[논문 리뷰] A Systematic Survey of Prompt Engineering on Vision-Language Foundation Models
논문 리뷰
목록 보기
9/11

link: https://arxiv.org/abs/2307.12980
arXiv 2023
0. Abstract
- prompt는 수동으로 생성하거나 vector representation으로 자동 생성 가능
- prompt engineering을 사용하면 모델 param을 업데이트하지 않고 프롬프트에만 기반하여 예측 수행할 수 있으며 pretrained large model을 실제 작업에 더 쉽게 적용 가능
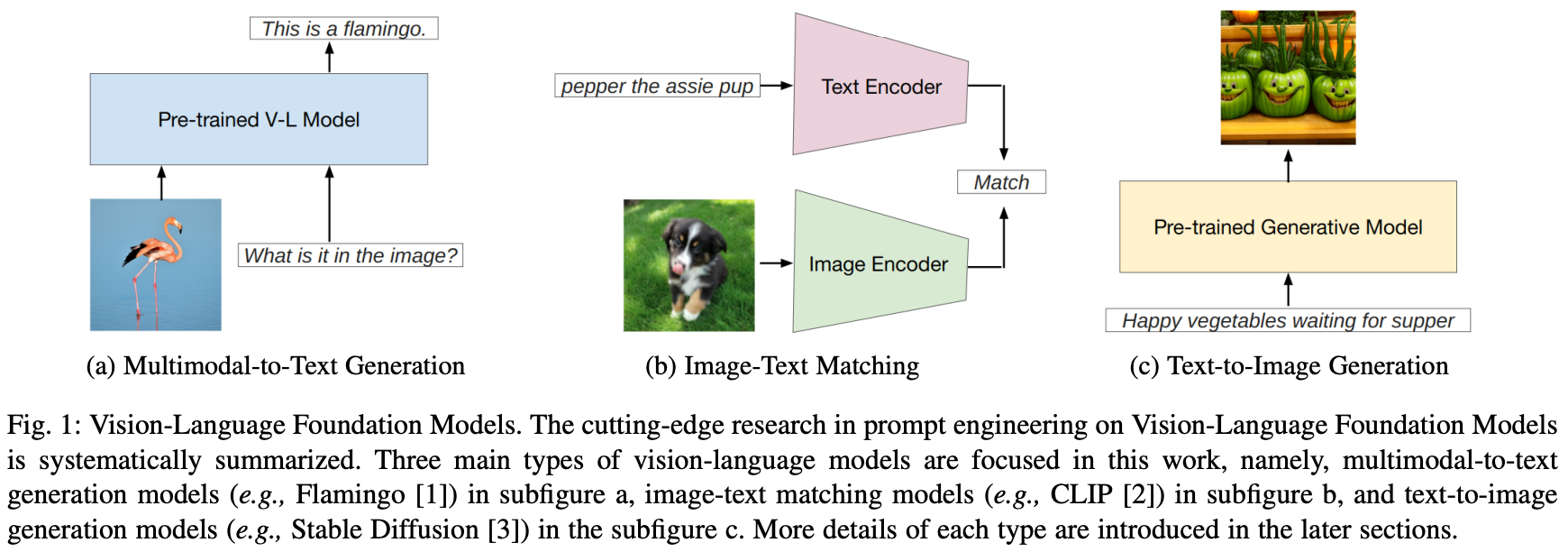
- 이 논문은 세가지 유형의 vision language model에 대해 다루며 vision language model, language model, vision model에 대한 prompt간의 공통점과 차이점 논의
- multimodal-to-text generation models(Flamingo), image-text matching models(CLIP), and text-to-image generation models(Stable Diffusion)
1. INTRODUCTION
- prompt engineering은 작업별 hint로 모델의 input을 강화하여 large pretrained model을 새로운 task에 적용하는 접근 방식
- model input은 수동 또는 자동으로 생성된 자연어 instruction, 자동으로 생성된 vector representation이 될 수 있는 prompt라는 추가 부분에 의해 강화됨
- natural language instruction: discrete prompts / hard prompt
- vector representation: continuous prompts / sof prompt
- ML model을 처음부터 훈련하는 경우 전체 param을 조정하거나 pretrained model을 완전히 또는 일부 fine-tuning 해야 함
- 기존 패러다임과 비교하여 prompt engineering의 장점
- pre-trained model을 새로운 작업에 적용하기 위해선 레이블 지정된 데이터가 필요한데, 이 때 fine tuning을 위한 인간의 supervision 및 계산에 사용되는 리소스 줄어듦
- pre-trained model이 param을 업데이트 하지 않고 프롬프트에만 기반하여 새로운 작업에 대한 예측 수행 가능 → 동일한 모델로 대규모 downstream task를
- prompt engineering은 NLP에서 처음 연구되었고 이후 CV, Vision-Language model(VLM)에서도 주목받음
- 아직 VML에 대한 prompt engineering은 NLP 분야에 비해 덜 연구됨
- 이 논문에서는 template의 가독성을 기준으로 두 가지로 promtp를 구별함
- hard prompt 하위 범주
