
들어가며
수년간 인메모리 데이터스토어의 지배자였던 Redis의 위치가 라이선스 변경 이후로 위협받고 있다. 리눅스 재단의 Valkey, 마이크로소프트의 Garnet 등 수많은 솔루션이 자신이 '더 나은 Redis' 임을 주장하며 환승을 권하고 있다.
쏟아지는 Redis 대체제 중 하나가 DragonflyDB이다. 그들의 주장에 따르면 처리량 기준 Redis보다 25배의 성능을 발휘한다고 한다. 깃헙 저장소의 README에서 구현의 기반이 된 자료구조를 밝히고 있는데, 잠금 관리자는 VLL, 해시 테이블은 Dash라고 한다. 오늘의 포스팅은 이 중 VLL에 대해 소개한다.
다음의 분야에 대해 학부 수준의 배경지식이 있으면 글을 읽기 수월하다.
- 자료구조 개념 이해
- 해시테이블
- 연결리스트
- 큐
- 동시성과 잠금
- 데이터베이스
- 기본키
- 인덱스
- 데이터 파티셔닝
잠금 관리자의 전통적인 구현 방법과 문제점
(참고: DragonFlyDB에 쓰였다는 점을 보면 알 수 있듯이, VLL은 관계형 데이터베이스와 NoSQL에 모두 적용 가능한 자료구조이다. 그러나 이 포스팅에서는 엔지니어들에게 더 익숙할 확률이 높은 관계형 데이터베이스의 용어를 위주로 설명한다.)
전통적인 잠금 관리자는 전역으로 선언된 해시 테이블을 이용한다. 해시 테이블의 key는 레코드의 기본 키(primary key)이고 값은 해당 레코드에 대한 잠금 요청의 연결 리스트이다. 각 연결리스트는 한 번에 한 스레드만 접근할 수 있도록 mutex lock 을 가지고 있다.
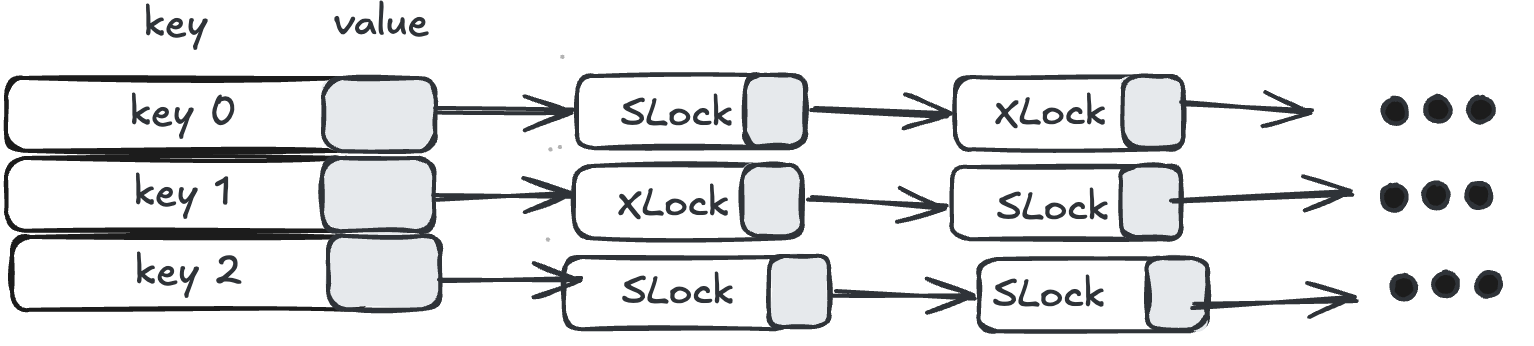
따라서 한 트랜잭션이 종료될 때마다, 다음 트랜잭션에게 잠금을 전달하기 위해 다음과 같은 작업을 수행해야 한다.
- 잠금이 반납된 레코드의 연결리스트에 대해, Mutex lock을 획득하고 임계 구역에 진입한다.
