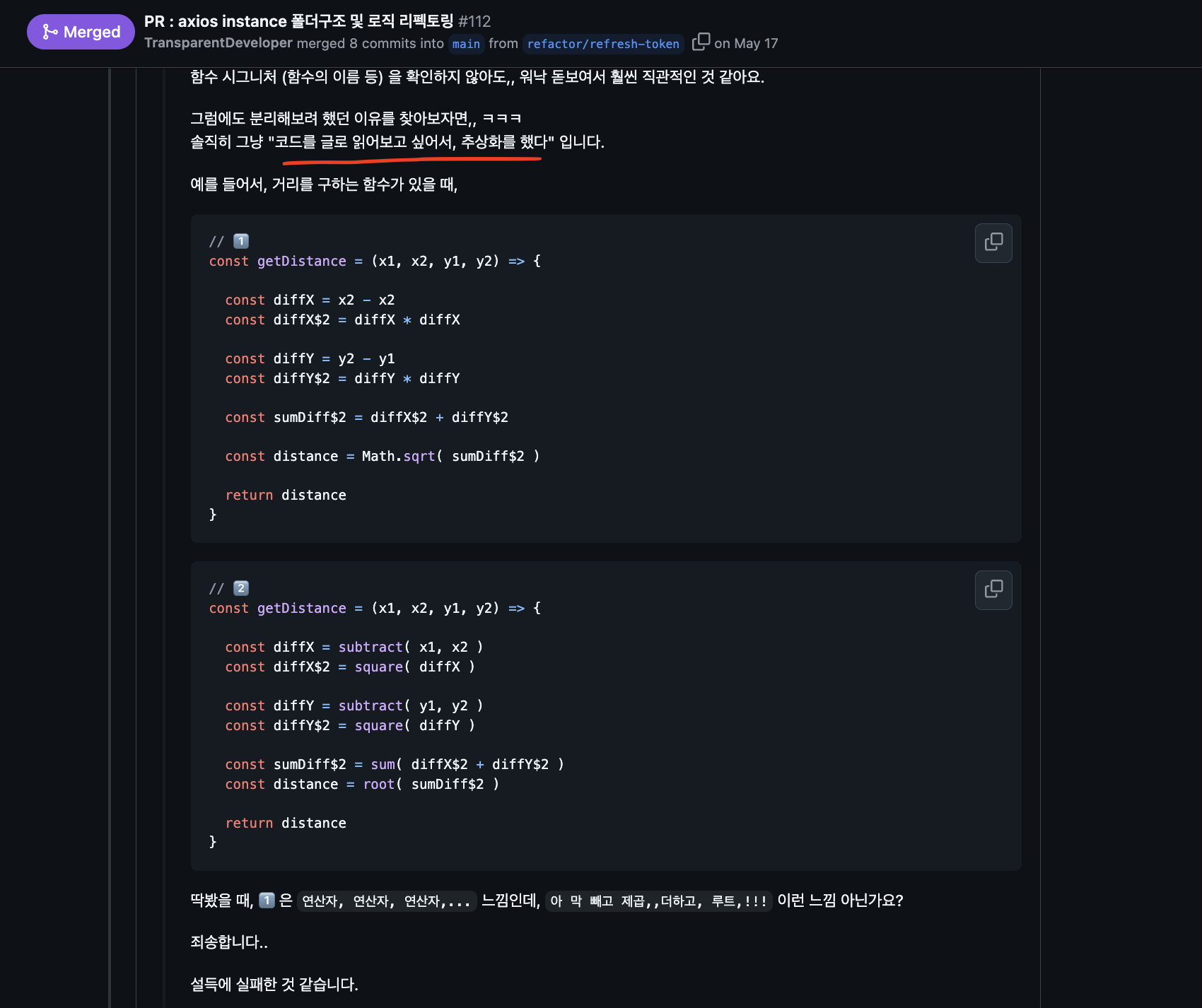
이번 포스트에서는 함수 설계와 관련한 용어("유지보수성" 등) 및 개념을 정리하고, 나의 함수 관리 노하우를 공유할 것이다.
이 글에서 언급하는 함수는 함수형 컴포넌트 혹은 그 내부에 선언된 이벤트나 상태 처리를 위한 함수가 아니다.