- task instruction, incontext learning, retrieval-based prompting, chain-of-thought prompting
- soft prompt: gradient 기반 방법을 사용하여 fine-tune 할 수 있는 continuous vector
- hard prompt 하위 범주
- 이 논문은 주로 모델의 architecture를 유지하는 prompt 방법에 대해 초점을 맞추고 있으며 encoder-decoder 관점에서 기존 prompt engineering 접근 방식을 분류(즉 prompt가 encoder/decoder에 추가되는)
2. TAXONOMY
2.1 Terminology
- prompt 동작을 안내하거나 특정 작업을 수행하는 데 도움이 되도록 모델에 제공되는 추가 정보 또는 힌트
- prompting method 모델의 행동을 안내하거나 모델 성능 향상을 위해 프롬프트를 입력에 통합하는 데 사용되는 approach
- multimodal-to-text generation multimodal input data에서 textual descriptions나 narratives를 생성
- image-text maching 이미지와 텍스트 설명 사이의 의미론적 관계 또는 alignment를 설정
- text-to-image generation 텍스트 설명에서 시각적 이미지 생성
- in-context learning 추가 training 없이도 새로운 task를 해결하기 위해 관련 context 내에 모델에 instruction이나 demonstration을 제공하여 유도하는 방법
- chain-of-thought multistep 문제를 해결하고 궁극적인 해결책에 도달하도록 안내하는 일련의 중간 작업을 생성하도록 모델에 지시하여 추론 기술을 향상시키는 프롬프트 방법
2.2 Notations

3. PROMPTING MODEL IN MULTIMODAL-TO-TEXT
GENERATION
3.1 Preliminaries of Multimodal-to-Text Generation
- LLM(Large Language Model)은 NLP 분야에서 인상적인 capability를 보여 visual modality를 LLM에 통합하는 방법을 모색함
- 생성 기반 VLM은 일반적으로 text feature, visual feature, fusion module 로 구성됨
- Text Feature
- VLM 초기 연구에선 일반적으로 BERT에 의해 도입된 preprocessing 기술 사용
- 최근에는 더 다양한 입력을 받기 위해 새로운 special token을 도입
- 추가 이미지 분류 토큰
- < image > </ image > 사용해 인코딩된 이미지 임베딩의 시작과 끝 나타내고, < s > </ s > 사용해 시퀀스의 시작과 끝 표시
- Visual Feature
- embedding sequence로 일관된 representation을 얻기 위해 이미지 x는 sequence of embedding vectors로 변환됨
- 이미지로 전달되는 정보를 정확히 표현하는 것은 downstream task에서 중요하지만 어려운 문제
