CVPR 2022에 발표된 논문
0. Abstract
- CoOp(Context Optimization)
- pre-trained vision language model을 적용하기 위해 vision 영역에 prompt learning 개념을 도입
- prompt의 context words를 학습 가능한 벡터 세트로 변환하며, 학습을 위해 label이 지정된 몇 개의 이미지만 있으면 집중적으로 조정된 수동 prompt에 비해 큰 improvements 달성
- 본 연구에서는 CoOp의 문제 다룸
- 학습된 context는 동일한 데이터 셋 내에서 보이지 않는 더 큰 class로 일반화할 수 없음 → 훈련 중 관찰된 기본 클래스에 과적합됨을 시사
- 이를 해결하기 위해 lightweight neural network를 추가로 학습해 각 이미지에 대해 input conditional token(vector)를 생성하는 Conditional Context Optimization(CoCoOp) 제안
- 학습된 context는 동일한 데이터 셋 내에서 보이지 않는 더 큰 class로 일반화할 수 없음 → 훈련 중 관찰된 기본 클래스에 과적합됨을 시사
- CoCoOp
- dynamic prompt: 각 instance에 adaption되므로 class shift에 덜 민감
- 학습하지 않은 class에 대해 CoOp보다 더 잘 일반화되며, 단일 데이터셋 넘어서는 유망한 transferability 보여줌
- 더 강력한 domain generalization
1. Introduction
-
large-scale vision-language pretraining에 대한 최근 연구의 핵심 디자인은 visual concepts를 모델링하는 방법에 있음
- label 구분되는 기존 supervised learning에서 각 카테고리는 동일한 카테고리를 포함하는 이미지와의 거리를 최소화하도록 학습된 무작위로 초기화된 가중치 벡터와 연결됨 → 폐쇄형 visual concept에 중점을 두고 모델을 사전 정의된 카테고리 목록으로 제한하여 훈련되지 않은 카테고리에 대해서는 확장 불가
- label 구분되는 기존 supervised learning에서 각 카테고리는 동일한 카테고리를 포함하는 이미지와의 거리를 최소화하도록 학습된 무작위로 초기화된 가중치 벡터와 연결됨 → 폐쇄형 visual concept에 중점을 두고 모델을 사전 정의된 카테고리 목록으로 제한하여 훈련되지 않은 카테고리에 대해서는 확장 불가
-
vision language model
- CLIP, ALIGN 등: classification weights는 prompt를 통해 매개변수화된 text encoder(transformer 등)에 의해 정반대로 생성됨
- discrete label과 비교했을 때 vision language model의 supervision은 자연어에서 나오므로 시각적 개념을 광범위하게 탐색 가능하며 transferable representation을 학습하는 데 효과적
-
CLIP
- 모델 크기가 매우 커 전체 모델을 fine-tuning하는 것은 비실용적
- → prompt 도입: 성능 향상에 효과적
- 그러나 prompt engineering은 시행착오가 필요해 비효육적이며 최적의 prompt 보장 X
-
CoOp
- 학습용으로 레이블이 지정된 이미지 몇 개만 사용하여 수동 prompt에 비해 크게 개선됨
- 문제점: 학습되지 않은 클래스로 일반화 불가능(Figure 1)
