COVID-19 Interpretable Diagnosis Algorithm Based on a Small Number of Chest X-Ray Samples
BU Ran (卜 冉), XIANG Wei∗ (向 伟), CAO Shitong (曹世同)
(Key Laboratory of Electronic and Information Engineering,
State Ethnic Affairs Commission (Southwest Minzu University), Chengdu 610041, China)
ABSTRACT
<문제>
- COVID-19에 기반한 개인 흉부 X-선(CXR)을 사용한 의료 진단 방법은 초기 연구에서 어려움을 겪었음
- → COVID-19 감염자의 CXR 데이터를 식별하는 데 어려움
- → 연구 초기에는 감염자의 CXR 데이터가 부족
<해결>
- 인공 지능(AI)과 의료 진단의 결합
- → AI 모델의 해석 가능성 분석을 사용하여 COVID-19에 감염된 CXR 샘플의 병변 특성을 탐색하고 의료 진단을 지원
- 오버피팅을 피하기 위해 데이터 증가 기법을 사용해 데이터셋 확장
- 전이학습
- → 다양한 사전 훈련된 모델을 테스트
- → 소수 샘플로 모델 훈련을 완료하기 위해 독특한 출력 레이어를 설계
<결과>
- 세 가지 다른 출력 레이어에서 네 가지 사전 훈련된 모델의 출력 결과를 비교
- 데이터 증가 후의 결과를 원래 데이터셋의 결과와 비교
- 24개 그룹의 독립적인 테스트를 수행하기 위해 제어 변수 방법 사용
→ 99.23%의 정확도와 98%의 리콜률이 얻어지고 CXR 해석 가능성 분석의 시각적 결과가 표시
<정리>
- COVID-19 진단 알고리즘 네트워크는 높은 일반화 및 가벼운 특성을 가짐.
- → 빠른 속도로 다른 작업에 적용 가능
- → 실험 데이터가 부족한 경우에도 유용
- 해석 가능성 분석은 의료 진단에 새로운 가능성을 제공
INTRODUCTION
<1> 문제상황 : 흉부 X선(CXR) 데이터가 심각하게 부족한 상황
- COVID-19의 빠른 전파 속도와 식별이 어려운 특수한 병리학적 특징으로 인해, 2019년 말 과학적 연구에 활용할 수 있는 COVID-19 환자의 흉부 X선(CXR) 데이터가 심각하게 부족한 상황을 겪음
<폐렴>
- 폐렴은 임상에서 매우 흔하나 정확한 진단은 어려운 작업 → CXR에서 증가된 투명도의 영역으로 나타남
- 폐렴진단 : 의료 전문가가 CXR 샘플 조사, 과거병력, vital signs, 의료 실험 결과
- COVID-19 시점, 전 세계적으로 의사와 의료 자원이 매우 부족했음
- → 의료 전문가의 시간을 절약하기 위해 대상 지능형 분석 시스템을 개발하는 것에 대한 의의가 있었음
<2> 상황 : 인공 지능(AI)과 의학의 결합
- 대규모 데이터의 지원을 받아, 인공 지능(AI)과 의학의 결합의 효율적 발전
- 기존 감지 방법과 비교했을 때, AI 알고리즘 검출은 이차 감염의 위험을 피하기 위해 더 효율적이고 저렴
- 데이터가 부족한 상황에 대처하기 위해 소수의 샘플을 다루는 방법을 탐구
—> AI 모델의 조건
소량의 데이터, 신속한 훈련, 편리한 적용
<3> AI를 활용한 COVID-19 진단에서의 해석 가능성 연구
- 인공지능의 응용이 "블랙 박스"로 여겨지며 대량 데이터로 훈련된 네트워크는 인간이 이해하기 어려운 특성을 기반으로 판단
- 흉부 X선(CXR) 진단은 COVID-19 세부 정보를 시각적으로 확인하는데 어려움이 있어서 의사들이 증상을 신속하게 평가하고 진단하기 어려움
- AI 모델을 사용하여 개인의 감염 여부뿐만 아니라 AI 시스템이 진단에 사용하는 기준을 탐구
- 해석 가능성 연구를 통해 의사들이 COVID-19 감염 여부를 판단하는 데 도움을 주고, "AI 의사"가 CXR에서 감염 가능성이 있는 위치를 식별하고 의사들에게 진단 지원을 제공.
- 해석 가능성의 추가는 모델의 판단 기준을 이해하는 데 도움뿐만 아니라 AI 시스템 분석 방법이 인간과 다르다는 중요성을 강조.
- AI 모델이 표시한 의심스러운 감염 위치에서 COVID-19의 대표적인 병변 특성을 찾는 것은 의미있는 기여가 될 것으로 기대됨.
