JPA 12장
스프링 데이터 JPA
데이터 접근 계층을 개발할 때 반복적인 CRUD 문제
이를 처리하기 위한 인터페이스를 제공, 실행시점에 스프링 데이터 JPA 가 구현 객체를 동적으로 생성해 주입해준다.
- 데이터 접근 계층을 개발할 때 구현 클래스 없이 인터페이스만 작성해도 된다.
- CRUD 를 처리하기 위한 공통 메소드는 스프링 데이터 JPA 가 제공하는 JpaRepository 인터페이스에 있음
- 공통으로 처리할 수 없는 메소드 같은 경우에는..??? 스프링 데이터 JPA 가 메소드 이름을 분석해 JPQL 을 실행한다!!!
공통 인터페이스 기능
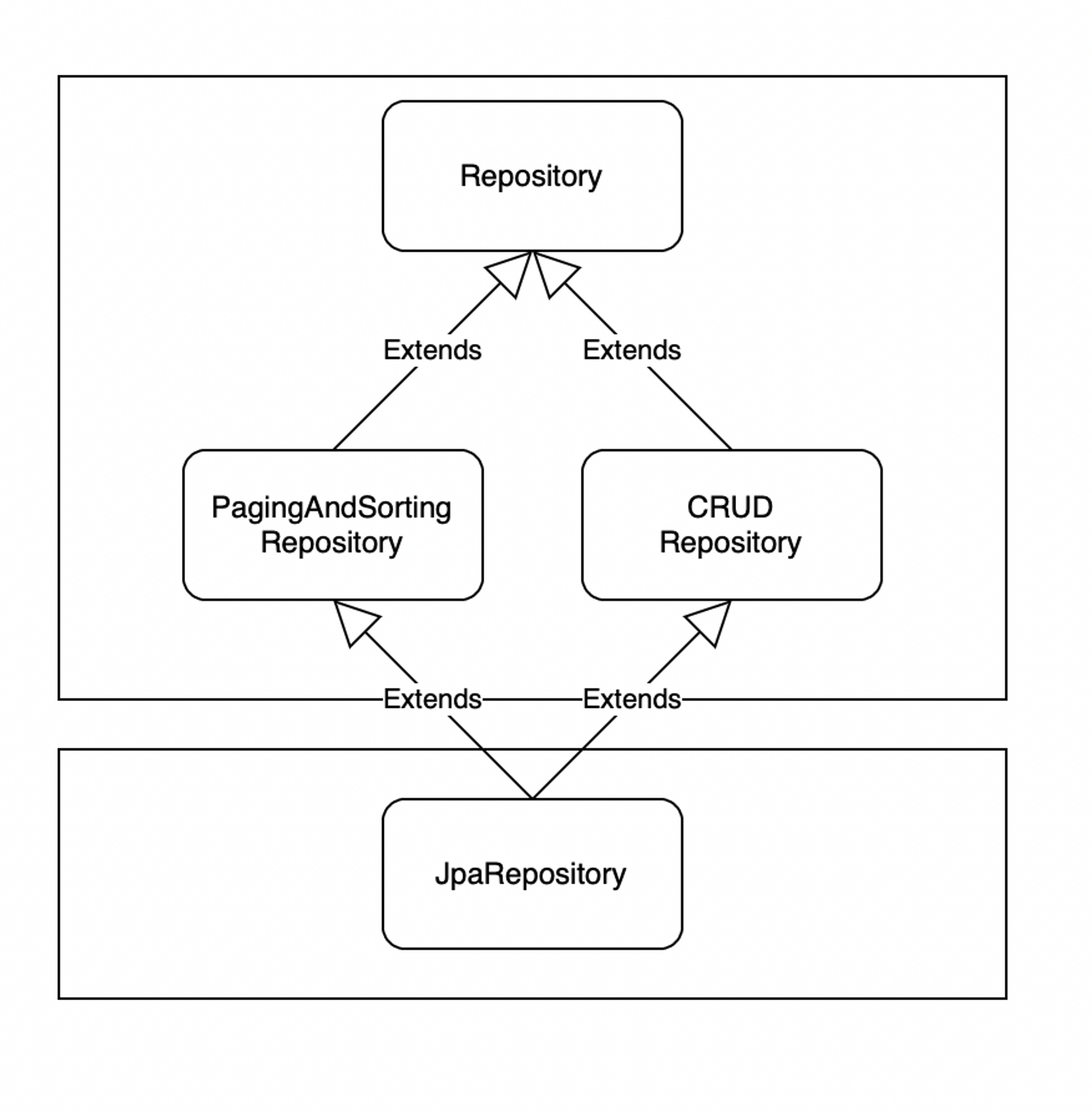
쿼리 메소드 기능
- 메소드 이름으로 쿼리 생성
List<Member> findByEmailAndName(String email, String name);
→ 인터페이스 메소드를 실행할 때 스프링 데이터 JPA 가 이를 분석해 JPQL 을 생성하고 실행
select m from Member where [m.email](http://m.email) =?1 and [m.name](http://m.name) = ?2
- JPA NamedQuery
- @Query, 리포지토리 메소드에 쿼리 정의
@Query("select m from Member m where m.username = ?1")
Member findByUsername(String username);- 실행할 메소드에 정적 쿼리를 직접 작성
- 애플리케이션 실행 시점에 문법 오류를 발견할 수 있다
- 만약 네이티브 SQL 을 사용하고 싶다면 nativeQuery = true 설정해주면 됨
파라미터 바인딩
- 위치기반 select m from Member m where m.username = ?1
