* 프로그래머스, 타입스크립트로 함께하는 웹 풀 사이클 개발(React, Node.js) 5기 강의 수강 내용을 정리하는 포스팅.
* 원활한 내용 이해를 위해 수업에서 제시된 자료 이외에, 개인적으로 조사한 자료 등을 덧붙이고 있음.
1. 제약조건Constraints
-
데이터베이스에서 테이블의 데이터 무결성을 유지하고 유효한 데이터를 보장하기 위해 사용되는 개념.
-
테이블 생성 시 또는 테이블 수정 시 정의할 수 있다.
주요 제약조건
PRIMARY KEY
- 테이블에서 각 행을 고유하게 식별.
- NULL 값 불허, 중복 값 불허.
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(50)
);FOREIGN KEY
- 다른 테이블의 Primary Key를 참조하여 테이블 간 관계를 정의.
- 참조 무결성을 보장.
CREATE TABLE orders (
order_id INT PRIMARY KEY,
user_id INT,
FOREIGN KEY (user_id) REFERENCES users(id)
);NOT NULL
- 특정 컬럼이 NULL 값을 가질 수 없도록 제한.
CREATE TABLE products (
product_id INT PRIMARY KEY,
product_name VARCHAR(100) NOT NULL
);UNIQUE
- 컬럼 값이 고유해야 함.
- NULL 값은 중복으로 간주하지 않음.
CREATE TABLE employees (
emp_id INT PRIMARY KEY,
email VARCHAR(100) UNIQUE
);DEFAULT
- 컬럼에 값이 지정되지 않을 경우 기본값을 설정.
CREATE TABLE accounts (
account_id INT PRIMARY KEY,
balance DECIMAL(10, 2) DEFAULT 0.00
);CHECK
- 컬럼 값이 특정 조건을 만족해야 함.
CREATE TABLE students (
student_id INT PRIMARY KEY,
age INT CHECK (age >= 18)
);auto_increment_lock_mode
-
AUTO_INCREMENT 필드의 동작 방식을 제어하는 시스템 변수.
-
AUTO_INCREMENT은 새로 데이터가 생성되었을 때, DBMS에서 자동으로 숫자를 하나씩 넘겨서 저장해주는 속성.
-
테이블에 AUTO_INCREMENT 필드가 있을 때, 동시에 여러 트랜잭션이 삽입(INSERT) 작업을 수행하면 경합이 발생할 수 있다.
- 요청이 동시에 여럿 발생하게 되었을 때, 과연 순차적으로 1.. 2.. 3.. 순서대로 숫자가 붙을 수 있는가?에 대한 문제. -
이를 제어하기 위해 MySQL은
auto_increment_lock_mode를 사용하여 AUTO_INCREMENT 값 생성 방식과 잠금 동작을 설정할 수 있도록 되어있다.
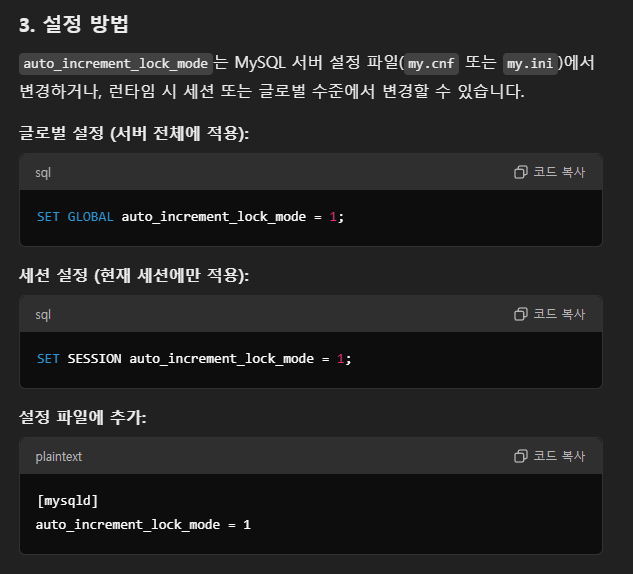
0 (Traditional Mode)
- 테이블 수준에서 AUTO_INCREMENT 값을 생성할 때 테이블 락을 사용합니다.
- 트랜잭션 간 동시성 지원이 제한적.
- 동시 삽입 작업이 많지 않은 환경 / MySQL의 MyISAM 스토리지 엔진에서 적합.
1 (Consecutive Lock Mode - Default)
- InnoDB 스토리지 엔진의 기본 모드.
- AUTO_INCREMENT 값을 생성할 때 트랜잭션에서 INSERT 작업이 완료되기 전까지 해당 값이 예약됩니다.
- 트랜잭션이 롤백되어도 AUTO_INCREMENT 값은 사용되지 않고 소모됩니다.
- 동시 삽입 작업이 많고, 값이 연속적일 필요가 없는 경우에 적합.
2 (Interleaved Mode)
- AUTO_INCREMENT 값 생성에서 테이블 락을 사용하지 않고 일련의 트랜잭션 내에서 동시성을 최대화.
- 트랜잭션이 확정(commit)될 때 AUTO_INCREMENT 값을 확정합니다.
- 트랜잭션이 롤백되면 값이 재사용되지 않습니다.
- 대규모 동시 삽입 작업이 빈번한 환경에서 성능을 극대화하고 싶을 때에 적합.
2. 테이블 데이터 타입
-
각 컬럼은 데이터를 저장하기 위해 특정 데이터 타입(Data Type)을 정의해야 한다.
