rate() 연산이란?
시계열 데이터 중에는 그 자체의 값보다 변화량이 더 중요한 경우가 있다. 예를 들어 리눅스의 cpu 사용량은 어떤 프로세스가 실행되는 동안 cpu를 점유한 시간으로 정의된다. cpu 점유 시간 자체는 프로세스가 종료되기 전까지 계속 증가할 수 밖에 없기 때문에, 단순히 cpu 점유 시간이 많은 프로세스를 점검하는 것보다 cpu 점유 시간이 최근 빠르게 늘어난 프로세스를 점검하는 것이 시스템 관리 측면에서 훨씬 도움이 된다.
rate() 연산은 지정한 시간 범위 내에 메트릭이 변화한 정도를 보기 위한 연산이다. 특히 Counter 타입의 메트릭과 자주 사용되는데, 끊임없이 증가하기만 하는 raw data를 볼 이유가 없기 때문이다. Counter 타입 메트릭의 대표적인 예로 앞서 소개한 cpu 사용 시간이 있다.
rate() 계산 방법
기본
rate는 range vector의 처음과 끝의 샘플을 이용해 '초당 평균 변화율'을 계산한다. t1과 t2 사이의 초당 평균 변화율은 (sample(t2) - sample(t1)) / (t2 - t1) 을 통해 계산한다. 당연히 range vector 내에 최소한 두 개의 샘플이 존재해야 한다.
예를 들어 1분 동안의 rate를 계산한다고 가정하자. 데이터는 15초마다 수집 되었고 값은 [10, 20, 50, 80] 이다. rate는 첫 샘플인 10과 마지막 샘플인 80을 통해 계산한다. 앞서 소개한 공식대로 계산하면70 / 60 = 1.166 이 된다.
주의할 점은 rate() 연산은 처음과 끝 점을 제외한 나머지 데이터를 버린다는 것이다. 모니터링 대상의 spike를 정확하게 잡아내야 한다면 rate 연산의 인자로 긴 기간의 range vector를 주는 것은 좋지 않은 선택이다.
외삽
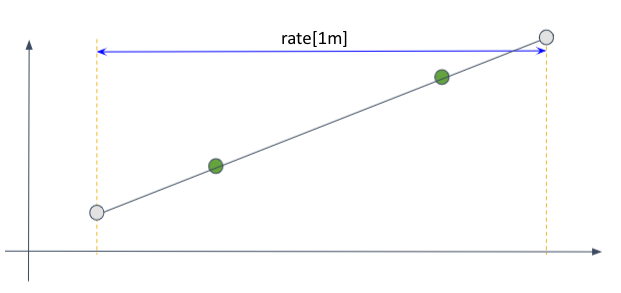
앞서 소개한 연산 과정은 다음과 같이 rate() 연산의 time-range에 딱 맞게 샘플이 위치하는 이상적인 상황을 가정하고 있다.
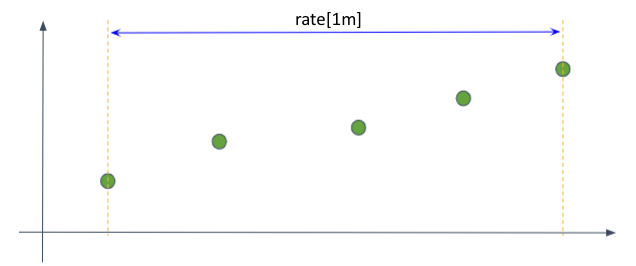
그러나 실제로는 time-range의 경계 부분에 샘플이 일치하지 않을수도 있다.
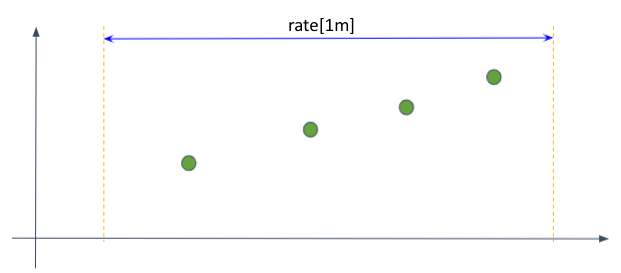
물론 위의 상황에서 첫 샘플과 마지막 샘플을 이용해 rate를 구할수도 있다. 그러나 이렇게 되면 1분 간의 평균 변화율이라는 쿼리의 의도와 맞지 않게 된다. Prometheus는 실제 점 대신 가상의 점을 추측하여 사용하는 외삽(extrapolation)을 이용한다. (간혹 정수 밖에 관측되지 않는 메트릭의 변화량이 float type으로 측정될 때가 있는데 외삽이 그 원인이다.)