<4> COVID-19 대응을 위한 경량화된 AI 모델의 성공적인 개발
- 배경:
- 대부분의 의료 AI 성과는 많은 데이터를 기반으로 하고 있지만, COVID-19는 예상치 못한 새로운 상황으로, 소수의 과학 연구용 의료 이미지 데이터만 사용 가능한 문제점 존재
- 모델 선택:
- 깊은 구조의 네트워크도 있지만 현재 경우와는 적합하지 않다고 판단되어, 경량화와 효과적인 성능을 갖는 VGG16 네트워크 선택
- 데이터 부족 대응:
- 다양한 실험과 비교를 통해 VGG-16 네트워크가 선택되었지만, 몇 개의 데이터로는 완전한 VGG16 네트워크를 훈련시키기 어려워 전이 학습이라는 개념 도입
- ImageNet에서 사전 훈련된 VGG16 네트워크의 가중치를 사용
- 모델 개선:
- VGG16 네트워크의 원래 완전 연결 레이어를 개선
- VGG16 구조를 유지하면서, 성능을 개선하고자함
- 합성곱 레이어의 가중치를 고정하고 완전 연결 레이어를 개선된 구조로 변경
-
네트워크 합성곱 레이어의 가중치 고정 → 미리 학습된 가중치를 유지하면서, 다른부분을 개선하고자,,
-
완전 연결 레이어를 개선된 구조로 변경
→ 평균 풀링 레이어 (Average Pooling Layer):
-
풀링은 공간의 크기를 줄이고, 계산 비용을 감소시키기 위해 사용
-
평균 풀링은 각 영역의 평균 값을 계산해 특정 영역의 대표값을 생성
-
평균값을 사용함
-
→ 밀집 레이어 (Dense Layer):
- 밀집 레이어는 모든 입력 뉴런과 출력 뉴런이 서로 연결된 완전 연결 레이어
- 각 입력과 출력 간의 가중치가 있고, 활성화 함수를 통해 출력을 생성
- —> ReLU 활성화함수 사용
-
ReLU 활성화 함수
- 가장 일반적으로 사용되는 활성화 함수 중 하나로 입력이 양수인 경우 그 값을 그대로 출력, 음수인 경우 0으로 출력
- 이 함수는 비선형성을 도입하면서도 연산을 간단하게 유지
-
→ 배치 정규화 (Batch Normalization):
- 신경망의 학습 속도를 높이고 안정화시키기 위해 사용되며, 각 미니배치의 입력을 평균과 표준편차로 정규화해, 스케일 및 시프트 파라미터를 사용하여 레이어의 출력을 조정
-
→ 드롭아웃 (Dropout):
- 훈련 중 무작위로 선택한 일부 뉴런을 제외하고 학습하는 방법
- 네트워크가 특정 뉴런에 지나치게 의존하지 않도록 하여 과적합을 방지
-
→ 밀집 레이어(소프트맥스 활성화함수):
- 다중 클래스 분류를 위한 소프트맥스 활성화 함수를 사용
- 각 클래스에 대한 확률 분포를 출력
-
- VGG16 네트워크의 원래 완전 연결 레이어를 개선
- 실험과 비교:
- 많은 실험과 비교를 통해 개선된 네트워크는 적은 양의 데이터로도 좋은 결과를 얻을 수 있다는 것을 확인했으며, 25epochs 훈련만으로도 수렴하며 일반적인 딥러닝 모델에 비해 적은 훈련 시간이 필요함을 확인
- 활용 가능성:
- 경량 네트워크 구조와 빠른 훈련 과정으로, CPU만 사용하여 10분 이내에 작업을 완료할 수 있어, 발전이 덜 된 지역에서 더 의미 있는 기여를 할 수 있음
RELEVANT WORK
1.1 COVID-19와 VGGNet
- 의료와 AI의 결합의 가장 중요한 기여는 의사들의 반복된 작업을 줄이는 데 있으며, 적절한 네트워크는 흉부 엑스레이 데이터를 통해 정상과 감염된 개인을 높은 정확도로 구별 가능
-
깊은 합성곱 신경망으로, 합성곱 신경망의 깊이와 성능 간의 관계를 탐구
-
3×3 합성곱 커널과(합성곱 신경망에서 사용되는 필터의 크기) 2×2 최대 풀링 레이어를 반복적으로 쌓아 16~19개의 레이어로 이루어진 합성곱 신경망을 구축
-
3 × 3 합성곱 코어와 2 × 2 풀링 코어를 사용하여 네트워크 구조를 깊게 만들어 성능을 향상시킴
-
네트워크 레이어의 증가는 매개 변수의 폭발을 일으키지 않음 —> 매개변수는 주로 마지막 세 개의 완전 연결 레이어에 집중되기 때문
완전연결 레이어(Fully Connected Layer)는 합성곱 신경망의 마지막 부분에 위치한 레이어로 이전의 합성곱과 풀링 레이어를 통해 추출된 특징들을 입력으로 받아 분류나 예측을 수행한디. 이 완전 연결 레이어에는 많은 수의 가중치(parameter)가 존재하며 , 이 가중치들이 신경망의 학습을 통해 조정된다.