- 이전에는 CNN 구조가 image feature extraction에 흔히 사용되었음(R-CNN) → 이미지의 중요한 부분 간과할 수 있음
- PFA, Famingo: ResNet 활용하여 더 넓은 context 고려해 전체 이미지의 정보를 인코딩
- SimVLM, PaLl, MAGMA, BLIP2: 더 강력한 feature extraction 위해 ViT 구조 사용
- Fusion Module
- text, image embedding을 통합해 joint representation을 만드는 데 중요한 역할
- Visual Question Answering (VQA)
- fusion module 사용하면 답변 생성 능력 향상됨
- 생성 기반 VLM에서 fusion module 적용하는 두 가지 방법
- multi-modal fusion module인 encoder-decoder
- VL-T5, SimVLM, OFA, PaLI: 두 양식을 동시에 결합하는 joint representation을 생성하는 데 중점
- multi-modal fusion module인 decoder-only
- Frozen, Flamingo, MAGMA: 초기 단계에서 명시적으로 joint representation을 생성하지 않고 decoding stage에서 시각 정보와 텍스트 정보를 직접 결합함
- PICa: 이미지를 텍스트로 취급하고 GPT-3와 같은 사전훈련된 언어모델을 활용해 순수 텍스트 입력에 기초하여 출력 생성
- BLIP2: decoder 기반 OPT와 encoder-decoder 기반의 FlanT5의 2개의 별개 모듈의 융합을 고려
- multi-modal fusion module인 encoder-decoder
3.2 Multimodal-Text Prompting Methods
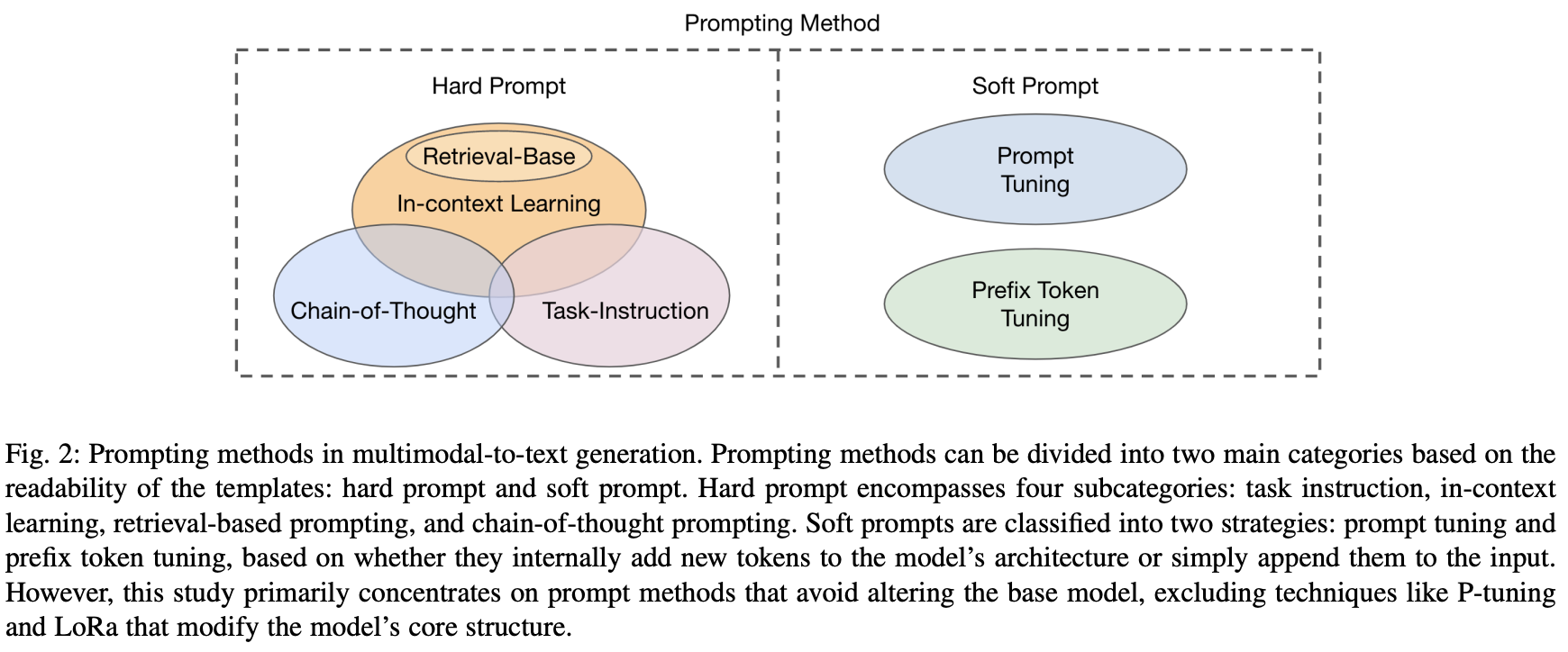
- Fig. 2. : prompt method의 분류
3.2.1 Hard prompt
- hard prompt는 수동으로 만들어지고, 해석 가능한 text token이 포함됨(”A photo of” 를 추가하는 등)
- 4가지 하위 범주로 더 나뉠 수 있음
- Task Instruction Prompting
- 모델의 행동을 안내하기 위해 명시적인 task 관련 지침을 제공하는 신중하게 설계된 프롬프트
- : image x와 text t를 입력으로 받아 input representation 을 생성하는 함수
- In-context Learning
- 모델이 일련의 관련 예제 또는 프롬프트에 노출되어 제공된 상황에서 학습하고 일반화할 수 있게 하는 방법
- : 주어진 context 와 입력된 이미지 x, 텍스트 t를 통합하는 작업을 함
- 수정된 input representation 은 모델이 context에 맞는 응답을 생성하는 데 사용됨
- Retrieval-based Prompting
- 검색 기술 사용하여 프롬프트나 context를 선택하는 방법
- : 이미지 x, 텍스트 t 입력을 기반으로 적절한 프롬프트 또는 context를 수집하는 검색 방법
