최근에 이직한 회사에서 Datalake 관련 프로젝트가 진행되어 기존 산업에서 구성한 여러가지 다양한 사례를 분석하였고, 여러가지 방법 중 데이터 AWS에서 제공하는 DMS를 이용하여 On-Prem의 데이터를 Full Load로 땡기는 방법에 대한 아이디어가 나와서 튜토리얼(?)로 한번 진행할 겸 영구 기억을 위한 문서도 함께 작성해본다.
AWS DMS 관련 구성 및 사용 방법은 AWS 사용자 설명서를 참고하여 진행해보았다.
(URL : https://docs.aws.amazon.com/dms/latest/userguide/CHAP_GettingStarted.Replication.html)
- 복제 인스턴스 생성
아래 이미지와 같이 데이터 복제를 위한 복제 인스턴스를 Setting한다. FullLoad 테스트 목적이기 때문에 인스턴스는 T3.small로 설정하였다.
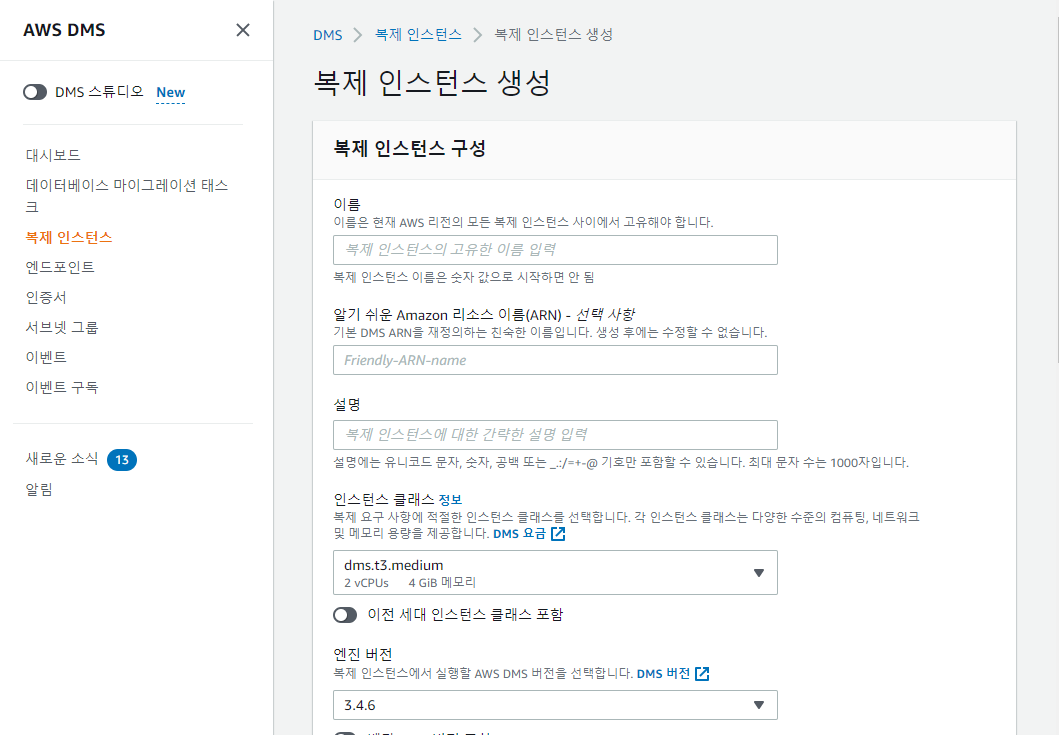
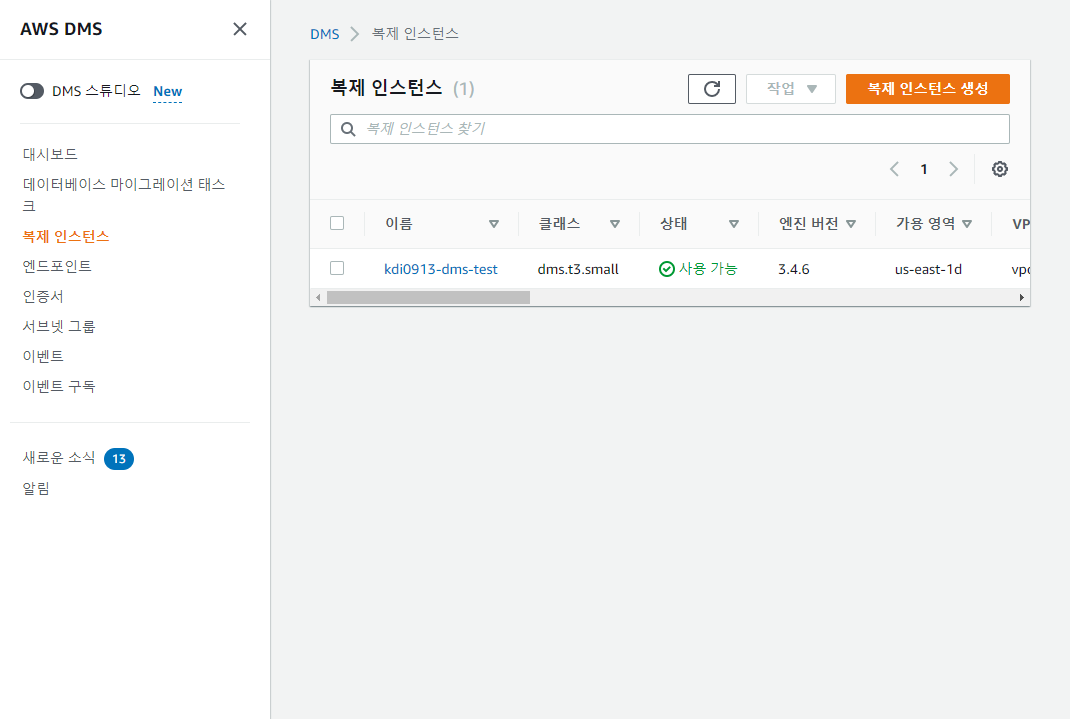
결과
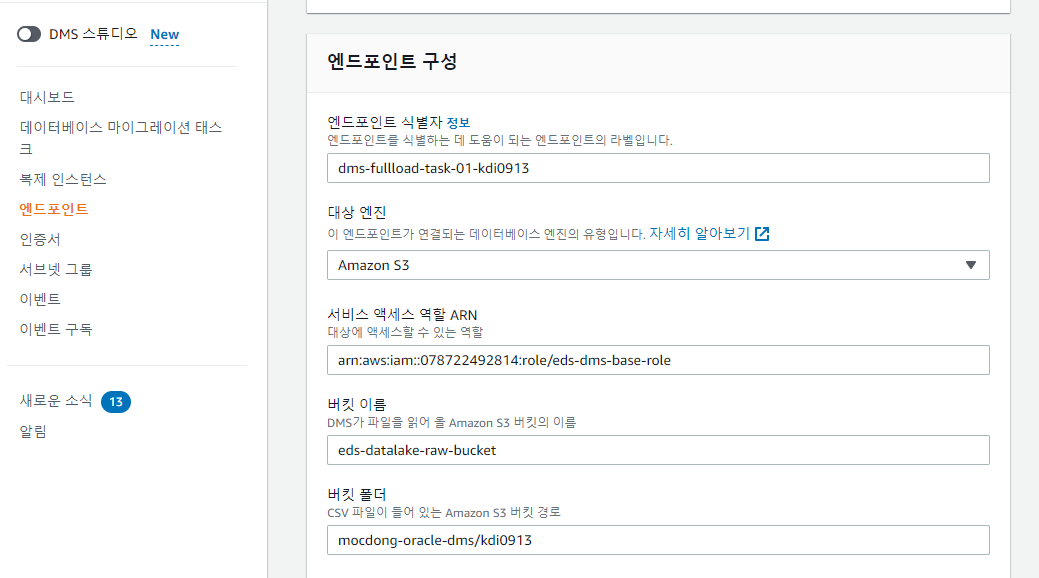
- source and destination End point 지정
아래 이미지와 같이 데이터를 가지고 있는 원천source 엔드 포인트 및 타겟이 되는 destination 엔드 포인트를 설정한다.