** 그런데 VGGNet의 구조에서는 매개변수가 주로 마지막 세 개의 완전 연결 레이어에 집중되는 경향이 있다.
즉, 이 세 개의 레이어는 매개변수의 수가 많고, 신경망의 파라미터 중 상당 부분을 차지하며, 이후의 학습과 예측에 큰 영향을 미치는 중요한 부분이다.
따라서, VGGNet에서는 처음부터 끝까지 모든 레이어에서 매개변수가 고르게 분포되는 것이 아니라, 주로 마지막 세 개의 완전 연결 레이어에 집중되는 특징이 있어, 네트워크 구조의 효율성을 높이고 계산 비용을 줄이는 데 도움을 주는 요소가 된다.
-
두 개의 3×3 합성곱 레이어를 연속으로 연결하는 것은 5×5 합성곱 레이어와 동일
-
세 개의 3×3 합성곱 레이어를 연속으로 연결하는 것은 7×7 합성곱 레이어와 동일
-
즉, 세 개의 3×3 합성곱 레이어의 수용 영역은 7×7 합성곱 레이어와 동일
-
—> 그러나 3×3 합성곱 레이어의 매개변수는 7×7의 약 절반에 불과하며, 3×3 조합은 세 개의 비선형 연산을 갖기 때문에 전자의 구조가 더 많은 특징을 학습할 수 있음
-
VGGNet은 특징 추출과 전이 학습 작업에 사용되며,가장 많이 사용되는 모델은 VGG-16과 VGG-19로, 각각 16개와 19개의 레이어를 나타냄(VGG-16과 VGG-19을 테스트 백본으로 선택한 이유)
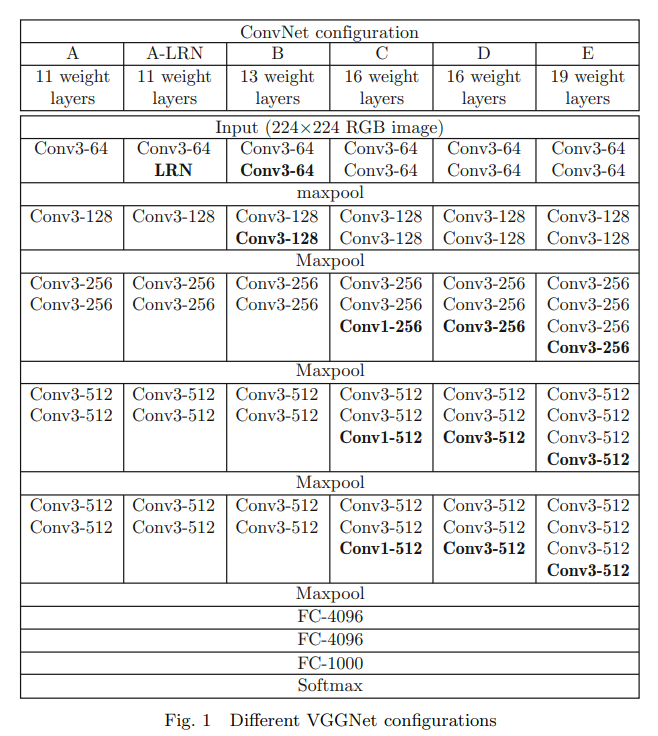
VGGNet의 구조
컨볼루션 신경망(Convolutional Neural Network, CNN) : 이미지 인식, 분류 등에서 효과적인 딥러닝 구조
컨볼루션 신경망(Convolutional Neural Network, CNN)의 여러 구조를 비교하여 나타낸 것으로, 각 열(A, A-LRN, B, C, D, E)은 다른 구조의 네트워크를 나타낸다.
각 행은 네트워크의 계층(layer)으로, 서로 다른 유형의 계층이 조합되어 전체 네트워크를 구성.
- Input (224x224 RGB image): 네트워크에 입력되는 이미지의 크기가 224x224 픽셀이며, RGB의 3channel 색상 채널을 가지고 있음.
- Conv3-64, Conv3-128, ...: 컨볼루션 계층 Conv3-64는 3x3 크기의 필터를 사용하는 컨볼루션 계층이며, 64개의 다른 필터(출력 채널)를 가지고 있음
- LRN: Local Response Normalization (지역 반응 정규화), 신경망의 일부에서 사용되는 정규화 기법.
- Maxpool: 최대 풀링(max pooling) 계층으로, 인접한 출력들 중 가장 큰 것을 선택함으로써 차원을 축소
- FC-4096, FC-1000: 완전 연결 계층(Fully Connected layer)을 나타내며, 각각은 4096개, 1000개의 뉴런
- Softmax: 클래스 확률을 출력하는데 사용되는 활성화 함수
모델 A에서 E까지 레이어의 수(weight layers)가 증가하며, 이는 네트워크가 더 깊어졌음을 의미하며, 더 깊은 네트워크는 복잡하거나 추상적인 특징을 학습할 수 있지만, 과적합(overfitting)의 위험도 증가하고 계산 비용도 증가함..