- 이후 검색된 context 는 모델 생성 또는 의사 결정 프로세스를 안내하는 데 사용됨
- Chain-of-Thought Prompting
- 논리적 chain 을 유지하기 위해 점진적으로 서로를 기반으로 하는 일련의 지침이나 질문을 통해 모델에 메시지를 보내는 방법
- chain의 각 프롬프트는 context를 추가하거나 초점을 좁혀 모델이 보다 일관되면서 상황에 맞는 응답을 생성할 수 있도록 함
- : 이미지 x, 텍스트 t를 입력하여응답을 생성하는 프롬프트 함수
- : 번째 프롬프트위 출력으로, ()번째 프롬프트인 의 input 역할
3.2.2 Soft Prompt
- gradient-based로 fine-tune할 수 있는 continuous vector로 특징지어짐
- 새 토큰이 모델 구조 내에 내부적으로 통합되었는지, 단순히 입력에 추가되었는지에 따라 분류됨
- Prompt Tuning
- input hint로 연속적인 vector representation을 생성
- 훈련 과정에서 모델은 특정 작업에 대한 성능 향상을 목표로 프롬프트를 구체화하는 방법을 학습 → 모델은 작업에 대한 이해를 바탕으로 효과적인 프롬프트를 동적으로 생성할 수 있음
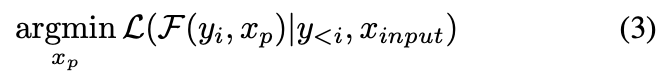
- : 프롬프트 매개변수 가 주어진 모델의 출력
- : 이전에 생성된 출력
- : 프롬프트에 따라 수정된 입력
- 모델의 출력과 원하는 출력 사이의 loss 을 최소화하는 것이 목적 - Prefix Token Tuning
- prompt tuning과 유사하게 task-specific vector가 input에 추가됨
- 그러나 이 때 vector는 모든 model layer에 삽입되면 pre-trained model의 나머지 param은 고정된 상태로 유지하면서 독립적으로 훈련 및 업데이트 될 수 있음
3.3 Advance in Prompting Techniques for VLM
- 모델은 fusion module에 따라 두가지로 나뉨
- Prompting Models with Encoder-decoder as the Fusion Module
- 초기 VLM은 transformer encoder 위에 작업별 구조를 설계하였으나 최그ㄴ엔 encoder를 fusion module로 통합하는 unified vision-language framwork가 도입됨
- VL-T5, SimVLM, OFA
- main prompting methods로 handcrafted instruction과 prompt tuning 사용
- text prefixe를 프롬프트로 활용
- ex. “vqa”, “caption”, “a photo of”
- Prompting Models with Decoder-based Fusion Module
- Frozen, BLIP2: image conditional prefix tuning을 사용
3.4 Understanding Prompting
- Dataset-specific Prefixes
- 텍스트 프롬프트의 선택은 모델 성능에 많은 영향을 미침.