- 어떤 요청이 다음 Lock을 획득할지를 결정하기 위해 리스트를 순회한다.
- 결정된 요청에 잠금을 주고 임계 구역을 벗어난다.
디스크를 사용하는 전통적인 데이터베이스에서 임계 구역 진입과 리스트 순회의 오버헤드는 무시할만한 수준이었다. 그러나 인메모리 데이터베이스에서는 이 부분이 병목이 된다.
그냥 리스트의 선두에 있는 트랜잭션에 잠금을 주면 될 텐데 큰 오버헤드인가 싶을 수도 있다. 그러나 데이터 잠금이 공유 잠금(Shared lock)과 배타적 잠금(Exclusive lock)으로 나뉜다는 사실을 고려하면, 무조건 선두 트랜잭션에 잠금을 넘기는 방식은 큰 성능 손실을 유발할 수 있다.
예를 들어 현재 트랜잭션 A가 레코드 x에 대해 공유 잠금을 획득했다고 하자. 그리고 레코드 x의 잠금 요청 리스트에 트랜잭션 B, C, D가 순서대로 위치해 있다. B는 배타적 잠금을, C와 D는 공유 잠금을 요청한다. 트랜잭션 C, D는 A와 동시에 실행이 가능한 반면 B는 아니다. 만약 리스트를 순회해서 C와 D에게 잠금을 주지 않고, 선두에 있는 B에게 잠금을 주려 한다면 트랜잭션 A가 끝날 때까지 기다려야 한다.
VLL
잠금 변수와 트랜잭션 큐(TxnQueue)
VLL은 전역 잠금 관리자를 두지 않고 잠금 관련 정보를 레코드 별로 분산해서 저장한다. VLL에서 모든 레코드는 두 개의 정수형 변수 (Cs, Cx)를 함께 저장하는데, 각각 공유 잠금과 배타적 잠금을 요청한 트랜잭션의 수이다. 동시성 제어 방법은 운영체제의 세마포어와 동일하다. 잠금을 요청할 때 변수를 1 증가시키고, 트랜잭션을 종료할 때 변수를 1 감소시키는 방식이다. (Cs, Cx)는 데이터와 잠금 정보를 한 번에 빠르게 읽을 수 있도록 레코드와 물리적으로 인접한 곳에 저장된다.
잠금을 요청한 트랜잭션은 트랜잭션 큐(TxnQueue)에 삽입된다. 잠금 요청과 트랜잭션 큐 삽입은 모두 동일한 임계 구역(Critical section)에서 수행한다. 한 번에 하나의 트랜잭션만 잠금 요청과 큐 삽입을 할 수 있게 하기 위함이다. (여러 트랜잭션이 동시에 잠금 변수를 조작하게 되면 변수의 값이 의도치 않게 변화할 수 있다. 트랜잭션을 설명할 때 자주 나오는 은행 잔고의 예시를 생각하면 된다.)
VLL의 중요한 특징은 트랜잭션이 잠금을 요청해야 하는 모든 레코드를 임계 구역 이전에 모두 파악해 둔다는 점이다. 이러한 특징은 임계구역을 최소화해 동시성을 향상시킨다. 잠금 요청 레코드를 파악하는 방법은 글의 후반부에서 자세히 다루도록 하겠다.
잠금 요청과 큐 삽입이 완료되면, VLL은 다음의 두 가지 기준으로 트랜잭션을 분류한다.
- 지역(Local) 트랜잭션과 분산(Distributed) 트랜잭션을 구분한다. 지역 트랜잭션은 잠금을 요청해야 하는 레코드가 모두 하나의 파티션에 저장된 트랜잭션이다. 분산 트랜잭션은 여러 파티션에 저장되어 있는 트랜잭션이다.
- 잠금을 바로 획득할 수 있어서 즉시 실행해도 되는 트랜잭션은 실행 가능(Free) 트랜잭션, 그렇지 않으면 보류(Blocked) 트랜잭션으로 구분한다.