- 이름기반 select m from Member m where m.username = :name
기본은 위치 기반이기에 이름 기반으로 하고자 하면 아래와 같이 작성
@Query("select m from Member m where m.username = :name")
Member findByUsername(@Param("name") String username);벌크성 쿼리를 하고자 하면 @Modifying 어노테이션을 사용하면 된다
@Modifying(clearAutomatically=true) // 영속성 컨텍스트 초기화 옵션
@Query("update Product p set p.price = p.price * 1.1 where p.stockAmount < :stockAmount")
int bulkPriceUp(@Param("stockAmount") String stockAmount);반환 타입
결과가 한 개 이상이면 컬렉션 인터페이스 사용
단건이면 반환 타입을 지정
이때 단건을 원했는데 2개 이상 조회되면 null 을 반환
JPA 가 내부에서 JPQL 의 getSingleResult() 를 호출 → 원래는 예외가 발생 → 때문에 스프링 데이터 JPA 가 이 예외를 무시하고 null 을 반환
페이징과 정렬
쿼리 메소드에 페이징과 정렬 기능을 사용할 수 있도록 파라미터 제공
// count 사용
Page<Member> findByName(String name, Pageable pageable);
// count 사용 x
List<Member> findByName(String name, Pageable pageable);
List<Member> findByName(String name, Sort sort);pageable 은 인터페이스이기에 실제 사용할 때는 해당 인터페이스를 구현한 PageRequest 객체를 사용한다.