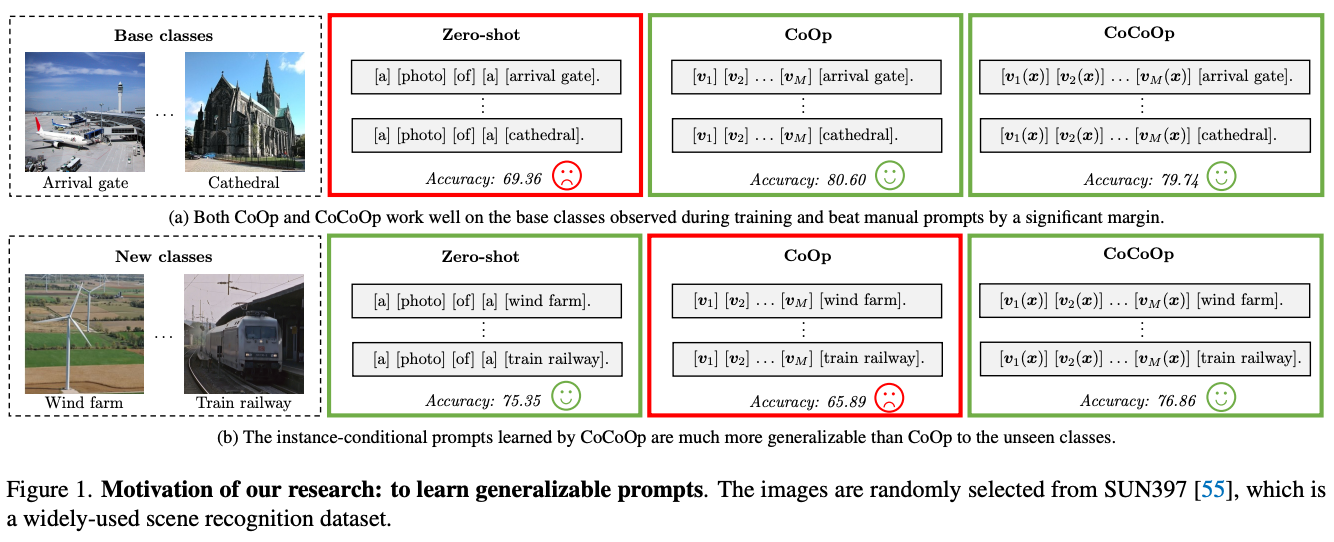
- 본 연구에서는 CoOp의 일반화 문제가 static한 설계때문이라고 지적
-
본 연구
- conditional prompt learning 도입: 학습 후 고정시키는 대신 각 input instance(image)에 따라 조건이 지정된 prompt를 만드는 것
- 각 이미지에 대해 학습 가능한 context vector와 결합된 input conditional token(vector)를 생성하기 위해 lightweight neural network를 추가 학습하여 CoOp를 확장
2. Related Work
- Vision-Language Models
- 중점 연구 사항: joint embedding space
- 최근 연구: 2개의 encoder 결합
- 최근 성공적인 모델 구조
- transformer
- contrastive representation learning
- web-scale training dataset
- Prompt Learning
- NLP domain에서 먼저 시작됨
- BERT, GPT: pre-trained language model 주어지면 모델에서 작업은 fill-in-the-black로 공식화됨
- AutoPrompt: vocabulary에서 가장 큰 변화를 일으키는 토큰을 선택하는 그라데이션 기반 접근 방식[44]
- Zero-Shot Learning(ZSL)
- 목표: 유사한 영역(새로운 것)을 인식하는 것. 이 때, 기본 클래스로만 훈련하여 클래스 생성
- 가장 일반적인 접근 방식: attributes 또는 word embedding과 같은 auxiliary information을 기반으로 semantic space를 학습하는 것
- CoCoOp는 기존 ZSL 방법과 달리 prompt 기반의 완전히 다른 기술 사용
3. Methodology
- CLIP과 CoOp에 대한 간략한 리뷰 진행
- 이후 기술적 세부 사항과 근거 제시
3.1. Reviews of CLIP and CoOp
- Contrastive Language-Image Pre-training(CLIP)
- 2개의 encoder(image용 ResNet/ViT, text용 Transformer)로 구성됨
- 훈련 중 joint embedding 학습 위해 contrastive loss 사용하여 일치하는 쌍은 cosine similarity 최대화 되도록, 일치하지 않는 쌍은 최소화되도록 학습
- Context Optimization (CoOp)
- pre-trained vision-language model을 downstream application에 더 잘 적용하기 위해 prompt engineering의 비효율성 극복하기 위해 제안됨
- 데이터에서 end to end 학습이 가능한 연속 벡터를 사용하여 각 context token을 모델링하는 것이 핵심 아이디어
- 기본 CLIP 모델은 학습 과정에서 고정되어 있으며 CLIP을 downstream image recognition dataset에 적용하기 위해 cross-entropy loss를 학습 목표로 사용
3.2. CoCoOp: Conditional Context Optimization
-
CoOp: downstream dataset에서 몇 개의 label이 지정된 이미지만으로 context vector를 훈련할 수 있는 데이터 효율적인 접근 방식이지만 일반화에 제약이 있음
-