-
데이터 타입은 저장할 데이터의 종류와 크기를 결정한다.
주요 데이터 타입
숫자형 데이터 타입
-
INT: 정수형 데이터.
-
DECIMAL(M, D): 소수점이 있는 고정 소수점 데이터.
price DECIMAL(10, 2);
-
FLOAT, DOUBLE: 부동 소수점 데이터.
문자열 데이터 타입
-
CHAR(n): 고정 길이 문자열 (n자 크기 고정).
postal_code CHAR(5);
-
VARCHAR(n): 가변 길이 문자열 (최대 n자).
email VARCHAR(100);
-
TEXT: 긴 텍스트 데이터를 저장.
날짜와 시간 데이터 타입
- DATE: 날짜 (YYYY-MM-DD 형식).
birth_date DATE;
- DATETIME: 날짜와 시간 (YYYY-MM-DD HH:MM:SS).
- TIME: 시간 (HH:MM:SS).
이진 데이터 타입
- BLOB: 대량의 이진 데이터를 저장 (예: 이미지, 비디오).
BOOLEAN 데이터 타입
- BOOLEAN: 참(True) 또는 거짓(False)을 저장.
is_active BOOLEAN;
3. JOIN!
-
두 개 이상의 테이블을 연결하여 원하는 데이터를 하나의 결과 집합으로 결합하는 SQL 연산.
-
테이블 간의 관계를 기반으로 데이터를 조회할 때 사용한다.
INNER JOIN
- 두 테이블에서 공통적으로 매칭되는 데이터만 반환.
SELECT a.name, b.order_date
FROM users a
INNER JOIN orders b ON a.id = b.user_id;LEFT JOIN (LEFT OUTER JOIN)
- 왼쪽 테이블의 모든 데이터와, 매칭되는 오른쪽 테이블 데이터를 반환. 매칭되지 않는 오른쪽 데이터는 NULL로 표시.
SELECT a.name, b.order_date
FROM users a
LEFT JOIN orders b ON a.id = b.user_id;RIGHT JOIN (RIGHT OUTER JOIN)
- 오른쪽 테이블의 모든 데이터와, 매칭되는 왼쪽 테이블 데이터를 반환. 매칭되지 않는 왼쪽 데이터는 NULL로 표시.
SELECT a.name, b.order_date
FROM users a
RIGHT JOIN orders b ON a.id = b.user_id;
FULL JOIN (FULL OUTER JOIN)
- 두 테이블의 모든 데이터와 매칭되는 데이터를 반환. 매칭되지 않는 데이터는 NULL로 표시.
- MySQL은 FULL JOIN을 지원하지 않으므로 UNION을 사용.
SELECT a.name, b.order_date
FROM users a
LEFT JOIN orders b ON a.id = b.user_id
UNION
SELECT a.name, b.order_date
FROM users a
RIGHT JOIN orders b ON a.id = b.user_id;CROSS JOIN
- 두 테이블의 데이터 간의 모든 조합(카티션 곱)을 반환.
SELECT a.name, b.product_name
FROM users a
CROSS JOIN products b;JOIN 예제
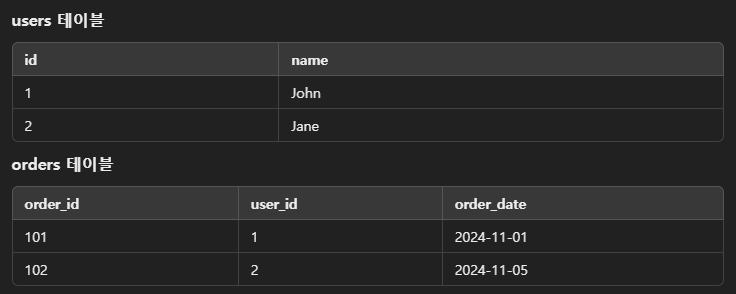
- users, orders의 2개의 테이블이 존재한다고 가정해보자.
SELECT u.name, o.order_date
FROM users u
INNER JOIN orders o ON u.id = o.user_id;
SELECT u.name, o.order_date
FROM users u
LEFT JOIN orders o ON u.id = o.user_id;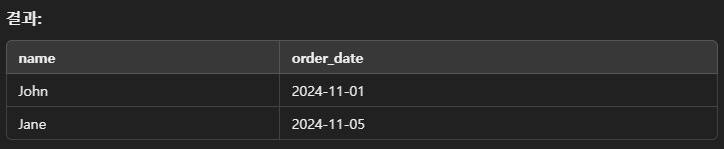
- JOIN 연산의 결과는 위와 같이 출력된다.
3. 1주기 회고
-
데브코스 과정의 첫번째 주기를 마쳤다.
-
아무래도 초반부이기도 하고, 이전에 개인 프로젝트들을 진행하면서 한 번 이상 공부했던 내용들이 많았어서 매우 편안한 시기이기도 했다.
-
다만, 역시 체계적인 커리큘럼에 따라서 백엔드를 배워나가다보니 내가 혼자 공부했을 때 놓치거나 잘못 알고있던 부분들도 많았다. 이래서 데브코스를 선택한 것이었는데, 다행히 그 선택이 옳았던 것 같다.
-
아는 내용이라고 해도, 구글링과 GPT를 통해 주변 지식으로 뻗어나가는 가지들을 빠짐없이 포스팅에 기록하고 있다. 단시간에 많은 내용을 다루다보니 머리가 아플 때가 있지만, 블로그 내용이 풍성해질수록 나중에 다시 되돌아보기가 쉬워지니 참 좋은 일이다.