코드 가독성 등을 높히기 위해, 따로 분리된 코드 조각(순수 함수)를 의미한다.개념정리
① 유지보수성
개념
- 소프트웨어가 변경, 확장, 수정될 때 이를 쉽게 처리할 수 있는 능력을 의미한다.
- 잘 구조화된 코드와 설계는 유지보수를 용이하게 해준다.
- 주석을 남기거나, 일관성 있는 naming 규칙을 적용함으로서 유지보수성이 개선될 수 있다.
예시
type Person = {
id: string
name: string
age: number
height: number
weight: number
}
// 👎 Good Case
const sortPersonsByHeight = (persons: Person[]) => {
persons.sort((person1, person2) => person1.height - person2.height)
// 👍 Good Case
const sortPersonsByNumberProperty = (
persons: Person[],
sortBy: keyof Person,
) => {
// number 타입의 속성이 아닐 경우를 위한, 타입가드
if (typeof sortBy !== 'number')
throw new Error('number 타입의 속성만 입력할 수 있습니다.')
return persons.sort(
(person1, person2) => person1[sortBy] - person2[sortBy],
)
}
주의할 점
- 모듈 간의 의존성을 최소화해야 한다.
- 재사용성이 높은 코드는 유지보수가 용이할 수 있지만, 과도하게 재사용성을 추구하다 보면, 코드가 너무 일반화되어 유지보수성이 떨어질 수 있다.
② 재사용성
개념
- 재사용성은 동일한 코드나 컴포넌트를 여러 곳에서 다시 사용할 수 있는 능력을 의미한다.
- 재사용성 높은 코드는 코드의 반복을 줄이고, 효율성과 일관성을 높여준다.
- 범용적이고 유연한 설계는 코드의 재사용성을 극대화할 수 있다.
예시
// 👎 Bad Case
const calculateAreaOfSquare = (sideLength: number) => {
return sideLength * sideLength
}
// 👍 Good Case
const calculateArea = (shape: { type: 'square'; side: number } | { type: 'circle'; radius: number }) => {
if (shape.type === 'square') {
return shape.side * shape.side
} else if (shape.type === 'circle') {
return Math.PI * shape.radius * shape.radius
}
}주의할 점
- 재사용 가능한 코드는 범용적이어야 하지만, 과도하게 일반화하면 코드의 복잡성이 높아질 수 있다.
- 재사용성과 유지보수성 사이의 균형을 고려하여 설계해야 하며, 재사용성을 높이기 위해서 코드가 지나치게 복잡해지지 않도록 주의해야 한다.
③ 순수함수
개념
- 순수함수는 동일한 입력이 주어지면 항상 동일한 출력을 반환하고, 함수 외부의 상태를 변경하지 않는 함수이다.
- 순수함수는 부수효과(side effects)가 없어, 예측 가능하고 테스트하기 쉬운 코드를 작성할 수 있다.
- 외부 상태나 전역 변수를 참조하거나 변경하지 않도록 주의해야 한다.
예시
// 👎 Bad Case (외부 상태 변경)
let counter = 0
const incrementCounter = () => {
return counter++
}
// 👍 Good Case (순수함수)
const add = (a: number, b: number) => {
return a + b
}주의할 점
- 순수함수는 외부 상태에 의존하거나 변경하지 않아야 하며, 함수의 출력이 입력에 의해서만 결정되어야 한다.
- 외부 자원(I/O, 전역 변수 등)에 의존하는 함수는 순수함수가 아니므로, 이러한 의존성을 제거하거나 캡슐화하는 것이 중요하다.
④ 함수형 프로그래밍
개념
- 함수형 프로그래밍은 데이터를 함수의 조합으로 처리하고, 상태 변이와 부수효과를 최소화하는 프로그래밍 패러다임이다.
- 순수함수, 불변성, 고차 함수 등을 활용하여 코드의 안정성과 예측 가능성을 높인다.
- 상태를 변경하지 않고 데이터를 변형해 나가는 방식이 주된 특징이다.
주의할 점
- 함수형 프로그래밍에서는 불변성을 유지해야 하며, 상태를 변경하지 않도록 해야 한다.
- 불변성을 유지하기 위한 대가로 성능 저하가 발생할 수 있으므로, 성능이 중요한 부분에서는 주의 깊게 설계해야 한다.