실행할 트랜잭션을 선별하는 방법
전통적인 구조에서는 전역 잠금 관리자가 잠금을 넘겨받고 실행될 다음 트랜잭션을 골랐다. VLL에는 전역 잠금 관리자가 없으므로 한 트랜잭션이 종료되었을 때 다음 트랜잭션에 직접 잠금을 넘겨줄 방법이 없다. 이를 보완하기 위해 TxnQueue에 존재하는 보류 트랜잭션들의 잠금 요청을 분석 후, 실행 가능한 트랜잭션을 선별하는 백그라운드 스레드를 실행한다.
이를 보완하기 위해 TxnQueue의 보류 트랜잭션을 순회하면서, 잠금을 획득할 수 있는 트랜잭션을 파악하는 백그라운드 스레드를 만든다. 예를 들어 트랜잭션 T1이 아이템 A의 Cx를 1 증가시킨 후 실행 보류 중이었다고 해보자. 현재 A의 Cx=1, Cs=0 이라면 A에 대해 배타적 잠금을 요청한 트랜잭션은 T1밖에 없다. 따라서 실행 가능한 트랜잭션이다. 공유 잠금에 대해서도 비슷한 연산이 가능하다. 트랜잭션 T2가 아이템 B의 Cs를 1 증가시킨 후 보류 상태였다고 하자. B의 Cx가 0이 되면 T2는 실행 가능하다. (꼭 큐의 선두 아이템만이 실행 가능한 것이 아니란 점에 주의하자. TxnQueue는 엄밀한 의미의 큐는 아니라고 할 수 있다.)
다시 말해 TxnQueue의 어떤 트랜잭션 T가 다음의 조건 중 하나에 부합하면 실행 가능하다.
- 해당 레코드에 배타적 잠금을 요청한 트랜잭션이 T밖에 없을 때
- 해당 레코드에 배타적 잠금 요청을 한 다른 트랜잭션이 없고, T가 요청한 잠금은 공유 잠금일 때
이 방식의 맹점은 교착 상태(Deadlock)가 발생할 수 있다는 점이다. 앞서 소개한 배타적 잠금의 예시로 돌아가서, 레코드 A의 배타적 잠금을 요청한 또 다른 트랜잭션 T3가 있었다고 해보자. A의 Cx는 2이다. T1과 T3는 자신의 잠금을 포기하지 않은 채로 Cx가 1이 되기만을 기다린다. 점유 대기와 환형 대기가 생겼으므로 교착 상태가 된다.
다행히 트랜잭션의 실행 방법을 하나 추가해서 교착 상태를 방지할 수 있다. TxnQueue의 선두에 있는 트랜잭션을 실행하면 된다. 선두 트랜잭션은 레코드의 (Cs, Cx) 값과 상관없이 언제나 실행 가능함이 보장되기 때문이다. 이는 다음과 같이 증명할 수 있다.
- 잠금 요청과 큐 삽입은 같은 임계구역 내에서 실행된다.
- 따라서 트랜잭션이 큐에 삽입된 순서는 곧 잠금을 요청한 순서와 같다.
- 따라서 큐의 선두 트랜잭션은 아직 실행되지 않은 트랜잭션 중 가장 먼저 잠금을 요청한 트랜잭션이다. Cs나 Cx의 값이 1 이상이더라도 모두 선두 트랜잭션보다 이후에 실행된 잠금 요청이다.
- 선두 트랜잭션보다 먼저 잠금을 요청한 트랜잭션이 없으므로 실행 가능하다.
이 정리에 의해 TxnQueue의 모든 트랜잭션은 언젠가 실행 가능함이 보장된다. 영원한 교착 상태가 발생하지는 않는 것이다.
TxnQueue의 크기를 제어하는 방법
많은 트랜잭션이 몰릴 경우 TxnQueue 의 크기는 점점 커진다. TxnQueue의 크기가 커질수록 개별 트랜잭션이 보류 없이 실행될 가능성이 낮아지기 때문에 크기를 인위적으로 제어할 필요가 있다. 큐의 크기가 임계치를 넘어가면 새로운 트랜잭션을 받는 것을 중지하고, 실행 가능한 트랜잭션을 찾아야 한다. 실행 가능한 트랜잭션을 찾는 방법은 앞 장에서 설명한 그대로다.
