logloss는 다중 클래스 분류 모델(target이 3개 이상)을 평가하는 방법입니다.
혹시 그런적 있으신가요?
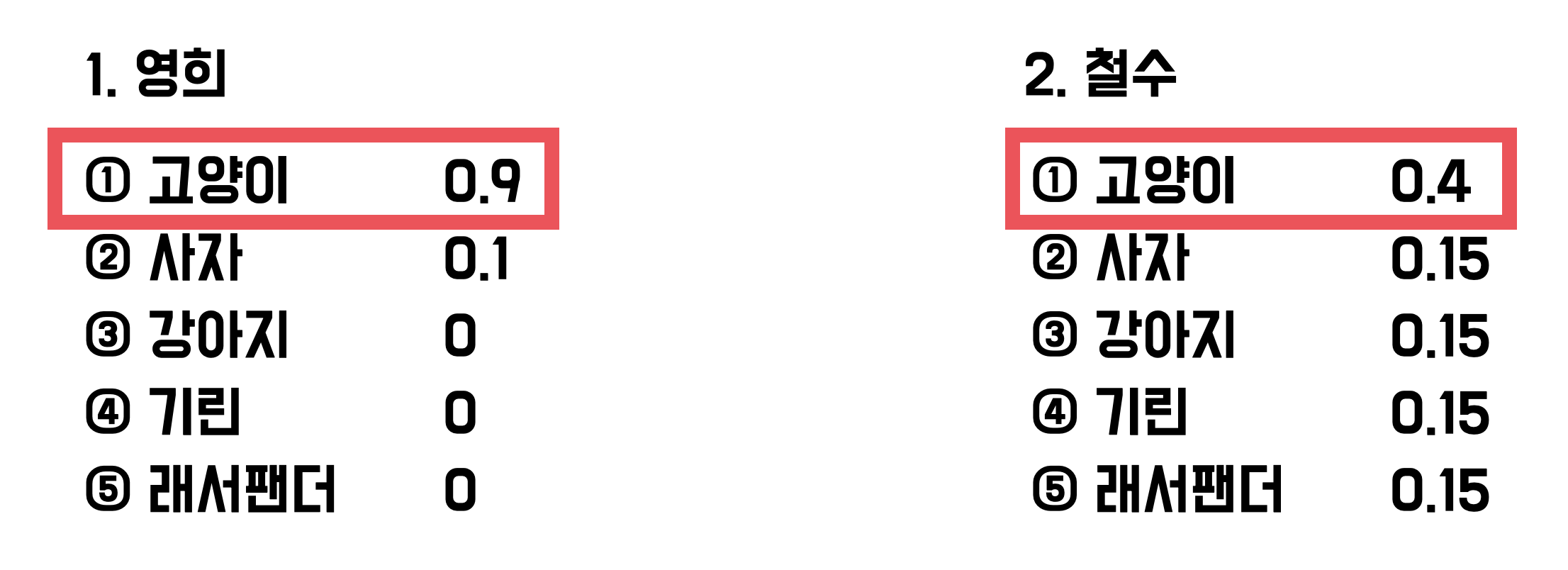
시험 문제를 제대로 풀었는데, 찍어서 맞춘것과 점수가 같아서 조금 억울하다.

5지선다 시험에서는 영희와 철수 모두 정답자입니다.
다만, 영희는 높은 확률로 정답을 확신했기 때문에 조금은 점수를 더 높게 받고 싶을 수 있습니다.
만약 확률에 대해 평가를 한다면, 두명의 점수는 달라질 수 있습니다.
정답을 더 높은 확률로 예측할 수록 좋은 모델이라고 평가하는것이 logloss입니다.