⑤ 선언적 프로그래밍
개념
- 선언적 프로그래밍은 어떻게가 아닌 무엇을 해결할지를 기술하는 방식이다. 목표를 명확히 하고, 세부적인 실행 방법은 시스템에 맡긴다.
- 명령형 프로그래밍과 달리, 선언적 프로그래밍은 문제 해결에 필요한 절차를 나열하지 않고, 원하는 결과를 정의하는 데 집중한다.
- 선언적 코드는 더 읽기 쉽고, 복잡한 로직을 간결하게 표현할 수 있다.
예시
// 👎 Bad Case (명령형 프로그래밍)
let activeUsers = []
for (let i = 0; i < users.length; i++) {
if (users[i].active) {
activeUsers.push(users[i])
}
}
// 👍 Good Case (선언적 프로그래밍)
const activeUsers = users.filter(user => user.active)주의할 점
- 선언적 프로그래밍은 복잡한 로직도 간결하게 표현할 수 있지만, 지나치게 추상화할 경우 가독성이 떨어질 수 있다.
- 로직이 단순해질수록 유지보수성이 좋아지지만, 지나친 추상화로 인해 디버깅이 어려워질 수 있으므로 주의해야 한다.
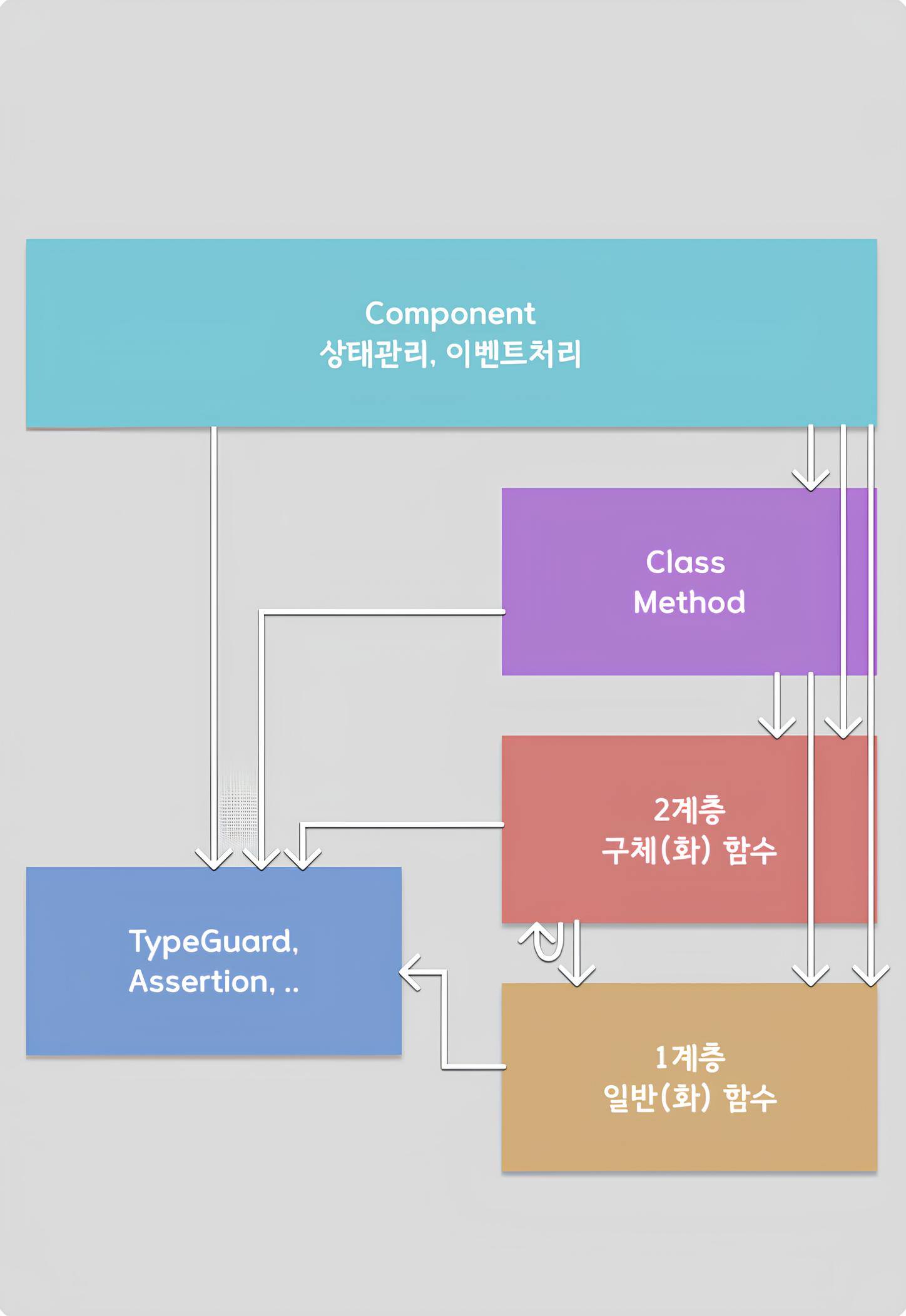
유틸리티 함수 관리
지금부터는 내 개인적인 함수 관리방법에 대해 소개해보려 한다.