적절한 큐의 크기는 잠금의 경쟁도에 따라 다르다. 경쟁도를 단순히 시간당 트랜잭션이 얼마나 많은지로 정의할 수는 없다. 시간당 트랜잭션의 수가 많더라도, 트랜잭션이 접근하는 레코드가 모두 다르다면 문제없이 잠금을 획득할 것이다. 반대로 사용 빈도가 높은 인기 레코드, 이른바 Hot key에만 잠금 요청이 몰린다면 경쟁도가 높다고 볼 수 있다. 경쟁도가 높을 경우 TxnQueue에서 보류되는 트랜잭션이 더욱 많아지므로 큐의 크기를 작게 유지해야 한다. 논문에서는 큐의 크기를 직접 정하는 대신, 보류된 트랜잭션의 개수를 임계치로 삼을 것을 권하고 있다.
잠금 레코드 집합을 구하는 방법
앞서 VLL의 중요한 특징으로, 임계 구역에 진입하기 전 잠금을 요청할 레코드 집합을 모두 확정한다는 것을 들었다. 그런데 다음의 두 상황에선 잠금 레코드 집합을 미리 결정하기가 어렵다.
- 잠금 레코드 집합 중, 실제로 트랜잭션을 실행해야 알 수 있는 것이 있을 때. 대표적으로 보조 인덱스(Secondary index)를 사용해 조회하는 경우를 들 수 있다. 기본 인덱스(Primary index)는 레코드가 저장된 물리적 위치와 연관되었을 가능성이 높지만 보조 인덱스는 아니다. 직접 조회 연산을 실행하기 전까지는 잠금 대상이 되는 레코드를 알 수 없는 경우가 많다.
- 트랜잭션이 여러 파티션의 레코드를 사용할 때. 각 파티션은 별도의 TxnQueue를 가지고 있고 잠금도 파티션에 국한해 획득한다. 따라서 같은 트랜잭션이더라도 실행되는 시점이 파티션 별로 다를 수 있다. 같은 트랜잭션이 어떤 파티션에서는 실행 가능 상태이고, 어떤 파티션에서는 보류 상태라면 교착 상태가 발생할 수 있다. 예를 들어 파티션 P1의 레코드 A와 P2의 레코드 B를 사용하는 트랜잭션 T1, T2가 있다고 해보자. T1이 A의 잠금을, T2가 B의 잠금을 먼저 획득해버리면 교착 상태가 된다.
첫 번째 문제를 해결하기 위해, 트랜잭션은 잠금을 요청하기 전 필요한 조회를 모두 실시한다. 임계 구역 밖에서 격리 없이 실행한 조회이기 때문에 막상 실행 시점에는 잠금 집합이 달라질 수 있다. 예를 들어 이메일 도메인이 gmail.com 인 회원에 대해서만 레코드를 업데이트하는 트랜잭션 T가 있다고 하자. T는 회원 테이블에서 이메일 도메인이 gmail.com인 회원의 목록을 조회하고, 이 회원들의 레코드에 잠금을 요청한다. 그런데 잠금 요청 시점과 실제 트랜잭션이 실행되는 시점 사이에 회원 가입이 발생해 지메일을 사용하는 회원이 하나 더 늘었다고 해보자. 트랜잭션 T는 실행 시점이 되어서야 잠금을 획득하지 못한 회원 레코드가 있다는 사실을 알게 된다.
이처럼 잠금 집합이 달라져서 필요한 잠금을 획득하지 못하는 경우, 트랜잭션의 실행은 중단되고 변경 내용이 커밋되지 않는다. 트랜잭션은 잠금 집합 결정과 잠금 요청을 완전히 처음부터 다시 수행한 후 TxnQueue에 들어간다. 다행히 달라진 것이 없다면 트랜잭션은 그대로 실행된다.