1. 음의 로그함수
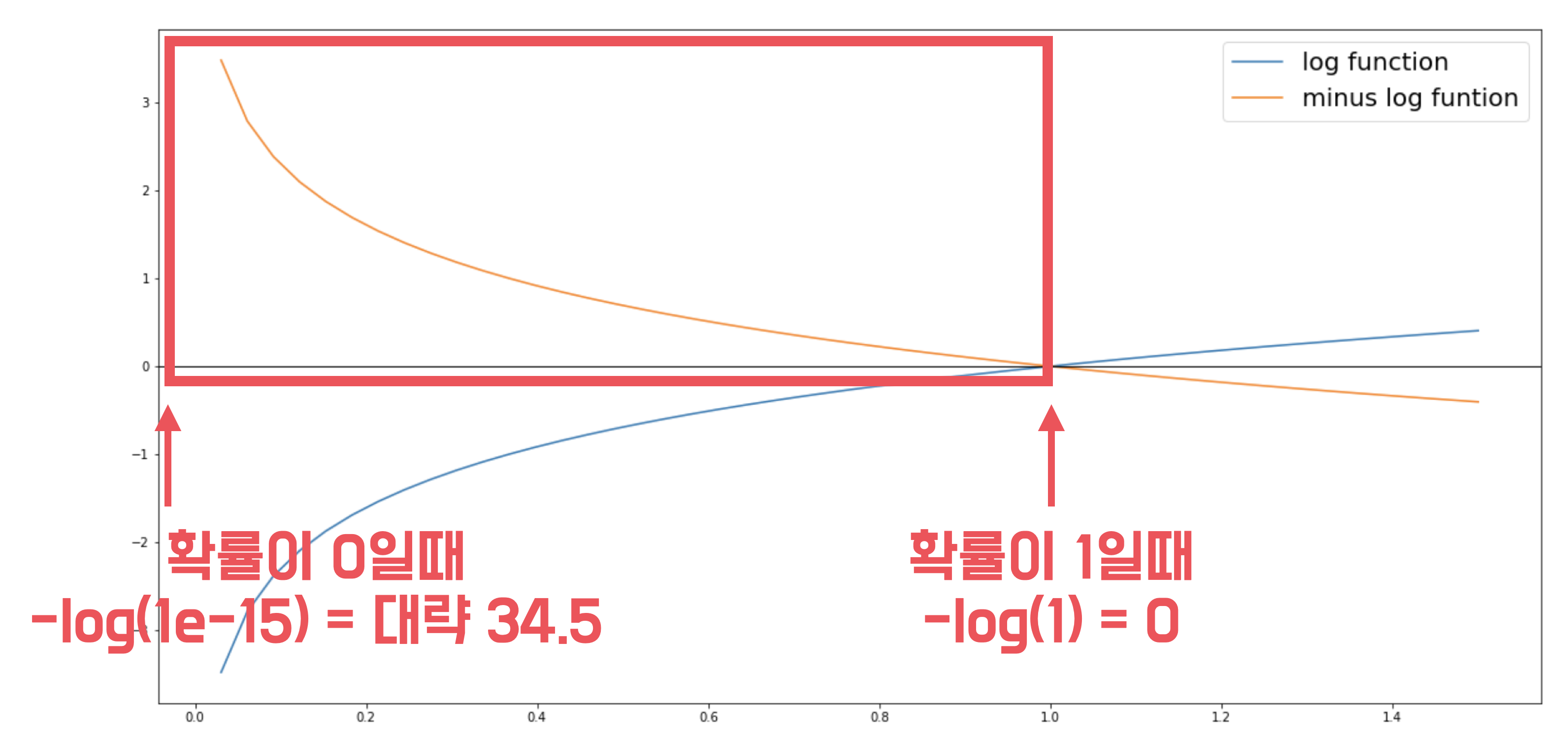
logloss는 음의 로그 함수를 사용하는데, log함수의 결과에 -1을 곱한 결과로 x축을 기준으로 대칭을 이룹니다.
음의 로그 함수는 1일때 0이고, 0에 가까워질 수록 숫자가 급격하게 커집니다.
이 성질을 이용해서 logloss가 구현됩니다.
음의 로그함수는 0일때 무한대의 값을 가지기 때문에 0과 아주 가까운 수인 (1e-15)를 넣은 값인 34.5를 최대값으로 사용합니다. (변경할 수 있습니다.)
그렇기 때문에 logloss 값이 작을수록 좋은 모델입니다.
