확장이란 서비스가 더 큰 규모의 부하를 감당할 수 있도록 규모를 키우는 것을 말한다. 이 글에서는 토이 프로젝트로 시작한 서비스의 규모를 점점 키우는 예시를 통해, 서버를 확장하는 방법을 살펴본다.
대학생 김덕배 씨가 졸업 과제로 덕배넷이라는 간단한 웹 서비스를 개발하고 있다고 생각해보자. 아직은 개발 단계이기 때문에 덕배넷에 접속하는 사람은 김덕배 씨와 그의 팀원 뿐이다. 아직은 다음의 그림 같은 소박한 구조로도 잘 동작한다.
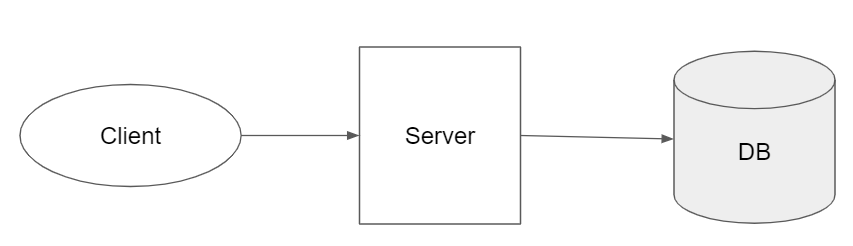
졸업 과제로 만든 서비스에 트래픽이 몰리는 일은 거의 없기 때문에 김덕배 씨는 이 정도로 프로젝트를 마무리하려 했다. 그러나 어쩐 일인지 서비스가 갑자기 유명해져서 학생들이 몰리기 시작했다.
최대한 버티는 방법
아직 아키텍처를 변경하기에는 부담스럽다. 김덕배 씨는 기존의 구조를 최대한 최적화해서 대응하기로 마음 먹는다.
알고리즘 개선
코드를 살펴 보던 팀장은 김덕배 씨가 작성한 부분에 문제가 있음을 깨닫는다. 해시에 두어야 할 데이터를 배열에 저장하고 있었던 것이다. 조회 시 O(n)이던 시간 복잡도가 O(1)로 줄어들면서 덕배넷의 성능은 크게 개선되었다.
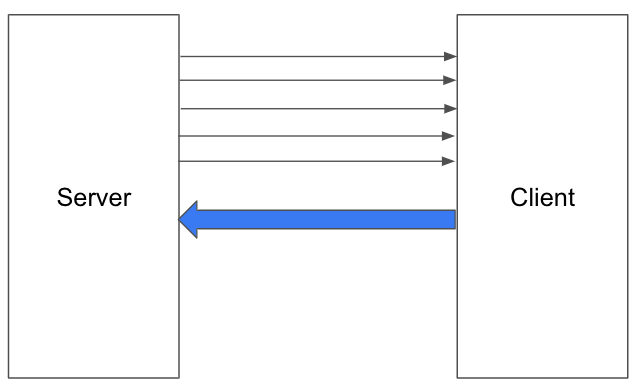
팀장은 다른 팀원이 작성한 클라이언트 코드에서도 개선점을 찾았다. 반복문 안에서 서버와 패킷을 주고 받는 코드였다. 서버가 요청에 응답할 때까지 기다렸다가, 응답이 온 다음에야 다음 번 루프를 진행하고 있었다. 5개의 요청과 응답을 주고 받는 예를 들면 다음 그림과 같다.