- VL-T5: VQA, GQA 작업 모두에 대해 single prefix “vqa”를 추가하여 효과적으로 작업 처리
- Freezing the Language Model
- Frozen, MAGMA, Flamingo, BLIP2: 학습 중 언어 모델 고정
- 이를 통해 knowledge loss를 방지
- PFA, KOSMOS-1: language ability 손실 막기 위해 훈련 중 language-only task 작업을 추가
- In-context Learning
- Frozen: 모델이 몇 가지 예만 사용하여 새로운 단어를 시각적 범주와 연관시키고 해당 단어를 즉시 적절하게 활용할 수 있도록 하는 fast concept binding을 보여줌
- Flamingo, KOSMOS-1: image-text 쌍 대신 개별 prompt 사용하면 모델 성능을 향상시킬 수 있음을 보여줌 (다만 모델에 bias 생길 수 있음)
- Prompt Tuning
- Prompt tuning in generative multimodal models 연구
- 연구 결과 다양한 작업에 걸쳐 fine tuning보다 지속적으로 더 robustness
- 더 많은 param이 포함된 긴 프롬프트가 개선을 촉진할 수 있음을 보여줌. 그러나 지나치게 길면 성능에 오히려 악영향
- Prompt tuning in generative multimodal models 연구
3.5 Application of Prompting
- Visual Question Answering
- Visual Commonsense Reasoning
- Zero-shot Image Classification
- Image Captioning
- Chatbot
3.6 Responsible AI Considerations of Prompting
- LLM의 윤리에 관한 문제 그대로 가져감
4. PROMPTING MODEL IN IMAGE-TEXT MATCHING
4.1 Preliminary of Image-Text Matching Models
- joint multi-modal representation 획득을 ㅇ이하게 하는 새로운 패러다임 도입
- CLIP, ALIGHm ALBEF, Multi-Event CLIP: contrastive learning 기술을 활용해 image와 text에 대한 joint representation을 달성
- 훈련 데이터셋을 확장하고 모델 param을 확장하여 matching-based model은 zero-shot benchmark와 fine-tuning 시나리오를 포함한 광범위한 downstream task에 걸쳐 적응성을 보여줌
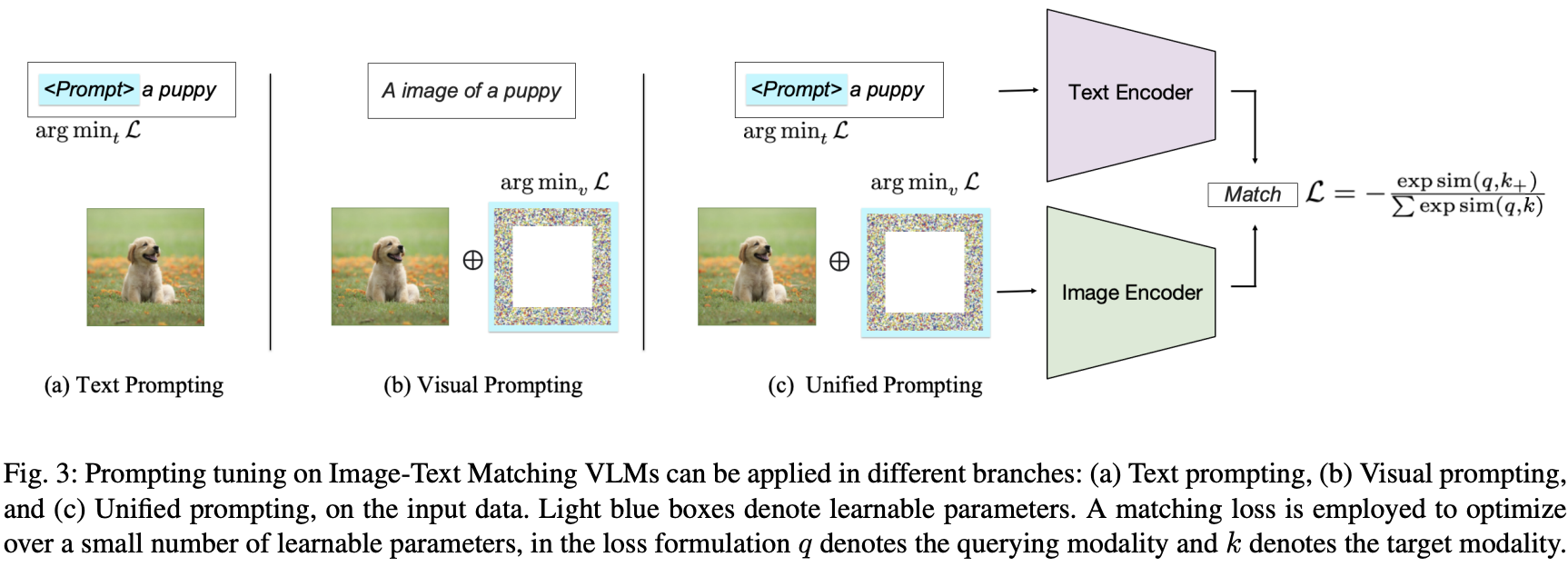
- 프롬프트 대상에 따라 기존 방법은 prompting the text encoder, prompting the visual encoder, jointly prompting both branches 세가지 범주로 분류될 수 있음
4.2 Prompting Text Encoder of VLM
- 학습 가능한 textual prompts는 supervised 방식으로 image-text 쌍에서 최적화
- 최근 연구도 레이블이 지정되지 않은 데이터를 사용하여 다른 시나리오 조사
4.2.1 Hard prompt
- 프롬프트의 도입은 대규모 사전 훈련된 언어 모델을 발견하고 활용하는 데 중추적인 역할을 함
- 텍스트 프롬프트는 수작업 텍스트 템플릿("a photo of a [CAT]")을 완화하여 모델이 명시적인 작업별 훈련 없이 특정 작업을 이해하고 응답할 수 있도록 해 모델의 유연성과 다용도성을 높임
- 여러 작업에서 zero-shot performance를 테스트하기 위해 hard prompt를 활용하기도 함
4.2.2 Soft prompt
- 설계 내에 학습 가능한 param을 통합하는 프롬프트를 말하며 세 가지 유형으로 분류됨
- Global Soft Prompt
- 해당 작업에 맞게 템플릿 토큰을 수정하는 것은 downstream task에 언어 모델을 조정하는 간단하면서도 좋은 방식임
- 전체 모델은 fine-tune 하는 것보다 비교적 작은 세트의 prompt embedding param을 학습하는 것이 더 효율적
- Group-specific Prompt
- 최근 연구 중 다양한 task나 입력 유형에 맞게 맞춤화된 soft prompt group을 사용함 → 모델이 적절한 프롬프트를 동적으로 query하고 select할 수 있음