교착 상태에 대응하는 방법은 두 가지가 있다. 하나는 교착 상태의 발생을 탐지하고, 교착 상태에 놓인 트랜잭션을 강제 종료하는 방식이다. 나머지 하나는 교착 상태가 발생하지 않도록 모든 파티션에서 트랜잭션의 실행 순서가 같도록 조정하는 것이다. 논문에서는 두 번째 방법을 택했다. 멀티 파티션 트랜잭션의 경우 ACID를 보장하기 위해 사용하는 2PC 와 같은 프로토콜이 제일 주요한 병목이기 때문이다. 잠금 관리자가 파티션 별 실행 순서를 정렬하는 정도의 시간은 이에 비하면 크게 문제가 되지 않는다.
VLL의 트레이드오프
VLL에서 실행 가능한 트랜잭션은 백그라운드 스레드가 선별한 트랜잭션과 큐의 선두 트랜잭션뿐이다. 그런데 백그라운드 스레드는 오로지 잠금의 개수만을 세고 잠금을 요청한 순서는 모르기 때문에, 실행 가능 상태인 트랜잭션을 보류해야 한다고 판단할 가능성이 있다. 이는 전통적인 잠금 관리자에 비해 동시성을 저하시킨다.
어떤 트랜잭션이 실행 가능한 상태인데도, 뒤늦게 같은 레코드에 잠금을 요청한 다른 트랜잭션 때문에 보류되는 예시를 보자. 트랜잭션 A, B, C, D가 순서대로 요청되었고, 트랜잭션에서 쓰기 잠금을 요청한 집합(Write set)은 다음과 같다.
| Txn | Write set |
|---|---|
| A | x |
| B | y |
| C | x, z |
| D | z |
트랜잭션 A, B가 현재 실행되고 있다고 하자. 종료되지 않았기 때문에 TxnQueue에도 남아 있다. C가 배타적 잠금을 요청한 x는 A가 이미 점유하고 있기 때문에 보류된다. D도 C가 이미 z의 잠금을 요청했기 때문에 보류된다. 그리고 A의 실행이 종료되었다고 가정해 보자. 요청 큐를 사용하는 전통적인 전역 잠금 관리자와 VLL의 동작을 차례로 설명하면 다음과 같다.
요청 큐 방식
A가 실행 중일 때 큐의 상태는 다음과 같다.
| Key | Request queue |
|---|---|
| x | A, C |
| y | B |
| z | C, D |
A가 실행 종료되고 나선 다음과 같이 변한다.
| Key | Request queue |
|---|---|
| x | C |
| y | B |
| z | C, D |
x와 z의 큐에서 모두 C가 선두에 있다. 따라서 트랜잭션 C는 실행 가능하다.
VLL
A가 실행 중일 때 잠금 변수의 값은 다음과 같다.
| Key | Cx | Cs |
|---|---|---|
| x | 2 | 0 |
| y | 1 | 0 |
| z | 2 | 0 |
A가 실행 종료되고 나선 다음과 같이 변한다.
| Key | Cx | Cs |
|---|---|---|
| x | 1 | 0 |
| y | 1 | 0 |
| z | 2 | 0 |
z의 Cx 가 2이기 때문에 C는 보류 상태가 된다. D는 C보다 늦게 잠금 요청을 했다는 사실을 기억하자. 잠금 요청의 개수만 기록하였을 뿐, 순서는 기록하지 않았기 때문에 요청 큐 방식에 비해 동시성 수준에서 손해를 본 것이다. 잠금의 경쟁도가 높을수록 손해의 정도는 더욱 늘어난다.
SCA(Selective contention analysis)
SCA는 VLL의 동시성 저하를 최소화 하고 CPU를 최대한 효율적으로 사용하기 위해 도입한 자료구조이다. SCA는 요청 큐를 사용하는 잠금 관리자 처럼 잠금을 넘겨줄 트랜잭션을 직접 찾는다.