- VGGNet과 몇 가지 네트워크와 비교했을 때 정확도에서 특별한 장점을 갖지 않지만, 이러한 복잡한 네트워크의 결과는 대량이고 완전한 학습 데이터셋을 훈련한 후에 얻어진 것으로, 실제 응용에서는 가장 적합하고 편리한 네트워크를 구축하는 방법은 실험적인 검증을 거쳐야 함.
1.2 Data Augmentation
- 모델을 훈련시키기 위해서는 많은 수의 샘플이 필요
→ 샘플 수가 적은 경우에는 어떻게 AI 방법을 사용하여 이 문제를 해결할 수 있는지가 설계의 어려움 - (초기 연구) 신뢰할만한 추가 데이터가 없는 경우 :
가벼운 사전 훈련된 모델과 데이터 증강 방법을 사용하여 데이터셋을 확장. 데이터가 충분하지 않은 경우에도 훈련된 모델이 현실적이고 비상 상황에 더 적합 - 이미지를 뒤집거나 이동시키거나 다양한 각도로 회전시키거나 이미지의 밝기를 변경하는 것 → 다른 데이터 샘플을 얻은 것과 동일
- 합성곱 신경망이 데이터 증강 방법을 사용할 수 있는 이유는변환 불변성(translation invariance)을 가지기 때문
- 즉, 대상이 다른 조건에 놓였을 때 신경망을 훈련하기 위해 추가 데이터를 생성할 수 있음.
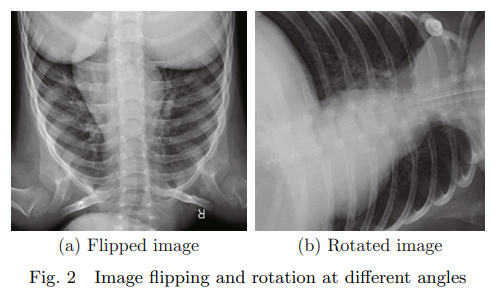
데이터 증강 방법에서 이미지 뒤집기와 다양한 각도로 회전하는 효과
2. Improved COVID-19 Network Based on VGG-16
2.1 pre-trained Model
- 신경망 :
데이터로부터 정보를 추출하고 해당 가중치로 변환하기 위해 많은 양의 데이터를 필요로 함.
- 얻은 가중치는 다른 신경망으로 전이(transfer)
- 전이 학습(transfer learning)은 AI 모델의 훈련 비용을 줄이고, 네트워크를 처음부터 훈련하는 번거로움을 피할 수 있게 해줌. 데이터가 부족한 경우, 전이 학습으로 학습된 사전 훈련 모델은 네트워크를 빠르게 훈련하는 데 도움이 됨. - 이후의 실험에서는 VGG-16 네트워크, VGG-19 네트워크, InceptionV3 네트워크, ResNet50 네트워크 및 Xception 네트워크가 디자인의 백본으로 각각 사용되었으며, 사전 훈련된 모델의 합성곱 층의 가중치는 고정되었고, 서로 다른 데이터셋에서 훈련된 완전 연결 층들을 테스트,,
2.2 Improved Version of the Full Connection Layer (완전 연결 층의 개선된 버전)
- 연구목적 : CXR 이미지에서 COVID-19 증상이 있는지 여부를 판단 → 이진 분류(binary classification)
- VGG-16 네트워크 : 1,000개의 클래스 분류 문제를 다루기 때문에, VGG-16 네트워크에서는 마지막 세 개의 완전 연결 층을 버리는 문제가 있어, 이 문제를 해결하기 위해 개선된 완전 연결 층이 설계되었다.
- "ImageNet" 사전 훈련 후의 합성곱 층의 가중치 파라미터가 먼저 로드되고 훈련 중에 업데이트되지 않도록 고정
- "평균 풀링(Average Pooling)" 사용
- 이 층에서 과적합(overfitting)을 피할 수 있으며, 공간 정보를 합산하고 평균을 내어 입력의 공간적 변동에 더 강건한 특성을 갖게 한다.
- "dense" 연결 준비를 위해 "flatten" 연산이 사용되었으며, 동시에 완전 연결 층 사이에 "dropout"이 추가되어 하이퍼파라미터를 조정하고 과적합을 피하기 위해 사용되었다.
- 배치 정규화 층을 추가하면 네트워크를 통해 경사(gradient)를 개선하고 더 큰 학습률을 허용하여 훈련 속도를 크게 향상시킬 수 있다.