- Instance-specific Prompt
- task-grouped prompt는 과적합 문제가 있을 수 있으며 unseen class나 novel sample에 적용하기 어려움
- 인스턴스별 프롬프트는 개별 샘플에 대한 프롬프트를 사용자 정의하는 것을 목표로 하여 보다 개인화되고 적응적인 접근 방식임 → 모델의 생성성 향상
4.3 Prompting Image Encoder of VLM
- visual prompt를 디자인하는 방식에 따라 두 가지 클래스로 분류
- Patch-wise Prompts
- learnable patches를 visual prompt로 추가하는 것은 visual cue를 VLM에 통합하는 직관적 방법
- textual soft prompt가 input token 역할을 하는 것처럼 VPT(Visual Prompt Tuning)를 도입할 수 있음
- 이러한 패치는 사전훈련된 모델을 새로운 작업에 적용하기 위해 input image와 연결됨
- 대부분의 다른 방법보다 성능 뛰어남
- Annotation Prompts
- 이미지를 직접 조작하여 명시적으로 수행할 수 있음
- CPT(Colorful Prompt Tuning)
- 이미지의 특정 영역을 시각적 프롬프트로 색상화하는 데 중점을 둠
- 색상 신호 통합 → 시각적 맥락 더 잘 이해
4.4 Unified Prompting on VLM
- vision과 language 각각 분야에서 prompt engineering 발전하면서 joint prompting도 발전함
- 두 도메인 모두의 프롬프트 활용해 matching-based VLM을 향상시키는 것이 목표
- 시각적 프롬프트와 텍스트 프롬프트가 서로 독립적인지 여부에 따라 두 가지 유형으로 분류
- Coupled Unified Prompting
- 두 가지 프롬프트를 함께 최적화하기 위해 작은 신경망을 사용하였고 그 결과 unified prompting이 unimodal prompting을 능가하였음
- Decoupled Unified Prompting
- 두 양식 모두에서 프롬프트 엔지니어링의 이점 활용
- multimodal understanding에 보다 효과적
4.5 Application of Prompting
- Image Classification
- Text Classification
- Object Detection
- Visual Relation Detection
- Semantic Segmentation
- Domain Adaptation
- Continual Learning
- Domain Generalization
4.6 Responsible AI Considerations of Prompting
- Adversarial Robustness of Prompt
- Backdoor Attack of Prompt Learning
- Fairness and Bias
5. PROMPTING MODEL IN TEXT-IMAGE GENERATION
5.1 Preliminary of Text-Image Generation Models
- diffusion model(DM)에 초점을 맞춰 text-image generation의 prompting model을 이해하는 데 필요한 예비 사항에 대한 개요 제공
- DRAW, GAN, VAE등 이미지 생성 모델은 소규모 데이터로 훈련되었으며 일반화가 부족함
- 이후 DALL-E, Parti 등 대규모 데이터셋에 의해 작동되는 autoregressive methods가 제안되었으며 놀라운 zero-shot generation 능력을 보여줌
- 최근 DM은 text-image generation에서 SOTA 대열에 합류
5.2 Understanding Prompting
- 여러 관점에서 text-to-image의 prompt desing을 소개
- Semantic Prompt Design
- 간단한 형용사는 출력에 미묘하게 영향을 주지만 명사는 새로운 내용을 더 효과적으로 소개함
- 아티스트 이름을 사용하면 원본과 크게 다른 이미지가 생성되는 경향이 있으며 lighting phrase를 사용하면 이미지의 내용과 분위기 극적으로 바뀜
- 명확한 noun-based statements는 이미지 생성 품질 향상시킴
- Diversify Generation with Prompt
- 최근에는 다양한 프롬프트 수식어를 실험하고 있음
- Complex Control of Synthesis Results