모든 잠금을 직접 넘겨주는 요청 큐 방식과 달리, SCA는 VLL이 CPU를 효율적으로 사용하지 못할 때에만 활성화 된다. VLL이 CPU를 효율적으로 사용하지 못하는 상황은 TxnQueue가 가득차 있고, 잠금 변수만으로는 다음 트랜잭션을 고를 수 없을 때이다. 이때 VLL은 선두 트랜잭션을 실행하는 방식에 의존할 수 밖에 없게 된다. 이럴 때엔 일시적으로 잠금을 직접 관리하는 오버헤드를 부담하는 것이 오히려 전체 성능에 도움이 된다.
트랜잭션이 보류되는 이유는 이전에 같은 레코드에 잠금을 요청한 다른 트랜잭션 때문이다. 어떤 트랜잭션 T가 TxnQueue의 i번째 아이템이라면, T와 충돌 가능성이 있는 트랜잭션은 i-1개이다. 따라서 트랜잭션이 큐의 선두에 가까우면 가까울수록 보류 상태일 확률은 점점 낮아진다.
SCA는 큐의 트랜잭션을 차례대로 순회하면서, 100KB 크기의 비트 배열 Dx, Ds 를 업데이트 한다. 이 비트 배열은 해쉬 함수를 이용해 레코드의 잠금 여부를 기록하는 역할을 한다. 처음에는 모든 모든 비트가 0인 상태로 초기화 되어있다.
만약 어떤 트랜잭션이 레코드 X, Y에 대해 배타적 잠금 요청을, Z에 대해 잠금 요청을 했다고 하자. hash(X) = x, hash(Y)=y, hash(Z)=z 라 할 때, Dx[x], Dx[y]와 Ds[z]를 1로 업데이트 한다.
이렇게 하면 현재까지 순회한 트랜잭션들이 어떤 레코드에 잠금을 요청했는지가 빠짐없이 배열에 기록될 것이다. 만약 SCA가 현재 조회중인 트랜잭션 T가 다음 조건을 모두 만족한다면, T는 즉시 실행 가능하다.
- T의 배타적 잠금 요청 집합에 포함된 모든 레코드에 대해 Dx[hash(key)] = 0
- T의 공유 잠금 요청 집합에 포함된 모든 레코드에 대해
- Dx[hash(key)] = 0
- Ds[hash(key)] = 0
SCA는 다음과 같은 이유 때문에 효과적이다.
- 모든 트랜잭션에 관여하며 오버헤드를 발생시키는 전통적인 잠금 관리자와는 달리 꼭 필요한 시점에만 실행된다.
- 가장 실행 가능성이 높은 순서대로 조회한다. (앞서 설명한대로, 큐의 선두에 가까울수록 충돌 가능성이 낮기 때문에 큐에 삽입된 순서가 곧 실행 가능성의 순서이다.)
Dx와 Ds의 크기가 100KB로 한정되었기 때문에, 해시 충돌이 일어날 가능성이 있음에 주의하자. 해시 충돌 때문에 실제로는 잠기지 않은 아이템이 잠긴 것으로 오판될 수 있다. 이는 트랜잭션을 불필요하게 보류시키는 결과(False negative)로 이어질 수 있다. 단 실행이 불가능 한 트랜잭션을 가능한 것으로 판단하는 False positive 는 발생하지 않는다.
이러한 단점에도 Dx, Ds의 크기를 100KB로 설정한 이유는 256KB 크기의 L2 캐시보다 작은 크기로 설정해 캐시 히트율을 높이기 위함이다.
마치며
오늘의 포스팅에선 DragonFlyDB에서 채택한 VLL 자료구조에 대해 알아 보았다. 이해하기 쉽도록 예시를 추가하면서도 글의 분량을 작게 유지하기 위해 핵심이 아니라고 생각되는 Single thread VLL, Arrayed VLL, VLLR 등의 내용은 생략하였다. VLL 자료구조에 대해 호기심이 생겼다면 원본 논문을 공부해보길 권한다.
참고 문헌
VLL: a lock manager redesign for main memory database systems