나의 경우에는 source 엔드 포인트는 on-prem에 존재하므로 on-prem 서버 정보를 확인하여 작성하였고, destination 엔드 포인트는 아래 이미지 처럼 S3에 데이터를 땡겨오도록 설정하였다.
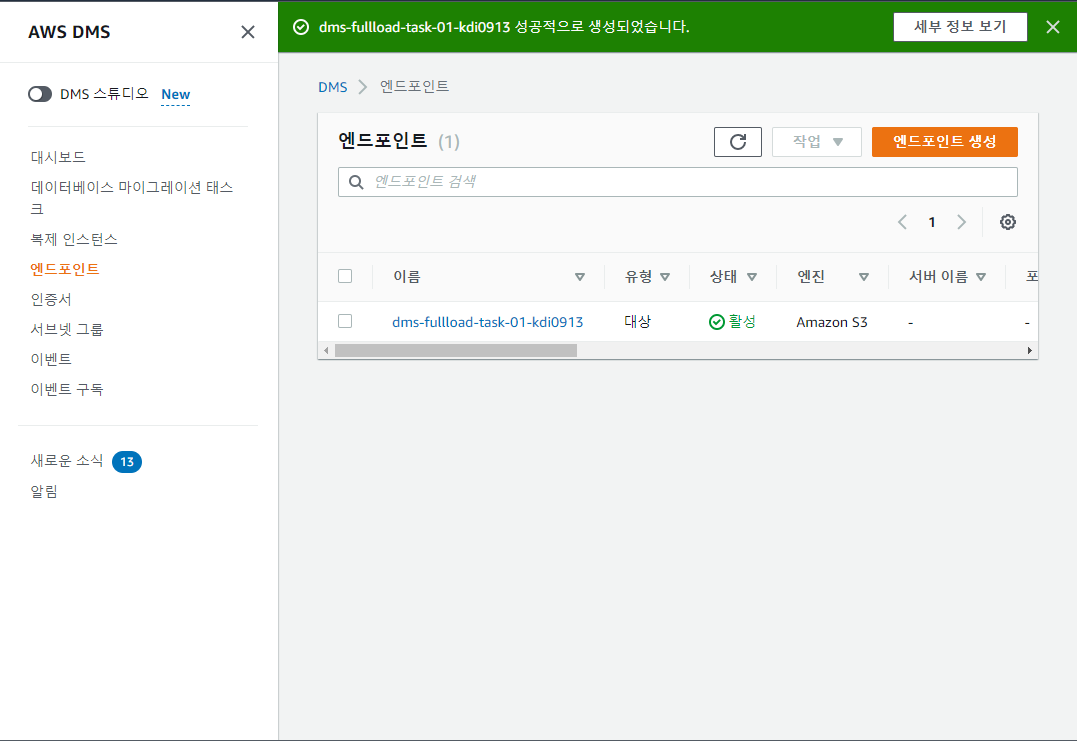
결과
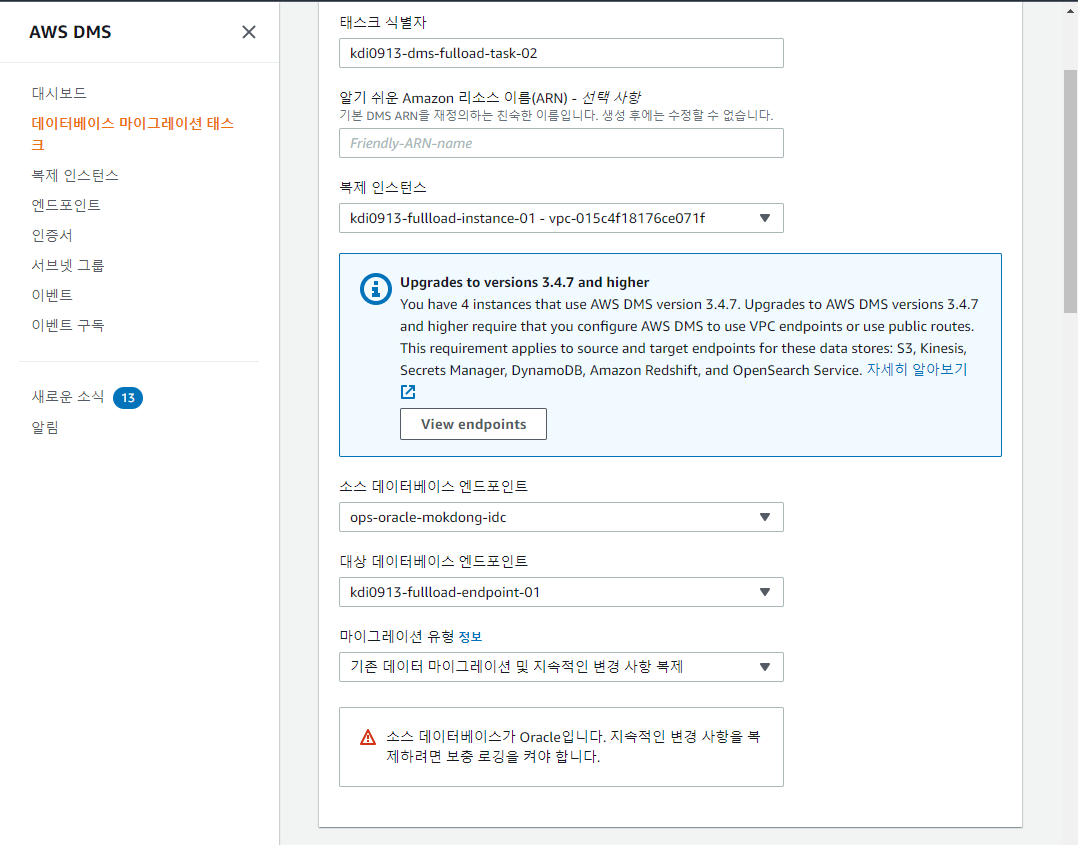
- 마이그레이션 태스크 생성
source와 destination 엔드 포인트가 설정되었고, 복제 인스턴스가 생성이 되었으면, 마이그레이션 태스크를 생성하여 데이터를 full Load한다.
아래 이미지와 같이 복제 인스턴스를 이용하여 원본 source의 엔드 포인트로부터 데이터를 full Load하여 설정한 S3 경로로 마이그레이션한다.