- 마지막으로, 이진 분류 작업을 수행하기 위해 밀집(Dense) 층이 사용되었다.
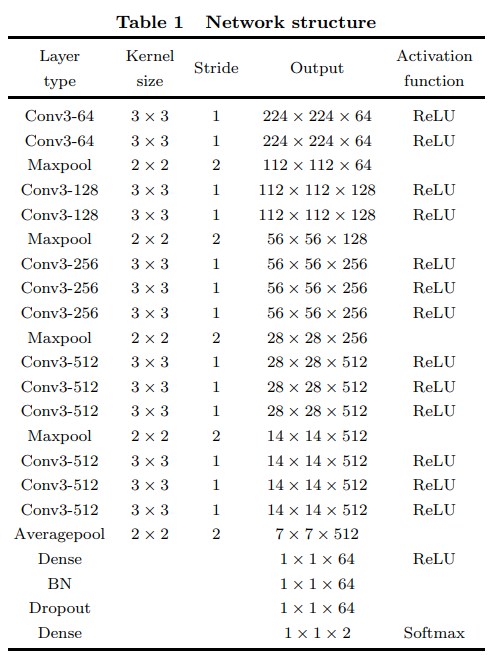
컨볼루션 신경망(Convolutional Neural Network, CNN)의 구조 / CXR 데이터의 80%를 훈련에 사용하고 20%를 테스트에 사용
다양한 계층의 종류(type), 해당 계층의 필터(filter) 또는 커널(kernel) 크기(size), 스트라이드(stride), 출력 크기(output dimensions), 사용된 활성화 함수(activation function)
-
Conv3-64: 컨볼루션 계층, 3x3 크기의 필터를 사용하며, 출력 채널은 64개. 스트라이드(필터가 한 스텝마다 한 픽셀씩 이동)가 1이며, 활성화 함수로 ReLU 사용. 출력 크기는 224x224x64로, 입력 이미지와 동일한 공간적 차원(224x224)을 유지하며, 64개의 필터가 적용되어 64개의 특성 지도(feature maps)를 만듦.
-
Maxpool: 최대 풀링 계층으로 2x2 크기의 필터를 사용하며, 스트라이드가 2. 각 풀링 연산에서 2픽셀씩 이동하므로, 출력 크기가 112x112x64로 줄어듦.
-
Conv3-128: 다시 컨볼루션 계층이며, 이번에는 128개의 필터를 사용합니다. 출력 크기는 112x112x128
-
Averagepool: 평균 풀링 계층은 2x2 필터를 사용하고 스트라이드가 2로, 픽셀 값을 평균내어 크기를 줄이며 이 경우 출력 크기는 7x7x512
-
Dense: 밀집 계층(완전 연결 계층)으로, 모든 입력이 연결된 뉴런 계층. 표의 마지막 행에 나타난 것처럼 일반적으로 하나의 벡터로 1x1xN 크기의 출력 생성. (N은 다음 계층의 뉴런 수)
-
깊이(채널 수)가 증가함에 따라 공간적 크기(가로 x 세로)가 감소하는 CNN 구조의 일반적인 패턴
2.3 Interpretability and Improvement Strategies
-
"Lime"은 대량의 데이터로 훈련된 신경망이 종종 사람들이 이해하기 어려운 특징을 기반으로 판단을 내리는 경우가 있기 때문에 사용되며, 이 도구는 사람들의 습관을 고려하며 해석을 제공하며, 설명이 너무 길지 않도록 한다.
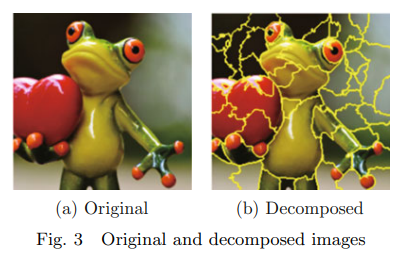
- 이미지 인식 : 이미지 입력을 기준으로 분류기의 분류 기준을 설명.
- 분류기는 이미지가 개구리를 포함하고 있는 가능성을 예측.
- 먼저, 왼쪽의 이미지를 연속적인 픽셀을 기반으로 해석 가능한 구성 요소로 분할.
- "마스킹"을 사용하여 이미지의 일부를 가려서 왜곡된 데이터셋을 생성(이 경우, 마스크된 영역은 회색으로 변함)
- 수정된 각 인스턴스를 다시 모델에 입력하고 왜곡된 이미지의 출력의 정확도를 얻음.
- 이 왜곡된 데이터셋에 포함된 모든 픽셀 블록의 기여 가중치를 가진 선형 모델 훈련.
- 모델 판단에 가장 큰 영향을 미치는 왜곡된 이미지의 영역에 더 관심을 가짐.