2. 계산식
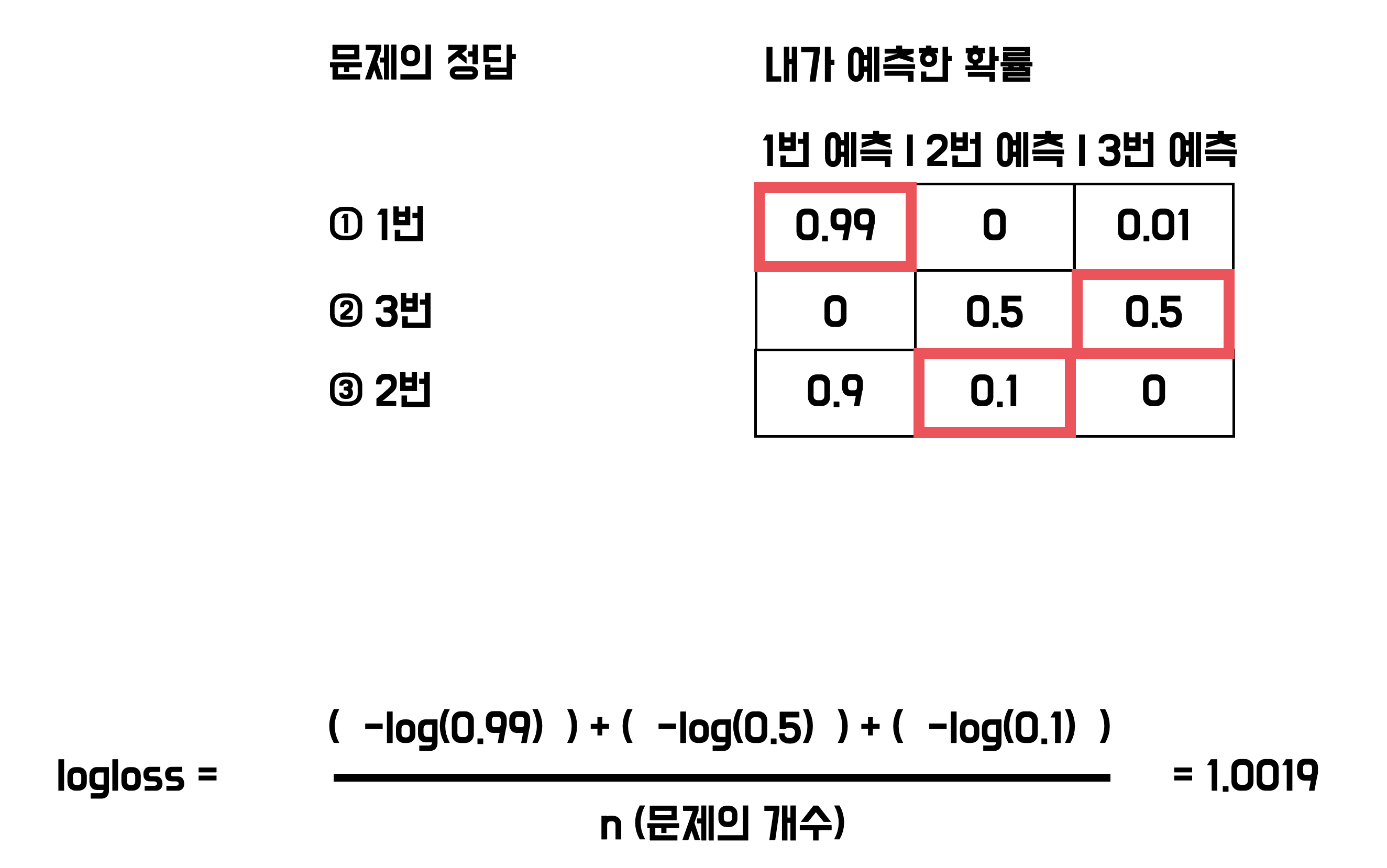
각 문제 정답의 확률에 대해 음의로그값의 평균을 사용합니다.

3. 손으로 해보기
직접 계산해보면, 쉽게 logloss를 구할 수 있습니다.
4. predict_proba
앗 혹시, 각 class에 대해 정답이 될 확률을 어떻게 구하는지 모르신다구요?
predict_proba는 정답이 될 확률을 계산해줍니다.
사이킷런, lightgbm 등등 여러 라이브러리에서 지원합니다.
사실 분류 모델의 예측은 predict_proba로 예측한 확률중에서 제일 높은 값을 선택하는 방식입니다.