나는 기본적으로 두 개의 추상적인 계층으로 분리해 함수를 관리한다.
첫째는 일반(화) 함수 계층이고,
두번째 계층에서는 구체(화) 함수 를 관리한다.
다음 책에서 영향을 많이 받았다.
(실전에 바로 적용해 보기 좋은 책이니 꼭 추천한다.)
유틸리티 함수를 계층화하여 관리하라는 내용도 포함되어있다.
물론 책에서 나왔던 원칙을 그래도 적용해 계층구조를 나누는 건 상당히 어렵다. (실제로 시도해보았지만 실패했다.)하지만 책의 원칙 대신, 나만의 관리 기준을 세울 때 해당 내용을 참고했다.
첫번째 계층 - 일반(화)함수
일반(화) 함수는 다음과 같은 조건이 충족되도록 구현한다.
구현 특징
⓵. 특정 프로젝트에 의존하지 않는다.
⓶. 특정 컴포넌트에 의존하지 않는다.
⓷. 특정 타입에 의존하지 않는다.
- 입력/반환 타입에는 최대한 원시타입을 사용한다. (number, string, boolean 등)
⓸. 특정 함수에 의존하지 않는다.
- 프로그래밍 기본 언어에서 제공하는 기본 메서드를 활용한다.
- 동일 계층의 함수라도 서로 간의 호출을 막는다.
⓹. 핵심적인 구현 내용은 1~3줄 이내로 짧게 완성한다.
재사용성이 매우 높은 함수만을 관리한다.
다음과 같이, 별도의 파일로 분리하여 함수를 선언한다.
1계층 예시 - ①
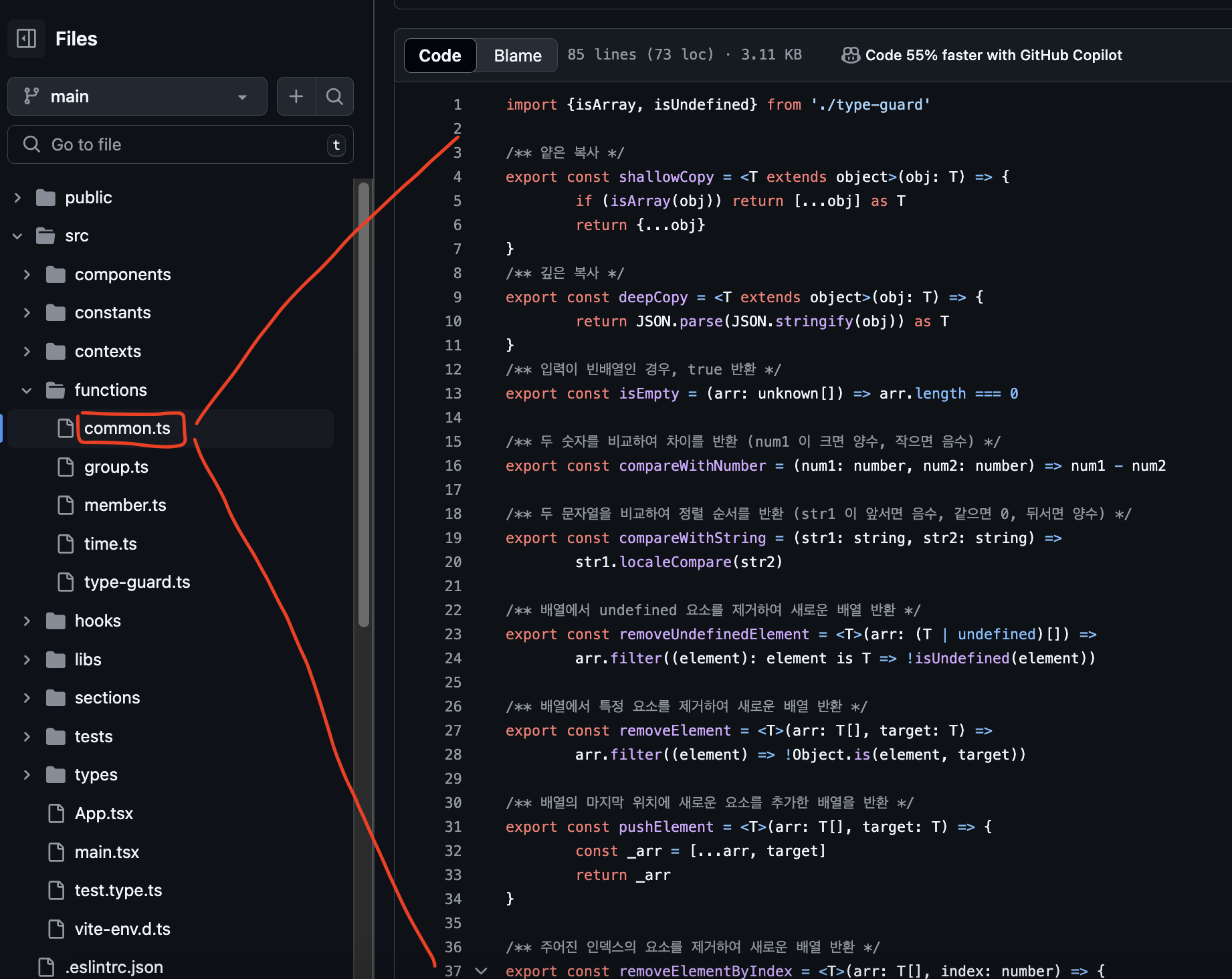
JavaScript Utility Library (Loadash 등)