- 마지막으로, 가중치가 가장 높은 몇 개의 픽셀 블록을 예시로 선택하여 설명하고 나머지 영역은 회색으로 표시
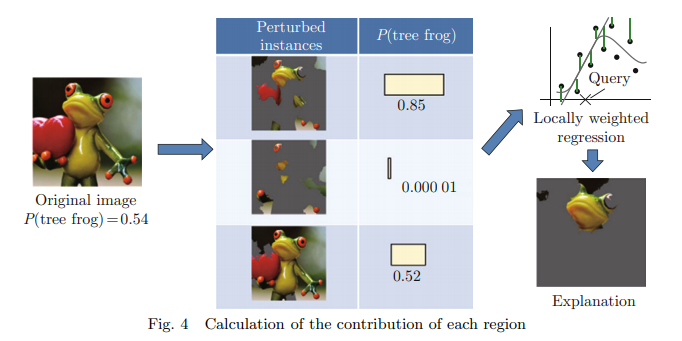
회색 영역을 제외한 픽셀 블록을 계산하여 모델 판단에 기여하는 정도 / 지역 가중 회귀를 수행한 후, 가장 큰 기여를 가진 영역은 이미지에 표시
- 인공지능 모델의 '나무 개구리'(tree frog)일 확률을 계산하는 과정
- "Original image” : 모델이 나무 개구리로 분류할 확률을 0.54로 예측
- 'Perturbed instances’ : 원본 이미지에 소량의 왜곡(perturbation)을 가하여 생성된 새로운 이미지들
→ 왜곡을 통해 모델이 이미지에서 특정 부분이나 패턴에 얼마나 의존하고 있는지 이해하는데 사용
→ 각 변형된 이미지는 나무 개구리로 분류될 확률을 다시 모델로부터 얻음
→ 일부 이미지에서는 확률이 0.85로 증가하는 반면 다른 이미지에서는 확률이 0.00001로 크게 감소 - 'Locally weighted regression' : 주어진 입력(변형된 이미지)에 대한 모델의 출력(나무 개구리일 확률)의 변화를 분석하는 통계적 방법
→ 이는 모델의 예측에 가장 영향을 많이 미치는 이미지의 부분을 식별하는 데 사용 - "Explanation" : 이미지는 이러한 분석을 통해 나무 개구리의 확률에 가장 큰 영향을 미치는 이미지의 부분을 강조함. 해당 논문에서는 개구리의 몸체와 눈이 강조되어 있어, 이 부분들이 모델이 개구리로 인식하는 데 중요한 역할을 한다는 것을 나타냄.
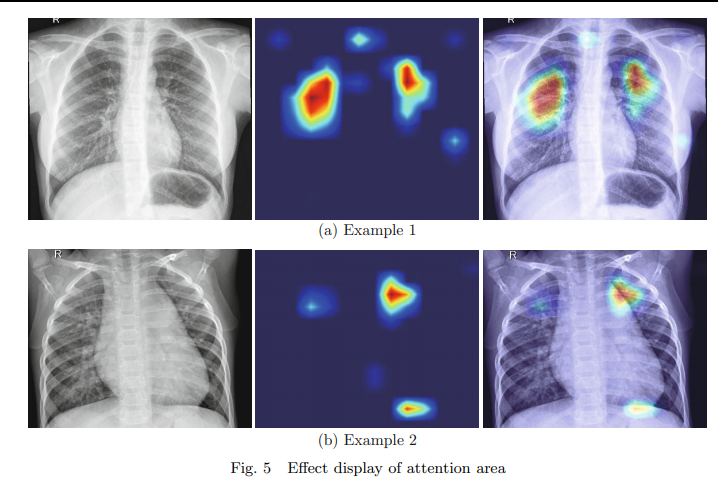
- 흉부 X-ray(CXR) 이미지의 "주의 영역(attention area)"에 대한 분석 결과
-
왼쪽 : 두 개의 원본 CXR 이미지
→ 정면 흉부 방사선 영상으로 의심되는 감염 부위를 식별하기 위해 사용 -
중간: 각 기존 CXR 이미지에 대한 "주의 영역(attention area)"을 나타내는 열 지도 형식
→모델이 COVID-19 감염을 탐지하는 데 있어서 중요하게 고려하는 영역을 나타냄
→가능성이 높은 영역은 빨간색, 낮은 영역은 차가운 파란색으로 나타냄 -
오른쪽 : 원본 이미지에 열 지도를 겹쳐서 출력
→모델이 특정한 영역을 기반으로 COVID-19 감염의 존재를 예측할 확률을 얼마나 높이고 있는지를 시각적으로 표현
이 이미지들은 "Lime" 분석 방법에 기반한 것으로 ,로컬 또는 주변 영역에서 모델의 예측에 가장 큰 영향을 끼치는 특징을 시각화하는 방법
- 모델의 진단 기준을 탐색 : 정확도+COVID-19 데이터셋을 테스트할 때 "Lime"이라는 해석 가능한 방법을 모델에 추가
- CXR 데이터를 분석하여 의심되는 감염 부위를 식별하고, 초록색은 판단에 기여하는 영역, 빨간색은 판단을 방해하는 영역으로 나타냄
- 왜곡된 데이터셋은 일부 블록을 무작위로 "닫음"으로써 생성.