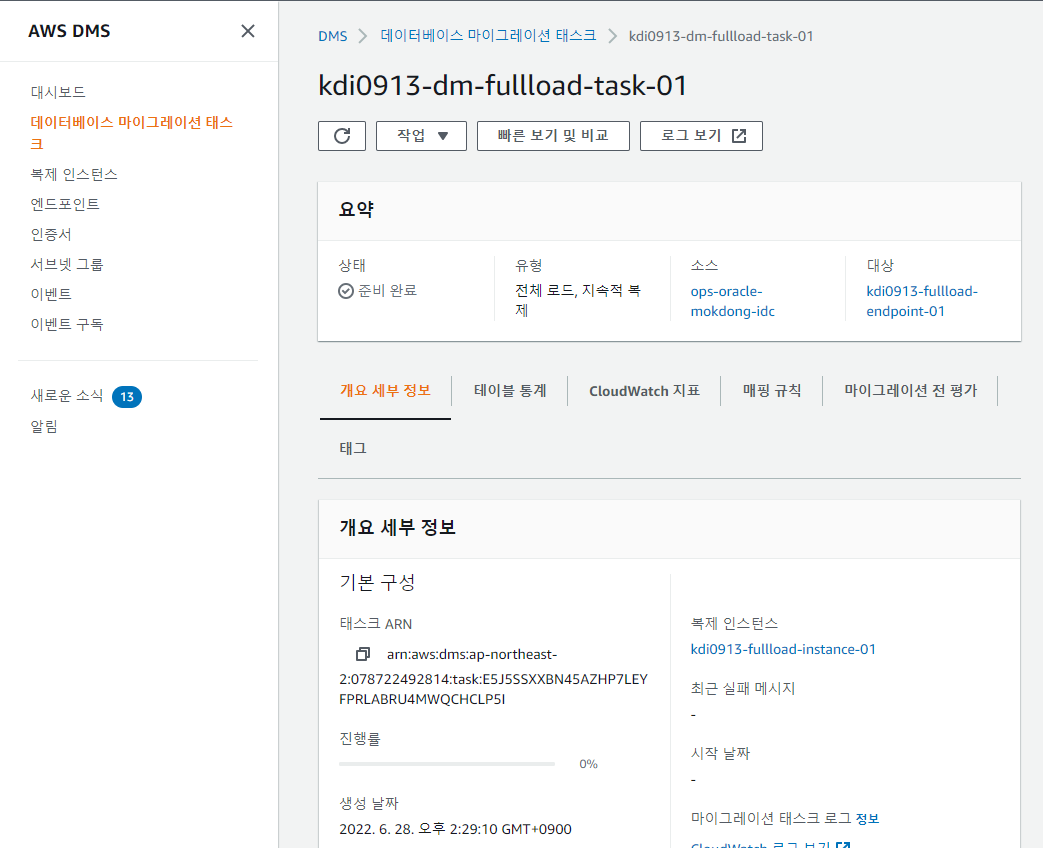
결과
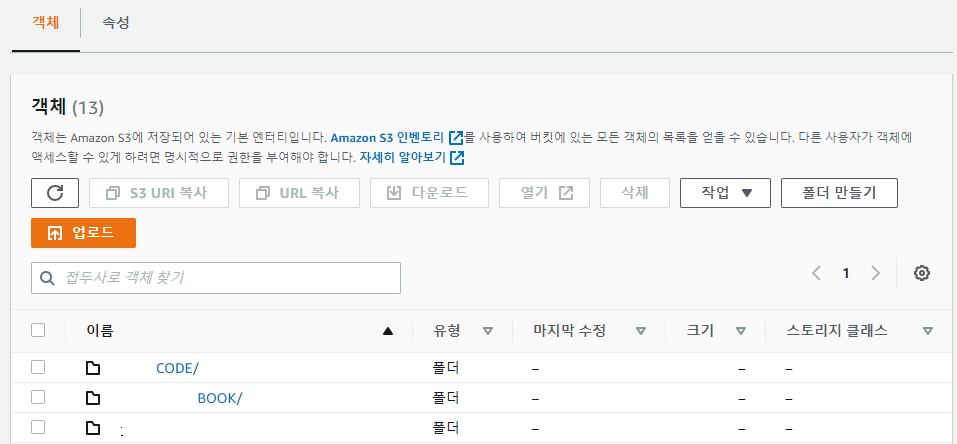
이렇게 설정한 후 마이그레이션 태스크를 실행하면 내가 지정한 S3경로에 데이터 Full Load된 것을 확인할 수 있다.
최종결과
Check Point
-
복제 인스턴스 생성 시 아무리 작은 Spec의 인스턴스로 생성 요청을 하더라도 최소 20~30분 후에 사용 가능하다. 혹시나 오랜 시간 기다렸는데도 사용 가능 상태가 아닌 경우는 오류(?)가 아니니 인내를 가지고 기다려야 한다.
-
마이그레이션 태스크 생성에서 테이블 매핑 정의 시 Full Load할 선택 규칙을 최소 하나 이상 정의해야 하며 본인이 선택한 인스턴스의 Spce 범위 내에 Full Load 가능한 데이터 범위를 산정 후 설정해야 한다.
데이터 수집 범위가 적을 경우에는 마법사로도 충분히 정의할 수 있지만, task 내 수집 범위가 많을 경우에는 JSON 편집기로 정의할 수 있다.
(마이그레이션 태스크 또한 생성 시간이 오래 걸리는 것을 참고하기 바란다.)
작성 예시)
{
"rules": [
{
"rule-type": "selection",
"rule-id": "1", //rule 단위로 순차 처리 하므로, rule-id는 유니크해야 한다.
"rule-name": "1",
"object-locator": {
"schema-name": "원본 데이터베이스 스키마명",
"table-name": "원본 데이터베이스 테이블명"
},
"rule-action": "include",
"filters": []
}
:
]
}