사실 loadash, underscore 등의 라이브러리에서는 위 특징과 일치하는 일반함수를 충분히 많이 제공해준다. 하지만 나는 매우 사소한 이유로 내가 직접 만들어 쓰는 걸 더 선호한다.
일단 추상화된 함수명이 마음에 들지 않은 경우가 있다. 그리고 구현내용이 한 두 줄 정도로 간단하기 때문에 필요한 때마다 만들어 써도 상관없다.
("이 부분은 추상화되면 좋겠는데?" 라고 판단이 섰을 때 관련 메서드가 있는지 찾는 것보다, 한 두 줄 적어내는 게 훨씬 빠르다.)
물론 구현의 정확성이나 함수의 입력에 대한 검증 이 제대로 이뤄졌는지 계속 의심해야하는 단점도 있다. 또한 협업인원이 많아졌을 때, 일반함수가 우후죽순 만들어 질텐데, 공유하기도 힘들 것 같고 구현 내용이 중복될 가능성도 클 것이다.
이와 같은 경우라면, 일반함수를 만드는 인원을 제한하거나, 차라리 "loadash 에서 제공하는 것만 씁시다." 라고 정하면 좋을 것 같다.
두번째 계층 - 구체(화)함수
특정 프로젝트에서만 활용할 수 있는 구체적인 로직을 관리한다.
(비즈니스 규칙이나 개발자 간의 약속 또한 코드로 구현할 수 있다면 이 계층에서 관리한다.)
구현 특징
⓵. 컴포넌트의 로직의 일부를 대체할 수 있어야한다.
- 최소 기능 단위로 대체되어야 한다.
⓶. 구체적인 타입과 모델을 다룬다.
⓷. 1계층 함수의 호출이 가능하다.
⓸. 동일 계층 함수간의 의존이 생길 수 있다.