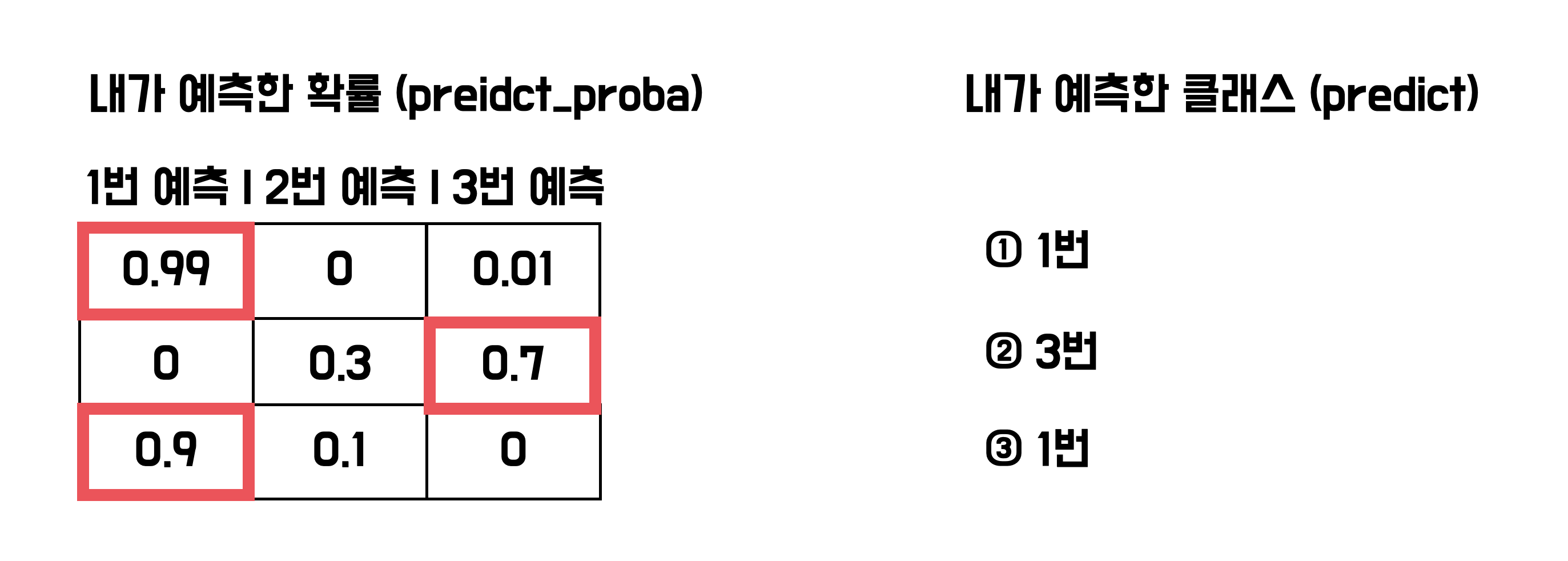
predict_proba를 직접 사용해 봅시다.
# numpy를 불러옵니다.
import numpy as np
# 학습 시킬 train 데이터
# 1일때 1, 2일때 2, 3일때 3을 내놓도록 만들었습니다.
train_x = np.array([1, 2, 3])
train_y = np.array([1, 2, 3])
# 검증에 사용할 데이터
# 마찬가지로 1일때 1, 2일때 2, 3일때 3을 내놓도록 만들었습니다.
valid_x = np.array([3, 2, 1])
valid_y = np.array([3, 2, 1])
# 사이킷런의 RandomForestClassifier를 가져옵니다.
from sklearn.ensemble import RandomForestClassifier
# 모델 생성
rf = RandomForestClassifier()
# 학습
rf.fit(train_x.reshape(-1, 1), train_y)
# predict_proba로 확률 예측
proba_result = rf.predict_proba(valid_x.reshape(-1, 1))
print("proba_result", proba_result)
# 확률에 대해 가장 큰값 가져오기
res_list = []
for arr in proba_result:
res_class = np.argmax(arr) + 1
res_list.append(res_class)
print("res_list", res_list)
# class 예측
predict_result = rf.predict(valid_x.reshape(-1, 1))
print("predict_result", predict_result)
"""
proba_result [[0.07 0.25 0.68]
[0.24 0.71 0.05]
[0.59 0.36 0.05]]
res_list [3, 2, 1]
predict_result [3 2 1]
"""5. logloss 파이썬 구현
파이썬으로 직접 logloss 함수를 만들고 3번의 예시에 넣어서 1.0019 가 나오는지 확인해봅시다.
