지난 편에 생성형 AI 공부를 위한 토이 프로젝트의 컨셉과 핵심 프로세스에 대해 설명하였다. 이번 편에서는 구체적으로 각 프로세스 별로 어떻게 개발했는지를 공유하고, TO-DO(?) 같은 것을 기록해보려 한다. 전반적인 구성 방법은 Langchain Document를 참고하여 개발하였다.
지난 편에 대한 내용은 아래 URL을 참고하시면 됩니다.^^
https://velog.io/@skypentum/series/%EC%83%9D%EC%84%B1%ED%98%95-AI-%EA%B3%B5%EB%B6%80%EB%A5%BC-%EC%9C%84%ED%95%9C-%ED%86%A0%EC%9D%B4-%ED%94%84%EB%A1%9C%EC%A0%9D%ED%8A%B8-%EC%A7%84%ED%96%89
각 프로세스별 개발 과정
1. Dataset 구성을 위한 RAG 데이터 구축
개발 과정 :
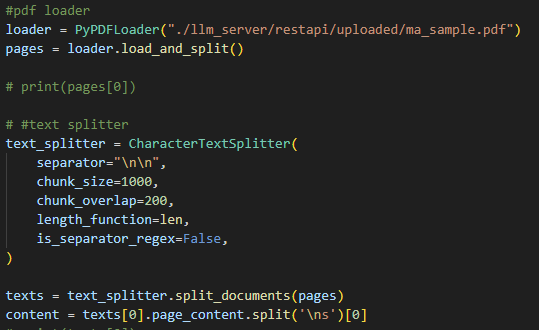
기 존재하는 개념 정리 및 문제를 가진 임의의 PDF파일을 string으로 변환하여 Vector DB에 저장하기 위한 Dataset 구성을 진행하였다. Langchain Document에 보면 PDF 파일을 String으로 변환해 주는 PDFLoader와, string을 설정한 chunk zise로 잘라줄 수 있는 TextSplitter 두가지 모듈을 이용하였다.
Trobleshooting :
PDFLoader : 해당 모듈이 모든 PDF를 원하는 형태의 String으로 변환해 주지는 못한다. 이번 토이 프로젝트에서 파악된 PDFLoader의 기능은 PDF 내용물이 일반 text로 구성되어 있을 경우 수월하게 변환이 되지만, 템플릿 형태나 내용상에 이미지가 포함되는 경우 정상적으로 변환하기 어려운 이슈가 있다. PDFLoader를 기능을 계승한 새로운 모듈이 있는지 추가적인 확인이 필요하다.
TextSplitter : 사용자 지정으로 chunk size 설정이 가능하지만, 인입된 text 내 문장 길이는 인입될 때 마다 다르기 때문에, 인입된 text에 따라 chunk size를 자동화로 구성하기에는 약간의 허들이 있어 보인다. 이 부분을 자동화 할 수 있는 idea가 필요하다.
2. Vector DB 구성
개발 과정 :
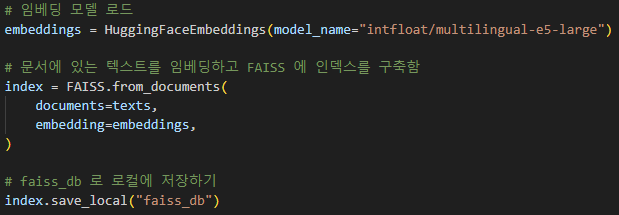
HuggingFace에서 제공하는 LLAMA2 임베딩 모델인 multilingual-e5-large을 이용하여 기 존재하는 개념 정리 및 문제에 대한 vector data를 생성하고, 이를 메모리 vector DB인 faiss db 에 저장함
Trobleshooting :
토이 프로젝트 상에서는 메모리 vector DB를 사용하였기 때문에, 데이터 변경 또는 추가 시 매번 vector data를 구성하고 faiss db에 저장하는 번거로움이 있다. 이 부분은 vector DB로 관리할 수 있는 PostgresQL나 Elasticsearch를 이용하여 영구적인 DB로 구성하고 메모리 vector DB에 caching 방법도 괜찮을 듯 하다.
3. 문제 생성
개발 과정 :
아래 두가지 방법 중 현실 적으로 구축 가능한 방법을 선택하여 구성하였다. 지난 편에서도 이야기 했지만, 나는 백엔드 개발자이고, data scientist 영역을 자세하기 알지 못하여 case2를 선택했다.
case 1. vector DB를 바탕으로 FineTuning을 진행하여 Custom 모델을 생성하는 방법
case 2. HuggingFace에서 제공하는 llama-2-7b-chat.Q4_K_M.gguf 모델과 vector DB를 조합해서 사용
(설정 값 : 유사도 0.7, top_p : 1, max token : 8192, n_ctx : 4096)Trobleshooting :
case 1을 못한 이유 : LLAMA 2를 이용한 finetuning 방법을 나름(?) 스터디한 후 튜토리얼을 해보았으나, finetuning을 위한 data가 임의로 구성한 pdf 내용(20문제)으로는 정확도가 현저하게 떨어져서, 해당 케이스는 데이터를 좀더 확보한 후 다시한번 진행해 보려한다.
case 2의 경우 llama-2-7b-chat.Q4_K_M.gguf 모델이 약 3.6G를 차지하여, 소스코드도 굉장히 무겁고, GPU가 없는 나의 노트북에서 문제 생성을 하는데 시간이 약 3~5분 정도 소요 된다. 확실히 CPU 기반 보다 GPU 기반이 더 빠르게 동작한다는 것을 다시한번 느낀다 ㅠㅠ.