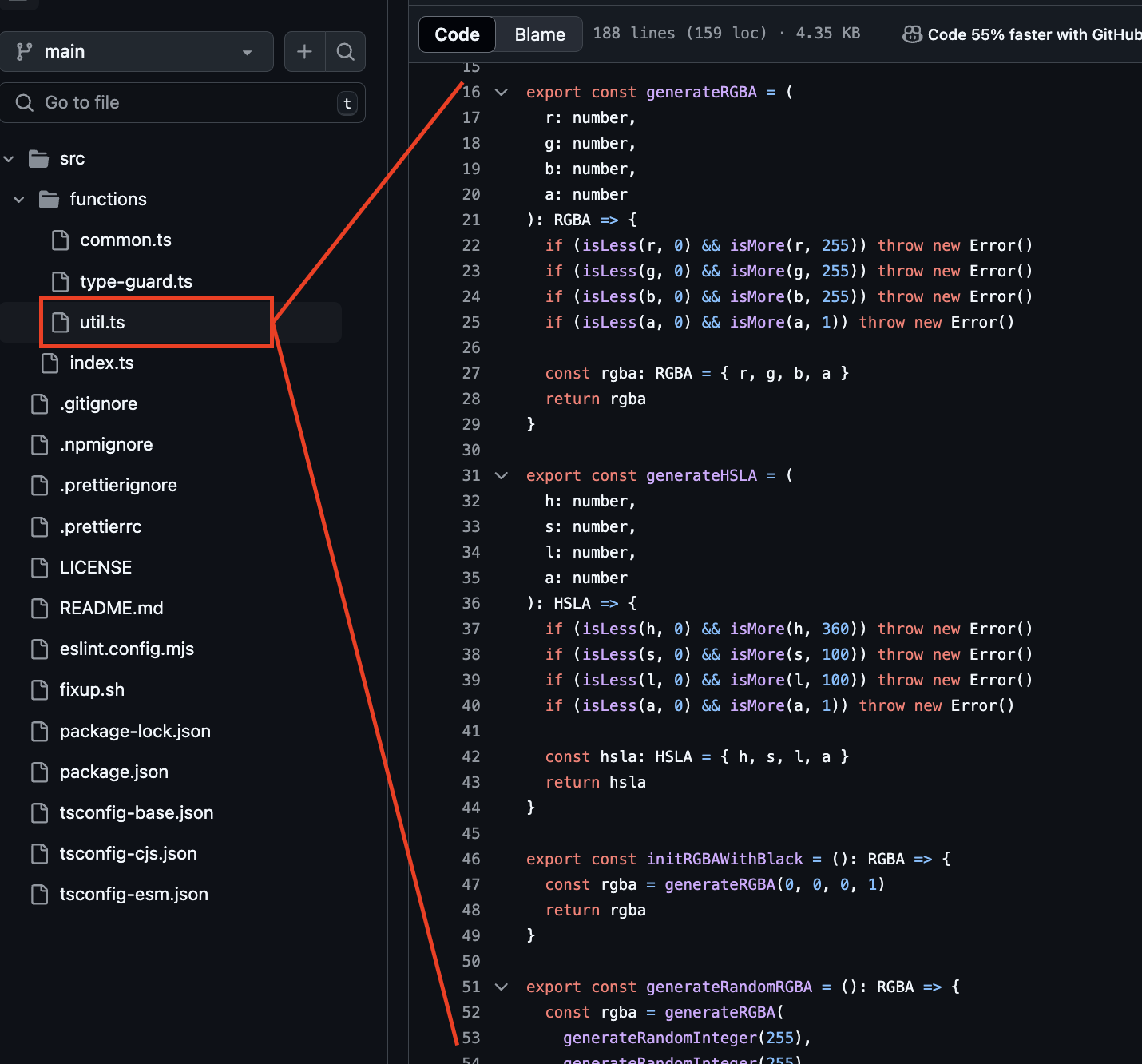
[2계층 예시 - ①]
[2계층 예시 - ②]
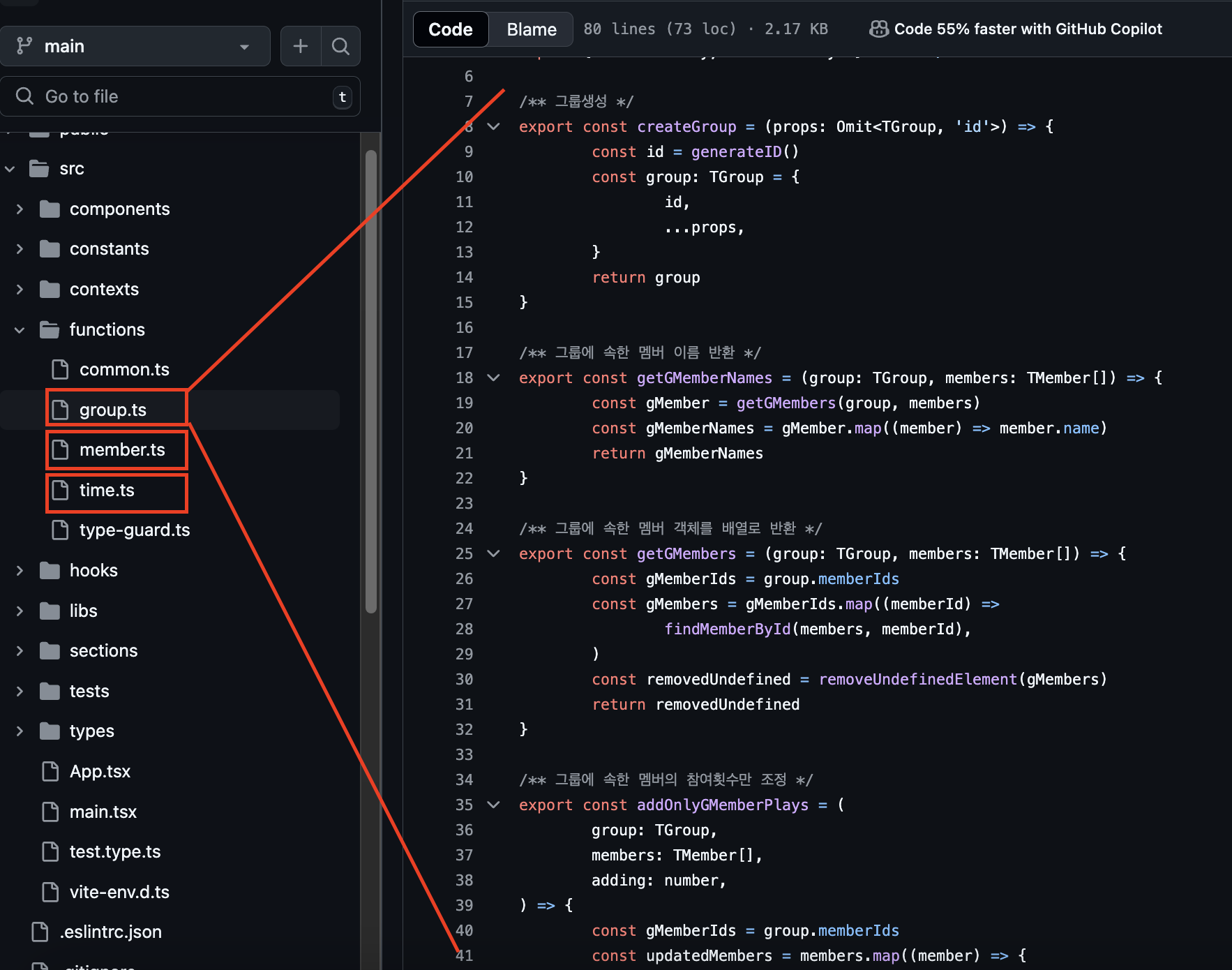
특별히 강조하고 싶은 규칙 중 하나는 4번("동일 계층 함수간의 의존이 생길 수 있다.") 이다.
(위에서 언급했던 책의 내용에서도 소개되는 내용) 일반적으로 호출 구조의 단순화와 관리의 편의성을 위해 동일 계층 간의 호출을 권장하지 않는다. 나 또한 처음에는 2계층 또한 같은 계층의 함수를 호출하지 못해야 한다고 처음엔 생각했다
하지만, 이미 충분히 추상화가 이뤄진 코드를 활용해서 더 구체적인 함수를 만들어야할 경우를 많이 마주했다.
이러한 동일 계층 간의 호출이 싫다면, 계층을 더 쌓음으로써 구체화 단계를 나누는 것도 좋다.
다만, Frontend 의 유틸리티 함수를 관리함에 많은 계층이 필요하다면, 일반적으로 Backend (server) 단에서 데이터가 충분히 정제되지 못했음을 의미할 것이다.
그런 의미에서 아직까지 나는 2개 계층 간의 호출 규칙만 세워 두었다.