# numpy를 불러옵니다.
import numpy as np
# 직접 logloss를 계산할 함수를 생성합니다.
# answer_array는 정답 array
# proba_array는 확률 array
def my_logloss(answer_array, proba_array):
# 0이면 무한대 값이 나오기 때문에 0에 가까운 값으로 치환해줍니다.
MIN_VALUE = 1e-15
# array의 크기를 가져옵니다.
size = answer_array.shape[0]
# 반복문을 사용해서 logloss의 합을 계산합니다.
logloss_sum = 0
# zip함수로 묶으면 함께 순회할 수 있습니다.
for answer, arr in zip(answer_array, proba_array):
proba = arr[answer - 1]
# 0이면 무한대 값이 나오기 때문에 0에 가까운 값으로 치환해줍니다.
if proba <= MIN_VALUE:
proba = MIN_VALUE
# 음의 로그함수에 넣어서 logloss 계산
logloss_sum += -np.log(proba)
# logloss의 평균 계산
result = logloss_sum / size
# 반환
return result
# answer_array는 정답 array
# proba_array는 확률 array
answer_list = np.array([1, 3, 2])
proba_list = np.array([[0.99, 0, 0.01], [0, 0.5, 0.5], [0.9, 0.1, 0]])
# my_logloss 결과 출력
my_logloss_result = my_logloss(answer_list, proba_list)
print('my_logloss', my_logloss_result)
# 비교를 위해 사이킷런의 log_loss 함수를 불러옵니다.
from sklearn.metrics import log_loss
# 사이킷런 결과 확인
sklearn_reslt = log_loss(answer_list, proba_list)
print("sklearn_reslt", sklearn_reslt)
"""
my_logloss 1.0019275364691642
sklearn_reslt 1.001927536469165
"""6. 제출방법
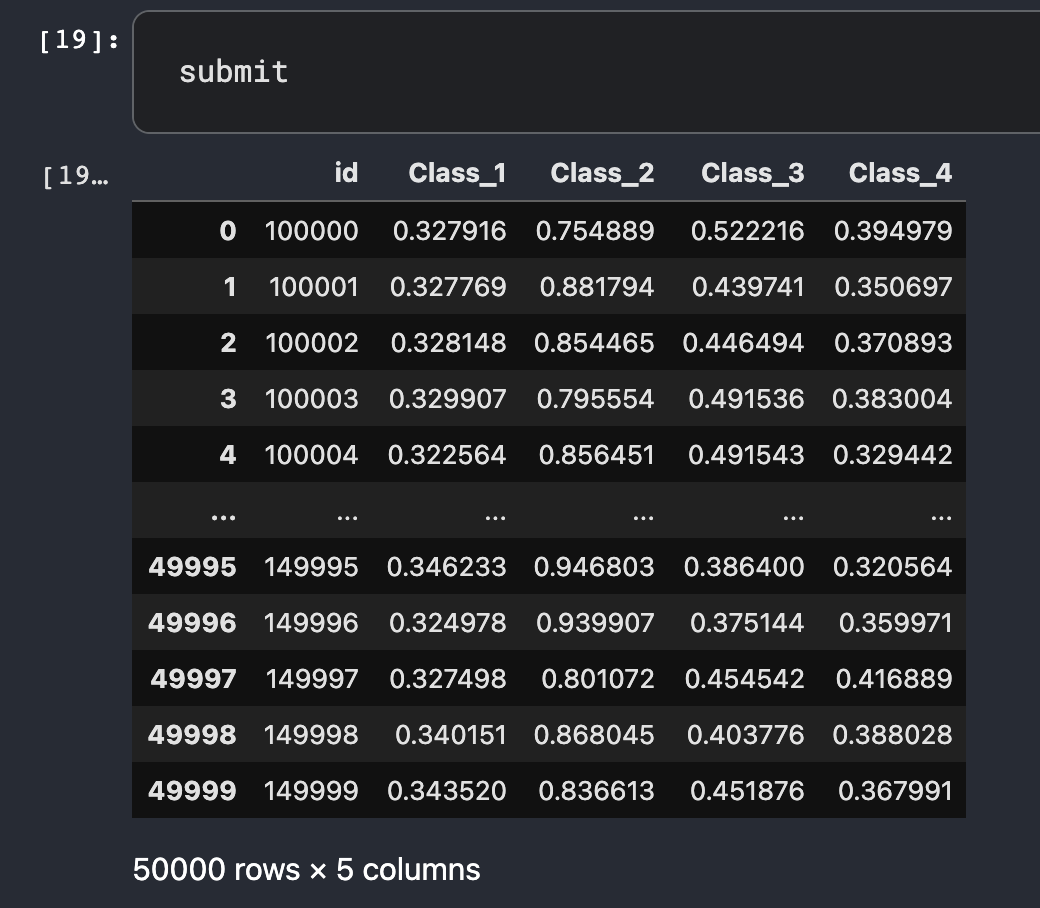
캐글, 데이콘과 같은 대회 플랫폼에서 다중 클래스 분류 모델의 평가방법으로 logloss를 사용하고 있으며
Tabular Playground Series - May 2021 대회 예시
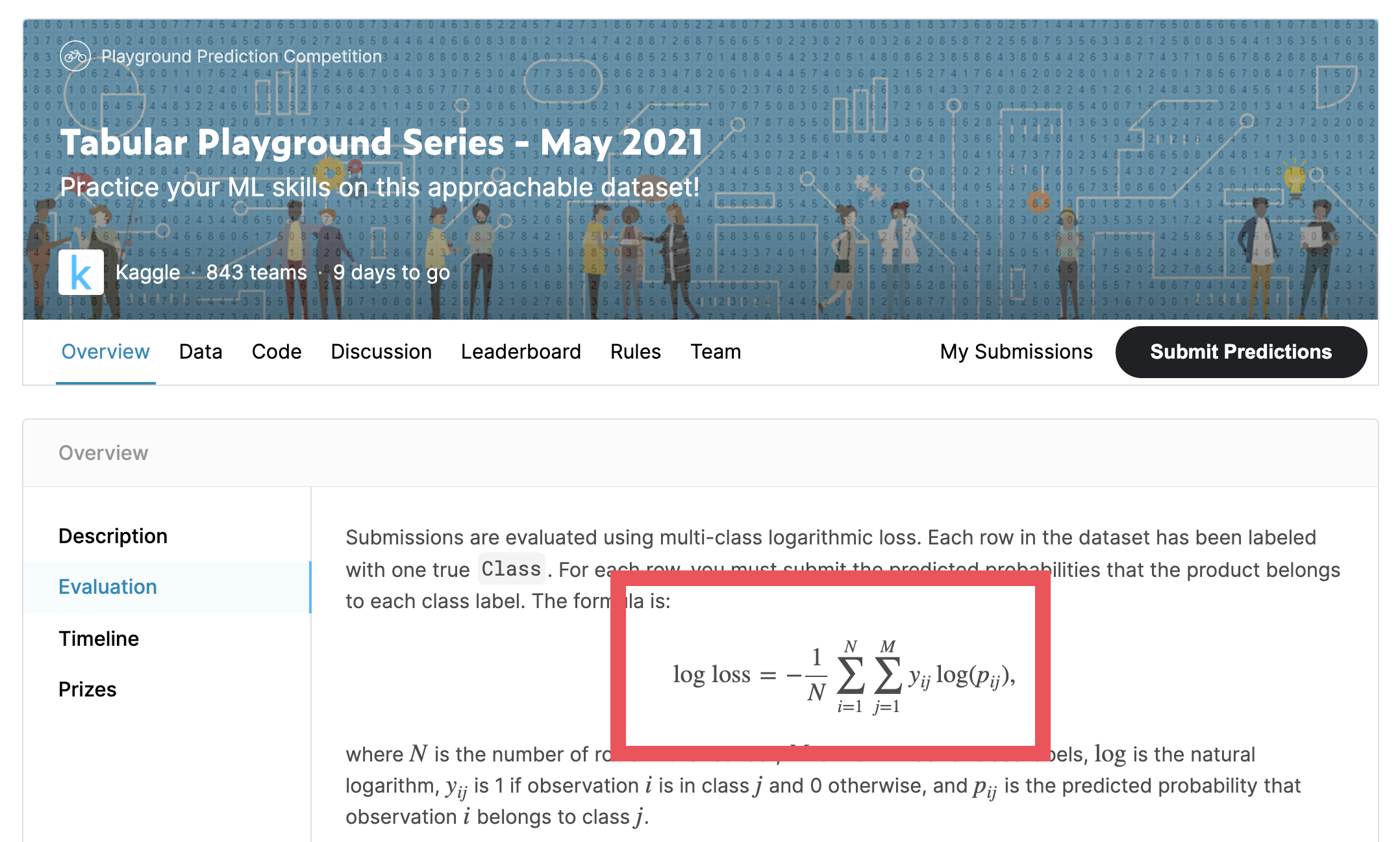
다음과 같이 각 클래스에 대한 확률을 계산후 제출합니다.