- synthesized image generation은 일반적으로 diffusion model의 확률론적 특성에 내재된 무작위성과 noise injection으로 인해 일관성이 없음
- 최근에는 복잡하게 제어 가능한 생성 영역에서 새로운 연구 등장
- 프롬프트 기반 제어: modified area를 제한하는 사용자 제공 mask로 제어 가능성의 한계를 극복
5.3 Application of Prompting
5.3.1 Generating Synthetic Training Data
5.3.2 Generating Data in Target Domain
5.3.3 Prompt-centered Complex Task
5.4 Responsible AI Considerations of Prompting
- Adversarial Robustness of Prompt
- Backdoor Attack of Prompt Learning
- Fairness and Bias
- Privacy
6. PROMPTING VLM VS. UNI-MODAL MODELS
6.1 Prompting in Natural Language Processing
- textual language model의 prompt engineering에 대한 기존 연구를 요약
- 초기 연구에서는 사전 훈련된 LM이 예측을 설명하기 위해 채울 수 있는 자연어 템플릿을 설계
- 프롬프트 중간 추론 단계를 추가하면 LLM의 성능이 크게 향상
- 이 접근 방식은 LLM이 프롬프트를 따르고 주어진 작업을 해결하기 위해 단계별로 생각하도록 장려
- [183] 프롬프트에서 예시 선택 및 설명 제공을 포함하여 프롬프트의 품질이 LLM의 성능에 상당한 영향을 미친다는 사실 발견
- [184] 더 많은 중간 추론 단계가 필요한 복잡한 예제 질문으로 LLM을 유도하면 높은 성능을 내면서 더 robust한 모델이 된다고 기술
- [5] LLM을 활용해 reasoning chain을 구성해 수동 작업 제거
- [6] 임베딩 레이어에 훈련 가능한 토큰을 추가하고 downstream 작업에 대한 역전파를 통해 이 토큰을 학습하는 즉각적인 튜닝 제안(soft prompt)
- task가 복잡해지며 LLM의 성능이 상당히 저하됨 → LLM을 여러 번 프롬프트하여 복잡한 작업에 대한 LLM의 성능 향상시킴
6.2 Prompting on Pure Vision Models
- prompt는 자연어 모델에서 처음으로 널리 사용되었으나 pure vision model과 image classification 등 다양한 응용에서도 프롬프트를 활용함
- 여러 연구에서 프롬프트를 vision model에 통합하는 두 가지 주요 매커니즘이 확인됨
- 프롬프트를 사전훈련된 비전 모델의 fine-tuning을 용이하게 하는 adaptation method
- 프롬프트를 모델 사전 훈련과 inference 모두에서 역할을 하는 module로 활용
- 사전 훈련된 vision model은 성능을 크게 향상시켰지만 크기도 커져 대부분의 사용자가 training, fine tuning 수행할 수 없게 됨
- 따라서 사전 훈련된 모델을 parameterefficient 방식으로 특정 task에 적용하는 것이 중요 → treated prompting을 adaptation method로 다룸
- [10]: single visual prompt를 사용하여 고정된 대규모 vision model을 새로운 task에 적용
- VQA(Visual Query Tuning): 사전 훈련된 transformer를 downstream task에 적용하는 동시에 백본을 고정한 상태로 유지하여 사전 훈련된 모델의 intermediate feature를 활용하여 보다 정확한 예측을 가능하게 함
- PGN(Prompt Generation Network)
- 도메인 적응을 용이하게 하기 위해 입력에 종속적인 시각적 프롬프트를 생성
- 토큰 라이브러리에서 프롬프트 벡터를 선택하기 위한 확률 분포를 학습하는 경량 신경망으로 구성됨
- Painter
- 주어진 task prompt를 기반으로 다양한 비전 작업을 수행할 수 있는 일반 모델
- semantic segmentation, instance segmentation, depth estimation, keypoint detection, denoising, detailing, image enhancement 등의 작업 뿐만 아니라 open category object segmentation과 같은 out-of-domain 작업도 수행 가능
7. CHALLENGES AND OPPORTUNITIES
