Spike와 dip이란?
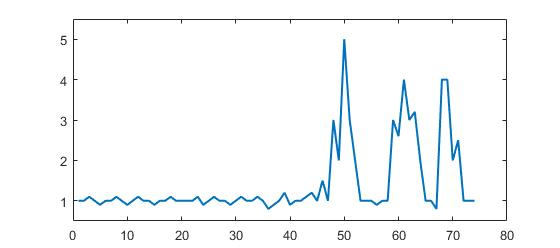
시계열 데이터의 수치가 한 순간 급증하는 현상을 spike, 급감하는 현상을 dip이라고 한다. spike와 dip은 서비스의 이상을 나타내는 중요한 징후다. 대개 서비스에 장애가 생길 때에는 CPU나 디스크 같은 시스템 자원이나, 응용 프로그램의 특정 연산의 수행량에 큰 변화가 생기는 경우가 많다. 예를 들어 디스크 출력이 급증하거나 웹서버의 초당 연산량이 급감하는 등의 현상이 나타난다.
모니터링 시스템의 가장 중요한 임무는 장애가 발생했다는 사실과, 장애를 초래한 원인을 최대한 빠르게 인지하게 해주는 것이다. spike와 dip을 제대로 포착하지 못한다면 장애 대응이 매우 어려워질 수 있다.
그래프의 해상도는 유한하다
Prometheus의 데이터를 시각화 하기 위해 대시보드를 함께 사용한다. Prometheus의 데이터 수집 간격이 15초라고 가정하자. 1년치를 조회하면 200만 개가 넘는 데이터를 그려야 한다. 이 방대한 데이터를 모두 그릴수는 없으므로, 대시보드는 그래프의 해상도(점의 개수)를 한정해야 한다.
대표적인 모니터링 대시보드인 Grafana에서는 쿼리 옵션의 Max data points라는 변수를 통해 그래프의 해상도를 조절한다.
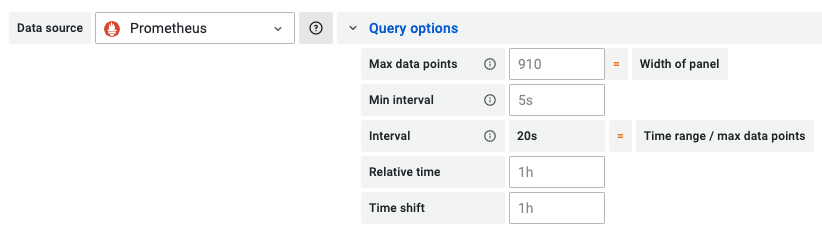
데이터의 개수가 Max data points를 넘는다면 데이터를 생략하고 그리는 수 밖에 없다.
Range Query와 step
방대한 데이터를 어떻게 요약하는지 알기 위해선 Range Query의 동작 방식을 알아야 한다. 개발자 도구를 이용하면 Prometheus web UI에서 그래프를 그릴 때 서버에 어떤 요청을 보내는지 알 수 있다. 다음은 최근 한 시간 동안의 disk io 사용량을 질의할 때의 URL 파라미터이다.
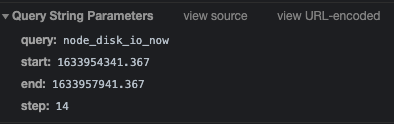
- query: 사용자가 작성한 promQL 원문
- start, end: 조회하려는 데이터의 범위 (unix timestamp)
- step: evaluation 간격
내부 동작과 완전히 일치하진 않지만 대략 논리적인 흐름을 따져보면 다음과 같다. 10시 정각에 최근 1시간 데이터를 요청했다고 가정하자. 1시간 전인 9시 정각부터 step 만큼 건너뛰면서 쿼리의 결과를 계산한다. 만약 쿼리가 15초라면 9시 0분 15초, 30초, 45초... 시점에 쿼리를 evaluation하고, 이 결과를 range vector(쉽게 말해 배열) 형태로 반환하게 된다.
Grafana는 조회 범위가 넓어지면 step의 값을 크게 해서 렌더링 부담을 줄인다. 시간 범위를 바꿔가면서 Query Option의 값을 보면 이를 확인할 수 있다.

(최근 5분 조회)
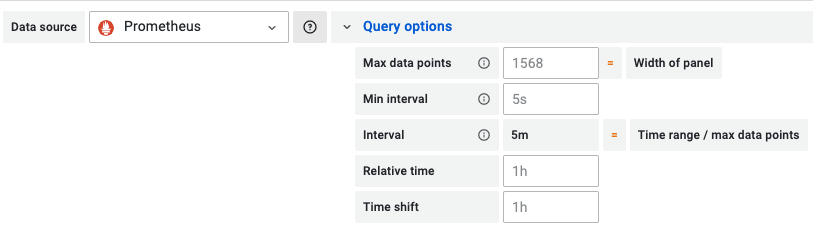
(최근 7일 조회)
변화하는 step의 값은 $__interval이라는 내부 변수로 참조할 수 있다.
Spike의 누락 원인과 대처법
step의 범위를 크게한다는 것은 결국 존재하는 데이터를 무시한다는 뜻이다. 무시하는 데이터에 하필 spike가 존재했다면 그래프에 나타나지 않게 된다. TSDB에는 분명 저장되어 있는 spike가 사용자 눈에만 보이지 않는 것이다.
모든 데이터를 다 표시할 수도 없고, spike를 생략해서도 안 된다. 결국 지금처럼 데이터를 건너뛰되, 특징적인 값을 살려야 한다. 이럴때 쓸 수 있는 것이 max_over_time, min_over_time과 같은 aggregation_over_time 함수들이다. 예를 들어 디스크 사용량의 spike를 잡고 싶다면 다음과 같이 쿼리를 작성하면 된다.
max_over_time(node_disk_io_now[$__interval])쿼리 계산 과정을 살펴보자. 앞서 Grafana가 step으로 사용하는 값은 $__interval이라는 변수에 저장된다고 했다. node_disk_io_now[$__interval]은 직전 evaluation 지점부터 지금까지의 모든 데이터를 배열 형태로 반환한다. max_over_time은 이 배열에서 최대값을 찾아 반환한다.
마치며
이번 글에선 Prometheus를 사용하는 대시보드에서 spike 현상을 포착하기 위한 방법을 알아보았다. 그러나 gauge 메트릭만 다루었다는 점에서 한계가 있다. counter 타입 데이터에는 변화율 연산을 적용하기 때문에 aggregation_over_time을 사용할 수 없다. counter 타입의 메트릭까지 다루면 글이 너무 길어지기 때문에, 언젠가 후속 주제로 다루기로 한다. 기다릴 시간이 없다면 sub query와 recording rule을 검색해보길 권한다.