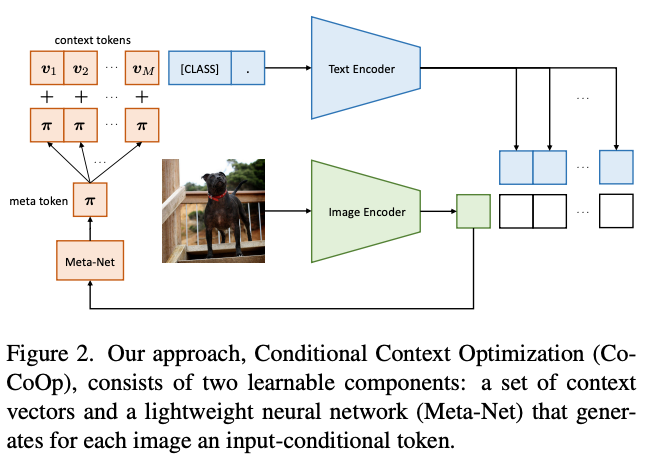
CoCoOp
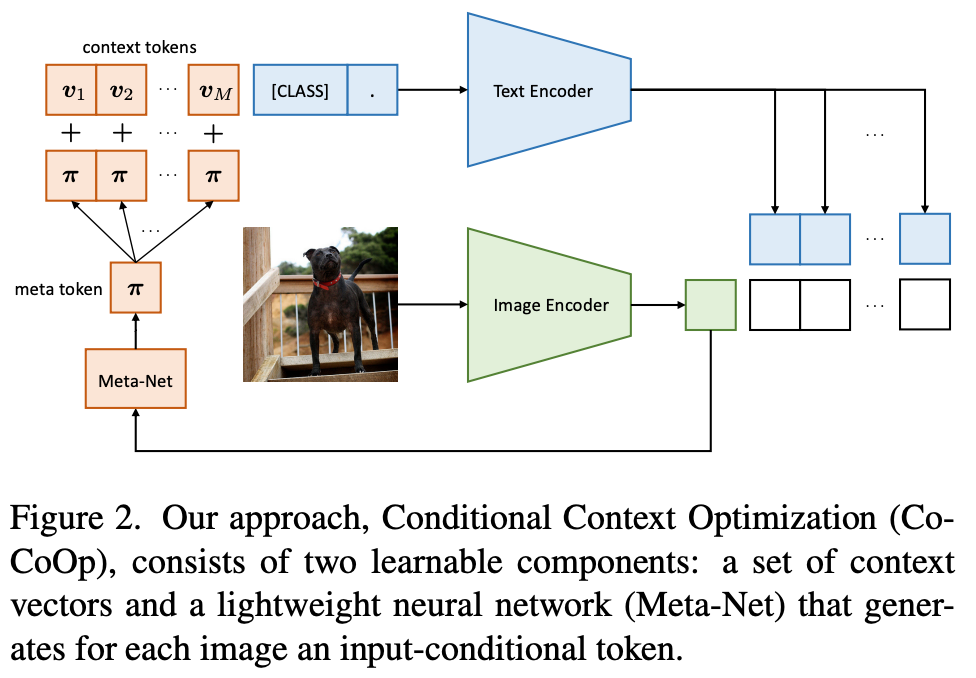
- instance-conditional context가 overfitting을 줄이기 위해 특정 클래스 세트에서 각 input instance로 초점을 이동하여 전체 작업으로 초점을 이동하므로 더 잘 일반화할 수 있음
- M개의 신경망 구축하여 M개의 context token 얻음 → the size of a neural network 크기 필요
- M개의 context vector 위에 Meta-Net이라는 lightweight neural network를 추가로 학습하여 각 입력에 대해 conditional token(vector)를 생성한 다음 context vector와 결합
- : 로 매개변수화된 Meta-Net
- 각 context token은 로 얻어짐
- 이 때 ,
- i번째 클래스에 대한 prompt는 input에 따라 조건이 지정됨
- 즉,
- 예측 확률은 다음과 같이 계산됨
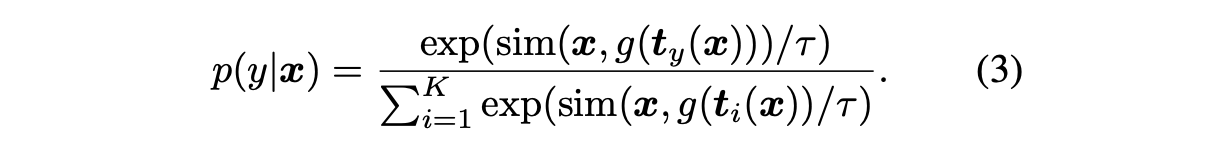
- 훈련 중 Meta-Net의 매개변수 와 함께 context vector 을 업데이트
- 이 연구에서 Meta-Net은 hidden layer가 input dimension을 로 줄이는 2-layer bottleneck structure(Linear-ReLU-Linear)로 설계
- Meta-Net에 대한 input은 단순히 image encoder에서 생성된 output feature
4. Experiments
- 세 가지 상황에서 평가됨
- generalization from base to new classes within a dataset
- cross-dataset transfer
- domain generalization
- 실험에 사용된 모든 모델은 CLIP 기반으로 함
4.1. Generalization From Base to New Classes
4.2. Cross-Dataset Transfer
4.3. Domain Generalization
4.4. Further Analysis
5. Limitations
- 훈련 효율성
- 훈련 속도가 느리고 batch size가 1보다 큰 경우 상당한 양의 GPU 메모리 소비
- → 각 이미지에 대해 text encoder를 통해 instance별 prompt의 독립적인 forward pass를 요구하는 instance conditional design이므로
- 11개 데이터셋 중 7개 데이터셋에서 hidden class에 대한 성능이 CLIP에 뒤쳐짐
- manual 기반과 learning 기반의 prompts 사이의 차이를 완전히 좁히거나 뒤집기 위해서는 더 많은 노력 필요
6. Discussion and Conclusion
- large pre-trained AI model의 가용성으로 인해 발생하는 중요한 문제, 이를 downstream application에 적용하는 방법을 다룸
- 매개변수 효율적인 prompt learning을 따르는 본 연구는 static prompt의 일반화 문제에 대한 통찰력을 제공
- conditional prompt learning을 기반으로 한 간단한 설계가 다양한 문제 시나리오에서 잘 수행됨
- 기본 클래스에서 새 클래스로의 일반화
- 데이터셋 간의 prompt transfer
- domain generalization