(외장 GPU 디바이스 스테이션을 구매해야 하나...? 가격이 30~40 한다 ㅠㅠ.)
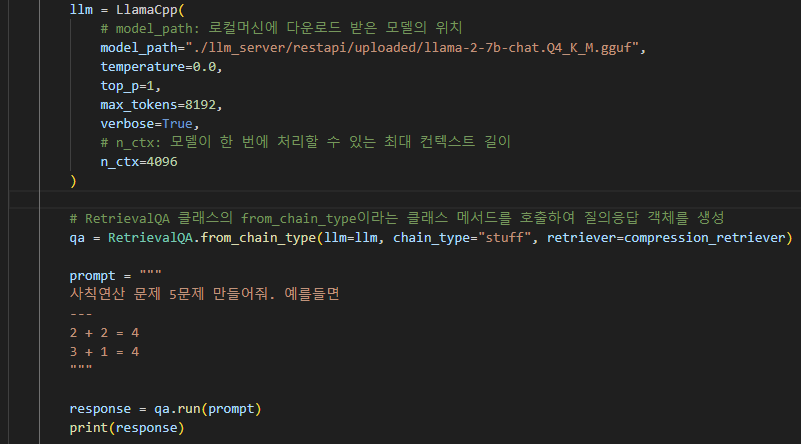
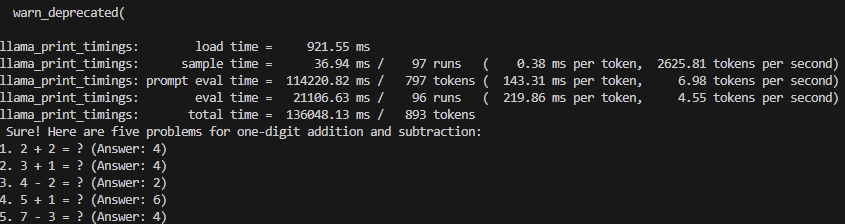
Langchain에서 제공하는 RetrievalQA을 이용하여 생성형 질의 응답 모듈을 구현한 결과는 아래와 같다.
4. 이미지 생성
개발 과정 :
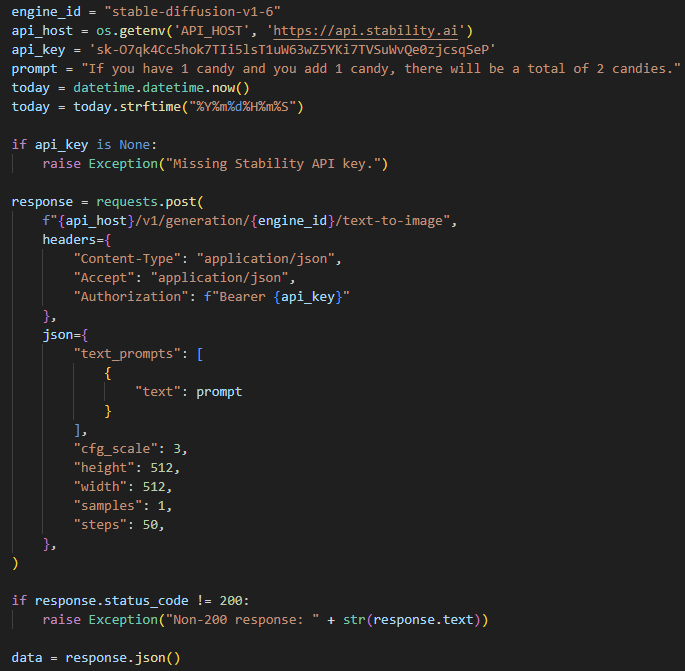
개념 설명에 대한 이미지를 생성하기 위하여. Stability.AI사에서 제공하는 Stable diffusion API를 이용하여 이미지를 생성하였다. 이를 위해 Stable diffusion에 회원 가입을 진행하였으며, Stable diffusion API Document를 참고하여 API 모듈을 구축 하였다.
(최초 회원 가입하면 20 Token을 무료로 제공한다.)
Trobleshooting :
이미지 생성을 위한 프롬프트가 굉장히 구체적이어야 한다. 그렇지 않으면 최초 받은 20 token이 순식간에 사라질 것이다.(이후에는 비용을 내고 추가 token을 구매해야 한다 ㅠㅠ.)