외삽을 하는 방법은 다음과 같다. 우선 첫 샘플과 끝 샘플을 이은 직선을 긋고 기울기를 구한다. 이 기울기가 관측되지 않은 기간에도 유지되었을 것이라고 가정하고, time-range 경계에 가상의 점을 찍는다. 이 가상의 점들끼리 rate() 연산을 해 변화량을 구한다.
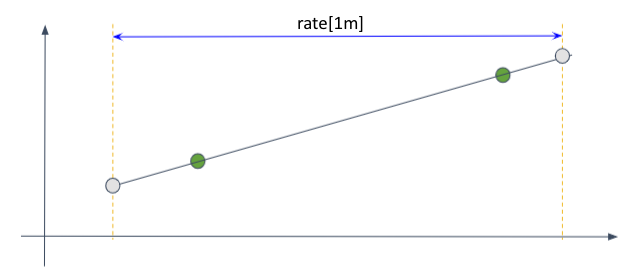
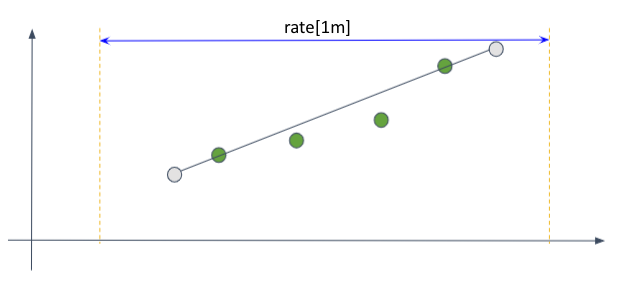
그래프 기울기를 이용한 외삽법을 무조건 적용하지는 않는다. 다음의 사례를 보면 time-range의 경계와 첫 샘플, 마지막 샘플의 경계가 멀다.
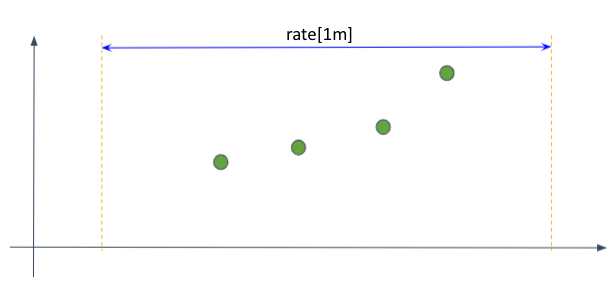
이런 그래프에 기울기를 이용한 외삽을 하게되면 왜곡이 심하게 생길 수 있다.
데이터의 왜곡을 방지하기 위해 시간 범위의 경계와 샘플의 경계가 너무 멀 때는 외삽으로 찍는 점의 범위를 제한한다. 우선 '너무 멀다'고 판단하는 기준은 시간 범위의 경계와 샘플의 경계의 거리가 샘플 간 평균 거리의 1.1배를 초과하는 것이다. 이럴 때는 가상의 직선을 끝까지 긋지 않고, 샘플 간의 평균 거리의 절반 만큼 떨어진 곳에 점을 찍는다.
Counter 메트릭의 리셋 처리 방식
Counter 타입 메트릭의 값은 항상 단조 증가하는 것이 원칙이다. 그러나 프로세스가 재실행 될 경우 해당 메트릭의 값이 0으로 리셋될 수 있다. 특히 쿠버네티스 환경이라면 파드가 재배치되는 일이 잦으므로 흔히 있을 수 있는 상황이다. Prometheus는 Counter 메트릭의 값이 줄어들 경우, 해당 메트릭이 0으로 리셋되었다가 다시 올라온 것으로 취급한다.