- 왜곡된 CXR의 예측 점수가 원래 CXR의 예측 점수와 크게 다르다면, 왜곡된 블록이 모델 판단 과정에서 중요한 역할을 하는 것으로 판단.
- 각 왜곡된 샘플은 다시 모델에 입력되어 새로운 출력 진단 확률을 얻음.
- 왜곡된 데이터셋에 대해 선형 모델을 훈련하고, 결과에 더 큰 영향을 미치는 블록들을 찾음.
- 가중치가 가장 높은 픽셀 블록을 설명으로 선택하여 작은 변동을 주고 모델의 결과를 기록.
- "Lime"의 단점은 해석기의 분할 및 재그룹화 작업이 완전히 무작위이므로 의료 대상 검출에 약점이 있을 수 있음.
- COVID-19 감지 해석 연구에서는 해석 영역을 전체 흉부 공간이 아닌 폐에 집중해야 함.
- 해석 가능한 분석에서는 입력 CXR 이미지의 특징을 합성곱 층을 통해 추출하고, 성향 그래프를 생성.
- 관심 영역(ROI)은 원래 CXR 그래프에서 검색되고 성향 그래프에 매핑.
- ROI의 가중치를 높이면 설명 가능하고 분석 가능한 선형 모델이 ROI에 더 영향을 받게 됨.
3. Experimental Results and Analysis
3.1 Data Enhancement Operation (데이터 증강 작업)
** 합성곱 신경망은 이동 무변성을 가지고 있어 데이터 증강이 가능
- 데이터 증강은 제한된 데이터를 활용하여 더 많은 가치를 창출하는 것으로, 데이터의 차원을 변경하는 과정에서 데이터의 본질은 변하지 않지만, 데이터의 복잡성(관측 가능한 특징)은 향상되어 복잡한 환경에서의 매핑의 강건성이 향상된다.
- 데이터는 지정된 각도로 회전하거나 크기를 변경하는 등의 작업을 통해 증강될 수 있다.
밝기 증강 함수가 brightnessEnhancement(루트 경로, 이미지 이름)를 적용하고,
대비 증강 함수가 contrastEnhancement(루트 경로, 이미지 이름)를 적용하며,
이미지 회전 함수가 rotation(루트 경로, 이미지 이름)을 적용하고,
이미지 뒤집기 함수가 flip(루트 경로, 이미지 이름)를 적용.

- 데이터 증강 작업으로 데이터는 12배로 확장되어 25개의 COVID-19 CXR을 300개로 확장
3.2 Experimental Comparison (실험비교)
** 가벼움과 해석 가능성이 강조되는 실험 설계 아이디어를 사용(가장 높은 정확도, 재현율 및 기타 매개 변수를 추구)
- VGG-16, VGG-19, InceptionV3 및 Xception을 연속적으로 실험적 네트워크의 백본으로 사용
- 동시에 각 백본과 함께 다른 구조로 설계된 세 가지 종류의 완전 연결 계층을 시도
- 마지막으로, 각 네트워크는 원본 데이터셋(OD, 감염자 25개의 CXR과 정상인 25개의 CXR 포함)과 증강된 데이터셋(AD, 감염자 300개의 CXR과 정상인 300개의 CXR 포함)에서 테스트
** 여러 실험 그룹을 비교해야 하기 때문에 모든 네트워크는 1080ti에서 훈련
(그러나 각 네트워크 자체는 CPU만으로도 쉽게 훈련할 수 있는 충분히 가벼운 구조)
모든 네트워크는 25epochs 동안만 훈련되었으며, GPU 장비로 훈련된 것과 유사한 정확도를 가짐
여기서는 정밀도 및 재현율의 조화 평균인 F1-score가 고려됨.

실험 비교 결과 / 각 네트워크에 대해 완전 연결 구조의 최고 정확도와 최적의 전체 효과가 굵게 강조
- 흉부 X-ray 이미지를 분석하기 위해 다양한 심층 학습 아키텍처를 사용하여 수행된 실험의 결과 → 여러 네트워크에 따른 정확도, 정밀도(precision), 재현율(recall) 및 F1-score 지표
- 신경망 아키텍처 VGG-16, VGG-19, InceptionV3, Xception을 백본으로 사용
- 각 백본마다 다른 구조를 가진 세 종류의 완전 연결 계층을 테스트
- 각 네트워크는 두 개의 데이터셋에서 평가 : 원본 데이터셋(OD)과 증강된 데이터셋(AD).