sum(전송 시간) + sum(회신 시간)만큼의 시간이 걸림을 알 수 있다. 팀장은 이 부분을 비동기 통신으로 최적화 하였다. 매번 응답을 기다리지 않고 한 번에 모든 패킷을 보내는 방식이다. 응답은 루프가 끝난 뒤에 한 번에 받는다. 실행 시간이 sum(전송 시간) + max(회신 시간) 으로 개선되었다.
자료구조나 알고리즘에 근본적인 변화가 있을 경우 성능은 매우 획기적으로 개선된다. GTA5에서, 배열을 해시로 대체해서 로딩 시간을 70퍼센트 줄인 사례가 있다. 그러나 본인의 코드에서 이런 개선점을 찾아내는 것은 매우 어려운 일이다. 이번 패치는 김덕배 씨보다 실력이 뛰어난 팀장이 있었기 때문에 가능했다. 김덕배 씨에게 알고리즘을 획기적으로 개선할 혜안이 있었다면 애초에 그렇게 만들지 않았을 것이다.
데이터베이스 개선
덕배넷의 데이터베이스에는 인덱스가 없어서, SELECT 연산을 할 때마다 테이블의 모든 행을 읽었다. 적절한 컬럼에 인덱스를 생성하였더니 DB 조회가 훨씬 빨라졌다. 김덕배 씨가 서버에서 사용하는 쿼리의 패턴을 잘 알기 때문에 가능한 일이었다. 테이블이나 컬럼을 잘못 선택했다면 인덱스를 만들어도 별 소용이 없었을 것이다.
김덕배 씨는 사용자들이 이벤트 게시판을 매우 자주 조회하는 것을 알게 되었다. 김덕배 씨는 이벤트 게시판의 내용을 DB에서 저장해두었다가 읽는 대신 메모리에 캐싱하기로 결정하였다. ARCUS를 이용해 캐싱하였더니 조회 성능이 크게 개선 되었다. 이벤트 게시판의 내용은 수정될 일이 거의 없어 대부분의 요청이 히트 하였기 때문이다.
Scale up
이러한 조치에도 유저 수가 점점 늘어나자 기존의 장비로는 감당하기 힘들게 되었다. 김덕배 씨는 더 좋은 하드웨어에서 서버를 구동하기로 마음먹었다. 새로운 장비에는 기존보다 더 빠른 CPU, 더 큰 메모리, HDD 대신 SSD를 달았다. 더 좋은 성능의 서버로 교체해 처리량을 늘리는 방식을 Scale up이라고 한다.
Scale out으로 확장하기
최적화나 Scale up을 무한정 반복할 수는 없다. 병목이 되는 비효율적인 알고리즘을 수정하고, 데이터베이스 쿼리를 튜닝하고, 더 좋은 하드웨어를 구하더라도 언젠가는 한계에 봉착한다. Scale out이 필요한 순간이다.
Scale out은 하나의 강력한 서버를 쓰는 대신, 비슷한 성능의 서버 여러 대가 힘을 합치는 방식이다. 하나처럼 움직이는 서버의 집합을 클러스터라고 하고, 클러스터를 구성하는 각각의 서버를 노드라고 한다.
Scale up의 예


Scale out의 예

부하 분산(Load balancing)
김덕배 씨가 서버 수를 늘렸는데도 대부분의 사용자들은 기존의 서버에만 계속 접속하였다. 북마크에 추가해 둔 주소를 바꾸기 귀찮았기 때문이다. 이렇게 부하가 고르게 분산되지 않고 한 곳으로 몰린다면 확장을 하는 의미가 없다.
Scale out을 했다면 사용자가 서버에 직접 접속하는 대신 서버들에게 부하를 분산해주는 로드 밸런서(Load balancer)에 접속하게 해야 한다. 사용자는 기존의 주소를 계속 사용하기 때문에 확장 이전과 이후의 차이를 느끼지 못한다.
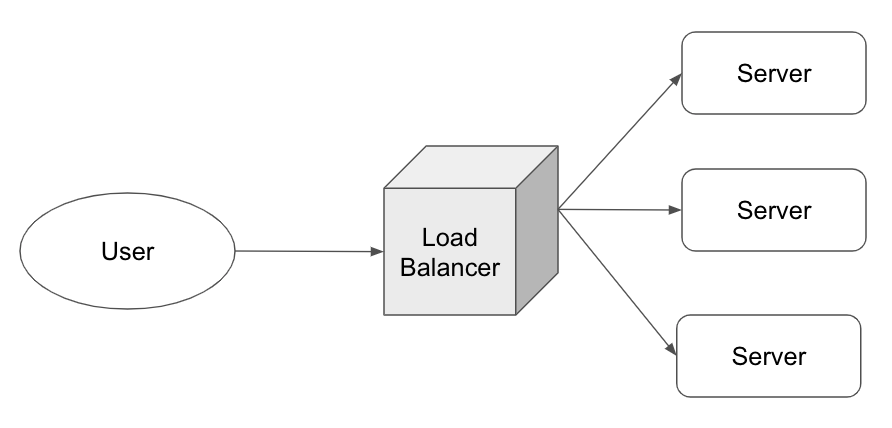
Stateless 응용의 분산
덕배넷의 WAS는 사용자의 요청을 받아 데이터베이스에 CRUD를 수행한다. 모든 정보는 데이터베이스에 저장되어 있기 때문에, WAS에서 따로 기억해두는 데이터는 없다. 기존의 정보를 저장하지 않는 특징을 Stateless라고 한다. 반대로 기존의 정보를 저장해두고 사용한다면 Stateful이라고 한다.
Stateless 응용을 분산하는 방식은 Stateful 보다 훨씬 쉽다. 한번 씩 번갈아 가면서 할당해주기만 해도 공평하게 분산된다. 이런 방식을 라운드 로빈(round robin)이라 한다.
Statless 서버의 장점은 분산이 편하다는 것 뿐만이 아니다. 어느 서버에 접속해도 똑같은 서비스가 보장되기 때문에, 서버 한 두 개가 다운되더라도 서비스를 계속 제공할 수 있다. 로드 밸런서가 서버 다운을 인지하고, 다운된 서버로는 부하를 할당해주지 않는다면 사용자는 서버가 다운되었음을 전혀 느낄 수 없다. 이처럼 사용자가 인지하는 고장을 최소화 하는 특성을 고가용성(HA-High Availability)라고 한다.