JPA13장
jpa 하이버네이트 5버전 부터 mysql generation auto = identity 에서 table 로 변경됨
@PrimaryKey 설정과 @Unique 설정 각각 DB 인덱스가 형태가 다름
트랜잭션 범위의 영속성 컨텍스트
스프링 컨테이너의 기본 전략
스프링 컨테이너는 트랜잭션 범위의 영속성 컨텍스트 전략을 사용
→ 트랜잭션을 시작할 때 영속성 컨텍스트를 생성하고 트랜잭션이 끝날 때 영속성 컨텍스트를 종료한다, 같은 트랜잭션 내에서 항상 같은 영속성 컨텍스트에 접근한다
트랜잭션 어노테이션을 걸어두면 걸어둔 메소드를 호출하기 전에 트랜잭션 AOP가 동작함
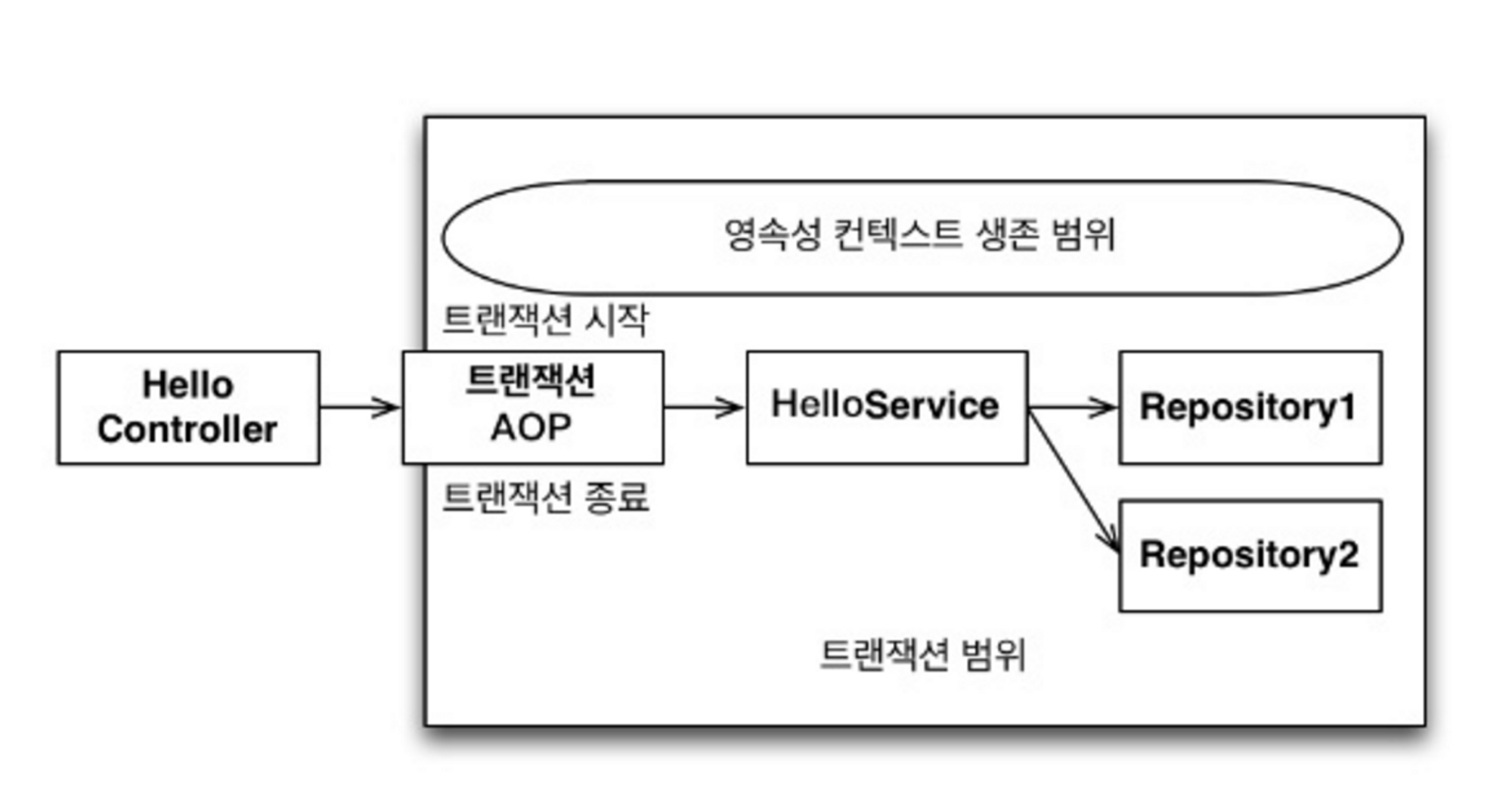
- 트랜잭션이 같으면 같은 영속성 컨텍스트를 사용
- 트랜잭션이 다르면 다른 영속성 컨텍스트를 사용
- 트랜잭션을 커밋하면 영속성 컨텍스트를 플러시 해서 변경 사항을 DB 에 반영 후 트랜잭션 커밋
- 예외가 발생하면 플러시 호출하지 않음
준영속 상태와 지연 로딩
엔티티 코드에서 다대일 연관관계 FetchType.LAZY 로 설정해 글로벌 지연 로딩을 설정했을 때
서비스 계층에서 걸어둔 트랜잭션 이후 컨트롤러 계층에서 join 된 객체의 데이터를 가져오려 한다면 지연 로딩을 통해 가져온 객체는 프록시 객체이기에 문제가 된다.