5. 어플리케이션 개발
개발 과정 :
- Frontend : jQuery와 bootstrap를 이용하여 간단한 템플릿 구현
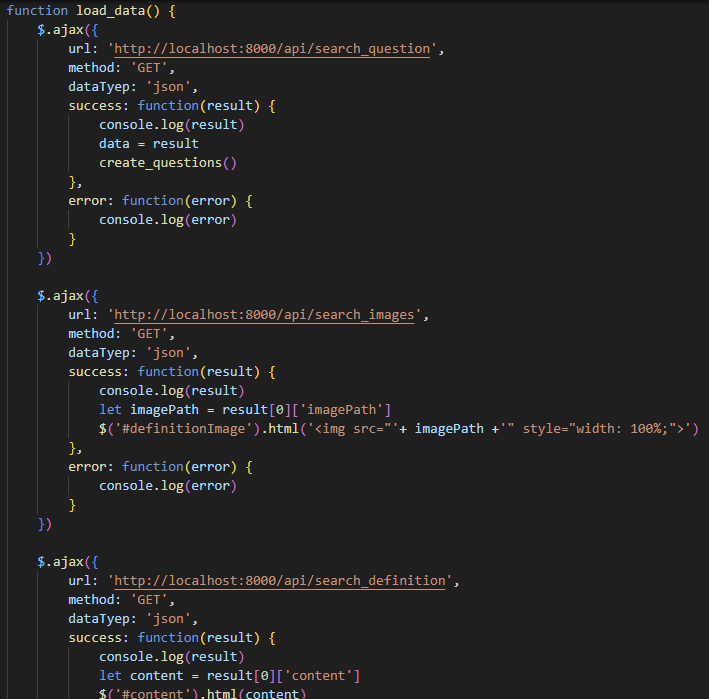
- DB : 테이블 설계
- Backend : Django 프레임워크를 이용하여 API 구축
1. 설계된 테이블 정보를 MariaDB에 물리적으로 생성 2. 생성형 AI API 구성 및 생성 데이터를 DB에 저장 3. 생성된 개념 이미지 및 문제를 조회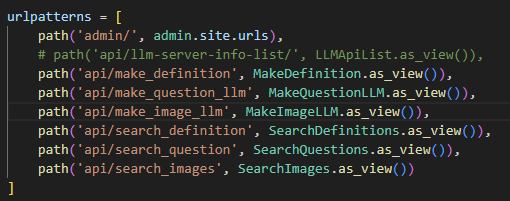
이렇게 개발된 어플리케이션 결과는 다음과 같다.

TO-DO
이렇게 해서 간략한 토이 프로젝트를 구현해 보았다. 1월 초에 갑작스럽에 아이디어가 떠올라서 1월 2주 부터 2월 초까지 약 한 달 정도 소요되었고, Langchain Document에서 제공해주는 문서의 질이 퀄리티가 높아서 쉽게 사용할 수 있었던 것 같다.
(실제 물리 시간은 3일 정도 걸린듯 하다...)
오랜 경험의 짬(?)으로 느낀점은, 생성형 AI에 관심이 있다면 이론적인 개론 및 특징을 스터디만 하신다면 데이터 사이언티스트와 협업하여 시스템 통합을 빠르고 쉽게 할 수 있을 거라 생각한다.
(정말...??)
아무튼, 생성형 AI의 개략적인 개론과 시스템 통합에 대한 뼈대를 공부하면서 구성한 김에 우리 아이들(?)에게 실제적으로 경험해 줄 수 있도록 위의 trobleshooting을 최대한 해결해 보면서 구성해 보려 한다.
(집에 초등학교 재학 및 입학예정자 둘이 있어 공부 시켜야 해요 ㅠㅠ.)
추가적인 내용이 나오면 공유하겠다.
두서없이 적었지만 끝까지 읽어주셔서 감사합니다 ^^.
참고
https://python.langchain.com/docs/get_started/introduction
https://platform.stability.ai/docs/api-reference
https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGUF
https://m.blog.naver.com/weisoon/223197297424

안녕하세요 Simon님 : )
컨텐츠 둘러보다가 작가님을 알게 되어 답글 남깁니다.
AI 애플리케이션 개발에 필요한 데이터 인프라를 하나로 통합한 데이터베이스를 만들고 있는 데이터베이스 스타트업 Cognica 입니다.
금번에 토이 프로젝트에서 faiss db 통해서 구현하셨는데요,
Cognica는 C++ 기반 OLTP 데이터베이스 위에 Secondary index를 통해 텍스트 검색과 벡터 검색을 모두 구현하여, 단일의 데이터베이스 만으로 RAG 구성이 가능합니다. 데이터 저장소간 동기화, 클러스터링, 샤딩 등의 작업이 전혀 필요가 없어 매우 빠르게 인프라를 구축할 수 있습니다.
Simon님 콘텐츠를 보고 초기 베타 테스터로 모시고 싶어서 댓글을 남겨드립니다.
현재 설치형 파일로 모든기능을 무료로 사용할 수 있는데요, 테스트와 피드백을 부탁드리고 싶습니다.
관련하여 궁금하신 점이 있으면 언제든 tim@cognica.io 로 편히 연락 주시면 됩니다!