예를 들어 어떤 Counter 타입 메트릭의 값이 t1 시점에 100, 10초 후인 t2 시점에 40이었다고 하자. 변화량을 측정하면 -60이다. 그러나 Counter 메트릭이라면 t1, t2 사이의 어떤 구간에서 프로세스가 재실행되어 메트릭이 0으로 리셋되었다가 50으로 올라온 것으로 계산한다. 따라서 변화량은 40이 된다.
코드 탐구
promql/functions.go에 extrapolatedRate라는 함수가 있다. 코드를 따라가며 동작 방식을 확인해보자.
우선 주어진 샘플이 두 개 미만일 경우 연산하지 않는다는 사실을 함수 초반부에서 확인할 수 있다.
// No sense in trying to compute a rate without at least two points. Drop
// this Vector element.
if len(samples.Points) < 2 {
return enh.Out
}다음으로 주목할만한 부분은 Counter 타입 메트릭의 값 감소를 처리하는 부분이다. 우선 sample(t2)-sample(t1)으로 변화량(resultValue)을 구한다. Counter 메트릭의 값이 줄어들었을 경우, 이를 0으로 갔다가 다시 늘어난 것으로 생각해 변화량에 더하고 있다.
resultValue := samples.Points[len(samples.Points)-1].V - samples.Points[0].V
if isCounter {
var lastValue float64
for _, sample := range samples.Points {
if sample.V < lastValue {
resultValue += lastValue
}
lastValue = sample.V
}
}개인적으로는 이러한 방식이 크게 좋아보이지는 않는다. 변화량을 모두 구해 평균 내지 않고 양 끝점을 이용하는 방식은 계산의 부하를 크게 줄일 수 있다는 장점이 있다. 그러나 Counter 메트릭은 혹시나 값이 줄어들었을 경우를 대비해 모든 샘플을 비교하고 있어 이런 장점이 없어진다. 왜 이러한 방식을 취하였는지 의문이다.
Counter 메트릭에 대한 처리는 이 부분이 끝이 아니다. Counter는 음수 변화율이 있을 수 없으므로, 외삽점이 음수가 될 수 없도록 값을 가공한다. (아직 이 부분에 대해 수학적으로 완전히 이해하지는 못했다. 특히 durationToZero 변수의 계산 방식이 이해가 가지 않는다.)
// Duration between first/last samples and boundary of range.
durationToStart := float64(samples.Points[0].T-rangeStart) / 1000
durationToEnd := float64(rangeEnd-samples.Points[len(samples.Points)-1].T) / 1000
sampledInterval := float64(samples.Points[len(samples.Points)-1].T-samples.Points[0].T) / 1000
averageDurationBetweenSamples := sampledInterval / float64(len(samples.Points)-1)
if isCounter && resultValue > 0 && samples.Points[0].V >= 0 {
// Counters cannot be negative. If we have any slope at
// all (i.e. resultValue went up), we can extrapolate
// the zero point of the counter. If the duration to the
// zero point is shorter than the durationToStart, we
// take the zero point as the start of the series,
// thereby avoiding extrapolation to negative counter
// values.
durationToZero := sampledInterval * (samples.Points[0].V / resultValue)
if durationToZero < durationToStart {
durationToStart = durationToZero
}
}
다음 부분에서는 외삽할 지점을 정한다. time-range의 시작점과 끝점에 외삽을 하는 것이 기본이다. 시간 경계와 샘플 경계의 거리가 먼 경우에는 샘플 간 평균 거리의 절반 만큼 떨어진 점을 외삽점으로 정한다.
// If the first/last samples are close to the boundaries of the range,
// extrapolate the result. This is as we expect that another sample
// will exist given the spacing between samples we've seen thus far,
// with an allowance for noise.
extrapolationThreshold := averageDurationBetweenSamples * 1.1
extrapolateToInterval := sampledInterval
if durationToStart < extrapolationThreshold {
extrapolateToInterval += durationToStart
} else {
extrapolateToInterval += averageDurationBetweenSamples / 2
}
if durationToEnd < extrapolationThreshold {
extrapolateToInterval += durationToEnd
} else {
extrapolateToInterval += averageDurationBetweenSamples / 2
}
resultValue = resultValue * (extrapolateToInterval / sampledInterval)
매우 유익하네요 감사합니다!