- Prompting Model in Multimodal-to-Text Generation
- visual, textual modalitiy 외에도 다른 형식을 통합하는 것도 가능함
- Microsoft의 KOSMOS와 Meta AI의 IMAGEBIND
- generative multimodal-to-text pre-trained model을 위한 prompt tuning은 아직 대부분 연구되지 않음
- 도전적인 신기술을 채택함에도 불구하고 모델이 학습하는 근본적인 메커니즘과 구체적인 기여는 대부분 연구되지 않음 → 이러한 요인을 더 깊이 이해하는 것은 중요
- Prompting Model in Image-Text Matching
- matching loss에 의해 촉발된 pre-trained encoder가 downstream task의 adaptation을 위해 널리 사용되었지만, pre-trained encoder에 대한 visual prompting 탐색은 상대적으로 덜 연구됨
- unified prompt가 어떻게 두 branch의 성능을 향상시킬 수 있는지에 대한 조사도 덜 연구됨
- Prompting Model in Text-Image Generation
- text-to-other generation model 분야에서 중요한 과제 중 하나는 text-to-other model에 대한 의존성임
- 특히 Text-to-Video(T2V) 모델과 Text-to-Image(T2I) 모델의 경우 T2I 모델에 의존적임
- 예로 T2I diffusion model의 input control map의 불일치로 인해 결과적으로 생성된 비디오 및 3D 개체에 오류가 발생할 수 있음
- visual prompting을 T2I, T2V, T2-#d diffusion model에 통합하는 방법으로 문제 해결할 수 있음
- 이 방식은 이미지의 특정 영역에 더 많은 주의를 기울일 수 있어 생성된 출력의 세부 사항과 정확성 향상됨
- text-to-other generation model 분야에서 중요한 과제 중 하나는 text-to-other model에 대한 의존성임
- Generalizing Prompting Methods from Unimodal to Multimodal
- 6장에서 multi-modality research에 동기 부여할 수 있는 pure vision과 pure language model 모두에서 prompt engineering 적용에 대해 논의하였음
- ChatGPT: pure language model을 instruction-tuning methods와 결합하여 탄생
- multimodal domain에서 Constitutional AI를 연구하는 것은 여전히 열려있는 문제
- multimodal model에서 상황에 맞는 프롬프트 채택하기
- large unimodal language model은 gradient update 없이 텍스트 프롬프트에서 작업에 대한 여러 demonstraction을 제공하여 특정 새 작업을 처리할 수 있음
- Responsible AI Considerations of Prompting
- 윤리적 문제에 관한 연구
- 공정한 프롬프트를 통해 투명성을 유지하고, 제어 가능한 output을 생성하는 것도 중요함
- Relationship between Prompts on Different VLMs
- 최근 연구는 multimodal-to-text, image-to-text와 text-to-image 모델에 의해 학습된 개념 간의 관계를 연구
- 두 유형의 모델이 서로를 완전히 이해할 순 없으나 일부 개념은 공유
- 다양한 유형의 모델에 대한 prompt 간의 관계는 향후 조사되어야 함
- 대부분의 프롬프트는 transformer 기반 모델에서 제안되므로 모델 간 관계 외에도 프롬프트와 모델 구조 간의 상호작용에 대한 연구도 필요함
8. CONCLUSION
- 사전 훈련된 vision-language 모델에서의 프롬프트 엔지니어링에 대한 연구를 소개하고, 프롬프트를 활용하여 vision-language 모델의 성능을 향상시킬 수 있는 다양한 방법을 소개
- 프롬프트 엔지니어링은 레이블 데이터를 줄이고 실제 응용 프로그램에서 vision-language 모델의 배치를 가속화하는 데 유용하며, 이 연구는 이러한 가능성을 탐구
- vision-language 모델의 성능을 개선하는 데 프롬프트 엔지니어링을 활용하는 방법을 제시하고, 이 분야의 미래 연구 방향을 제안