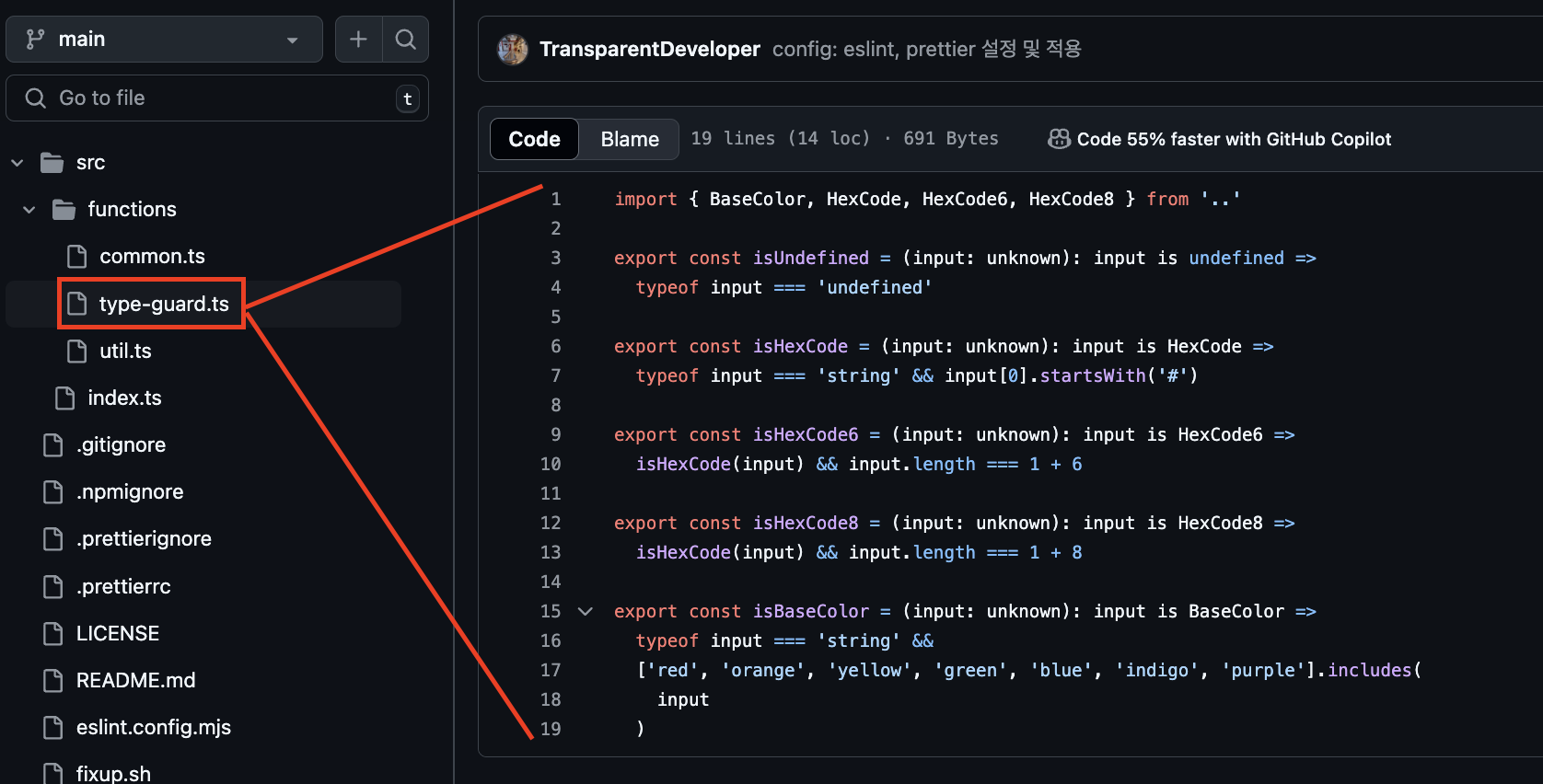
(추가) type-guard, Assertion
한가지 더 보태자면, 타입가드나 assertion (함수의 입력에 대한 유효성) 함수는 위의 어떤 계층에도 속하지 않도록 따로 관리한다.
타입가드나 입력 유효성 검사 로직은 함수(의 안전성)를 위한 함수인 만큼, 계층에 상관없이 어디서든 호출되는 편이 좋다고 생각하기 때문이다.
요약 (이미지)
위의 내용을 한번에 정리 & 도식화한 이미지이다.