그러나 무조건 Stateless로 만드는 것이 능사는 아니다. Stateful로 운영하는 것이 더 성능이 좋은 경우가 있을 수 있고, 때로는 Statless 설계가 아예 불가능할수도 있기 때문이다. 데이터베이스나 캐시 같은 응용은 Stateful 할 수 밖에 없다.
Stateful 응용의 분산
데이터베이스나 캐시 같은 Stateful 응용을 분산하는 것은 훨씬 더 어렵다. 부하 뿐만 아니라 데이터도 분산해야 하기 때문이다. 사용자가 찾으려는 데이터는 1번 데이터베이스에 저장되어 있는데 로드 밸런서가 3번 데이터베이스로 연결해준다면 분명히 존재하는 데이터인데도 조회할 수 없게 된다. 만약 조회가 아닌 생성 요청이었다면 똑같은 key를 가진 데이터가 두 개 이상 생성될수도 있다. 이러한 특성 때문에 Stateful 응용의 부하 분산은 사실상 데이터 분산 방식에 의해 결정된다.
Ranged sharding
key의 범위에 따라 데이터를 분산한다. ID 1번부터 10000번까지는 1번 데이터베이스, 10001번부터 20000번까지는 2번 데이터베이스에 저장하는 식이다.
Ranged sharding을 사용하면 데이터베이스를 증설할 때 기존 데이터를 옮길 필요가 없다. 데이터 이관의 비용을 감안하면 꽤 큰 이점이다. 그러나 부하가 고르게 분산된다는 보장이 없다는 단점이 있다. 예를 들어 게시판 테이블을 ID 기반으로 ranged sharding을 했다고 생각해보자. 대부분의 DB 쿼리는 최근 게시물에만 몰려 있을 것이다.
hashed sharding
key를 해싱한 값에 따라 데이터를 분산한다. hashed sharding의 대표적인 방법 중 하나가 나머지 연산을 이용한 분산이다. key의 해쉬값을 서버의 수로 나눈 나머지에 따라 데이터를 분산한다. 나머지가 0이면 1번 DB, 1이면 2번 DB, 2이면 3번 DB에 배정된다.

range sharding보다 특정 노드에만 부하가 몰릴 확률이 훨씬 낮지만, 클러스터 증설시 데이터 이관 비용이 발생한다는 문제가 있다. 위의 사례에서 데이터베이스 하나가 추가될 경우 hash(key) mod 3 대신 hash(key) mod 4 연산을 해야 한다. 클러스터 안에 10개의 데이터가 저장되어 있고, 각 데이터의 해쉬 값은 1~10 이었다고 해보자. 나머지 연산의 결과가 다음의 표와 같이 달라진다.
| hash(key) | mod 3 | mod 4 |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 2 | 2 |
| 3 | 0 | 3 |
| 4 | 1 | 0 |
| 5 | 2 | 1 |
| 6 | 0 | 2 |
| 7 | 1 | 3 |
| 8 | 2 | 0 |
| 9 | 0 | 1 |
| 10 | 1 | 2 |
데이터베이스의 수가 하나 늘어났을 뿐인데도 분배가 많이 달라지는 것을 알 수 있다. 분배가 달라진 key는 기존 DB에서 새로운 DB로 옮겨야 한다. 데이터 이관을 줄이기 위한 consistent hashing 과 같은 방법이 있지만, 이관을 아예 하지 않을 수는 없다.
결론
학생 수준의 프로젝트에서 Scale out을 통한 확장이 필요한 경우는 거의 없다. 그러나 실제 트래픽이 발생하는 프로젝트라면 설계 시점부터 확장에 대한 고려를 하는 것이 좋다. 최적화 자체가 어려운 작업일 뿐더러, 단일 서버에서 아무리 최적화를 하더라도 한계가 있기 때문이다.
데이터베이스는 분산하기 매우 어려운 프로그램이다. 본문에는 key를 분산하는 알고리즘에 대해서만 적었지만 실제로는 고려해야할 점이 훨씬 많다. 특히 관계형 데이터베이스를 분산하려면 매우 신중한 설계가 필요하다. 자세한 내용을 알고 싶다면 샤딩에 대해 검색해보길 권한다.

wow