파이썬 딥러닝 파이토치책으로 파이토치 공부하기 #1
autograde란?
pytorch에서 제공하는 autograd는 신경망 학습을 지원하는 자동 미분 엔진이다. 쉽게 말해 back propagation을 이용해 파라미터를 업데이트하는 작업을 쉽게 구현할 수 있게 해주는 것이다.
실습
간단한 딥러닝 모델을 만들고 방정식 내에 존재하는 파라미터를 어떻게 업데이트 할 수 있는지 보자.
1. pytorch import 및 사용할 GPU 선택
import torch
device = torch.device('cuda:1' if torch.cuda.is_available() else 'cpu')
torch.cuda.set_device(device)
print("Current cuda decive: ", torch.cuda.current_device())torch를 import한다. 현재 1번 GPU를 사용할 수 있으면 1번을 사용하고, 그렇지 않으면 cpu를 사용하도록 한다.
2. 파라미터 설정
batch_size = 64
input_size = 1000
hidden_size = 100
output_size = 103. 변수 설정
x
x = torch.randn(batch_size, input_size, device=device, dtype = torch.float, requires_grad = False)torch.randn은 평균이 0, 표준편차가 1인 정규분포에서 샘플링한 값으로, 데이터를 만든다는 것을 의미한다. batch_size, input_size에 따라 데이터의 모양 달라진다.
x는 input으로 이용되기 때문에 gradient를 계산할 필요가 없다. 따라서 requires_grade = False로 한다.
y
y = torch.randn(batch_size, output_size, device=device, dtype=torch.float, requires_grad=False) output 설정한다. batch_size 만큼 결과값 필요하다. output과의 오차를 계산하기 위해 output의 크기를 10으로 설정한다.
w1
w1 = torch.randn(input_size, hidden_size, device = device, dtype = torch.float,requires_grad = True) 업데이트 할 파라미터 값을 설정한다. input data의 크기는 1000이며 이것과 행렬곱을 하므로 다음 행의 값이 1000이어야 한다. 행렬곱을 이용해 100 크기의 데이터를 생성하기 위해 (1000, 100)크기의 데이터를 생성한다. x, y와 다르게 gradient를 계산해야 하므로 requires_grad = True로 설정
w2
w2 = torch.randn(hidden_size,output_size, device = device,dtype = torch.float,requires_grad = True) w1과 x를 행렬 곱한 결과에 계산할 수 있는 데이터여야 한다. w1과 x의 행렬 곲을 한 결과는 (1,100)이며 (100, 10)행렬을 통해 output을 계산할 수 있도록 한다. backpropagation을 통해 업데이트해야하는 대상이므로 requires_grad = True로 설정한다.
4. 학습
learning_rate = 1e-6
for i in range(1, 501):
y_pred = x.mm(w1).clamp(min = 0).mm(w2)
loss = (y_pred - y).pow(2).sum() # 제곱차의 합
if i % 100 == 0:
print("Iteration: ", i, "\t", "Loss: ", loss.item())
loss.backward()
with torch.no_grad():
w1 -= learning_rate * w1.grad
w2 -= learning_rate * w2.grad
w1.grad.zero_()
w2.grad.zero_()clamp는 값의 상한선과 하한선을 설정한다. 위 코드에서는 min=0으로 설정했으므로 0보다 작은 값이 발생하면 그 값을 0으로 바꿔준다. 활성화함수 ReLU와 같은 역할을 한다.
pow는 지수를 의미한다. (2)이므로 제곱을 의미한다.
backward는 계산된 loss 값에 대해 사용하면 각 파라미터 값에 대해 gradient를 계산하고 이를 통해 back propagation을 진행한다는 것을 의미한다.
with절은 코드가 실행되는 시점에서 gradient값을 고정한다는 의미이다.
grad.zero()는 gradient값을 0으로 설정하는 코드다. 다음 backpropagation을 진행할 때 gradient 값을 loss.backward()를 통해 새로 계산하기 때문에 0으로 설정한다.
위 코드를 실행해보면 다음과 같은 결과가 출력된다.
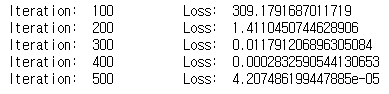
500번의 반복을 실행하면서 loss 값이 줄어드는 것을 확인할 수 있다. 이는 input이 w1과 w2를 통해 계산된 결과값과 y값이 점점 비슷해진다는 것을 의미하며, 반대로 y값과 비슷한 output을 계산할 수 있도록 w1과 w2가 계산된다는 것을 알 수 있다.
전체 코드는 아래에서 확인 가능하다.
https://github.com/sksmslhy/TIL/blob/master/pytorch/autograd.ipynb