public String MyController(Long id) {
Order order = service.getOrder(id);
Member member = order.getMember();
member.getName(); // 오류 발생
}해결 방법
- 글로벌 패치 전략 수정
- JPQL 패치 조인
- 강제 초기화
글로벌 패치 전략 수정
FerchType.EAGER 로 수정
단점
- 사용하지 않는 엔티티를 로딩함
- N+1 문제 발생
N+1 문제란??
JPA가 JPQL만을 분석해서 SQL을 생성할 때는 글로벌 패치 전략을 참고하지 않고 오직 JPQL 자체만 사용한다.
select o from Order oJPQL 을 분석해 SELECT * FROM ORDER SQL 을 생성- DB에서 결과를 받아 order 엔티티 인스턴스를 생성
- Order.member 글로벌 패치 전략이 즉시로딩이기에 연관된 member 도 로딩해야 함
- 연관된 member 를 영속성 컨텍스트에서 찾음
- 영속성 컨텍스트에 없다면 SELECT * FROM MEMBER WHERE id=? SQL 실행
만약 조회한 order 엔티티가 10개면 member 를 조회하는 SQL 도 10번 실행
이처럼 처음 조회한 데이터 수만큼 다시 SQL을 사용해서 조회하는 것을 N+1 문제
절대 FetchType.EAGER 때문에 생기는 문제가 아니다.
핵심은 JPQL 이 SQL 을 추상화한 객체지향 쿼리 언어라는 점이다.
때문에 select o from Order o 를 하게 되면 해당 엔티티를 조회하는 쿼리를 실행하지 연관관계 데이터는 무시한다.
그리고 FetchType 설정에 따라 필요한 시점에 연관된 데이터도 별도 조회하게 되는 것이다.
해결방법: JPQL 패치 조인
JPQL을 호출하는 시점에 함께 로딩할 엔티티를 선택할 수 있는 패치 조인
select o from Order o
→ select o from Order o join fetch o.member
단점
- 화면에 맞춘 레포지토리 메소드가 증가 (컨트롤러 계층이 데이터 접근 계층 침범) → 논리적인 의존관계 발생
강제로 초기화
프록시 객체가 실제 값을 사용하는 시점에 초기화 되는 점을 이용 (member.getName())
서비스 계층에서 컨트롤러 계층으로 넘겨주기 전 초기화를 진행 후 넘겨줌
public OrderMyService(Long id) {
Order order = repository.getOrder(id);
order.getMember().getName(); // 초기화 진행
return order;
}- 하이버네이트는 initialize() 메소드를 사용할 수 있음
단점
- 뷰가 필요한 엔티티에 따라 서비스 계층의 로직을 변경해야 함. 컨트롤러 계층이 서비스 계층을 침범하네?!?!!
FACADE 계층 추가
- 뷰를 위한 프록시 객체 초기화를 진행
- 서비스 계층을 호출해 비즈니스 로직 실행
- 중간에 계층이 하나 더 끼어 들어 좋지 않음…
결국 엔티티가 컨트롤러 계층에서 준영속 상태이기에 발생하는 문제!!!
그래서 영속성 컨텍스트를 뷰까지 살아있게 열어두는 OSIV 라는게 있다는데
나는 차라리 DTO를 사용해서 영속성 컨텍스트가 유지되는 중간에 DTO에 맞게 데이터 넣어줄래…!!