OD에는 감염자와 정상인의 흉부 X-ray가 각각 25개씩 포함되어 있고, AD에는 300개씩 포함 - 모든 모델은 NVIDIA GeForce GTX 1080 Ti GPU를 사용하여 훈련되었지만, 각 모델은 가벼워서 CPU만을 사용하는 경우에도 쉽게 훈련될 수 있는 구조
- 모든 네트워크는 25 epoch 동안 훈련되었으며, 기대하는 수준의 정확도를 보여줌
- 첫 번째 열 : 데이터셋 종류("OD"는 원본 데이터셋, "AD"는 증강된 데이터셋)
- 두 번째 열 : 사용된 신경망 아키텍처
- 세 번째 열 : 합성곱 층 사이에 Dropout을 적용했는지 여부와 그 비율
- 네 번째 열 : 데이터 증강(Data Augmentation)을 사용했는지 여부
- 다섯 번째, 여섯 번째 열 : 각각 정밀도와 재현율
- 마지막 열 : F1-score (이는 정밀도와 재현율의 조화 평균이며, 두 지표 사이의 균형)
<결과>
- VGG-16, VGG-19, InceptionV3, Xception 아키텍처 모두 OD 대신 AD로 훈련했을 때 대체로 더 높은 F1-score
- 특히, VGG-16과 VGG-19 아키텍처는 0.9 이상의 F1-score
→ 증강된 데이터셋이 머신 러닝 모델의 성능을 향상시키는 데 도움이 되었다는 것을 시사 - F1-score가 중요한 지표로 강조된 이유는 이 데이터셋에서 COVID-19 감염의 정확한 탐지가 중요하기 때문.
→ 여기서 높은 F1-score는 모델이 감염을 정확하게 식별 - 즉, 높은 정확도와 더불어 정밀도와 재현율에서도 우수한 성능을 보임.

25 에포크의 훈련 후 손실 함수 곡선과 정확도 곡선
곡선의 경향을 통해 모델의 효과가 만족스러움
2.3 Interpretability Analysis
"Lime" 메소드를 사용할 때 지정해야 하는 매개변수
- "positive only" : 판별에 긍정적인 영향을 미치는 영역만 표시할지 여부. 이 값은 "False"로 선택되어, 정상 CXR의 대표적인 영역과 감염된 개인의 CXR의 대표적인 영역을 비교해 의료 종사자들에게 보다 포괄적인 보조 분석 제공
- "num features" : 가장 큰 기여도를 가진 영역의 수
- "hide rest = False" : 의심 영역이 표시된 후 나머지 CXR 픽셀 블록이 함께 표시되며, 값이 true인 경우, 나머지 CXR은 회색으로 표시.
- "for loop" : 데이터셋을 반복하고 각 이미지의 해석을 표시.
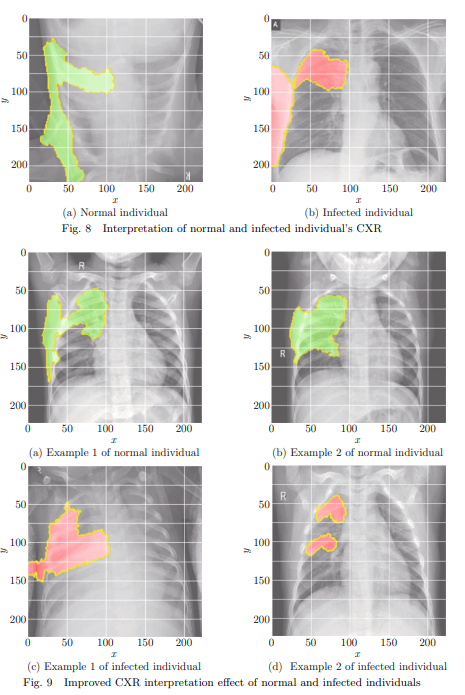
[Fig.8] CXR의 해석 가능성 분석 효과
왼쪽 이미지 : 정상 CXR
- CXR의 각도로부터 볼 때, 데이터 증강 기법을 사용하여 샘플 증강.
- 초록색 영역은 모델이 정상으로 판단하는 데 긍정적인 기여를 하는 영역.
오른쪽 이미지 : 감염 CXR
- 빨간색 영역은 모델이 감염 여부를 판단하는 데 긍정적인 기여
- [fig.8] 해석된 영역의 분포는 폐에만 국한되지 않고 흉부 전체에 분포. → 해석 가능성 분석에 주의 가중치를 추가함으로써 모델은 CXR의 중심에 위치한 폐 영역에 더 집중.
- [fig.9] 개선된 “Lime” 가중치로 생성된 해석 가능성 분석 결과
4. Conclusion
가벼운 VGG-16 네트워크와 사전 훈련된 모델을 사용해 COVID-19 샘플을 통해 개선된 완전 연결 계층만을 훈련. & 데이터 증강을 통해 데이터 셋 확장
과학 연구의 목적은 항상 더 많은 개인에게 이익을 주는 것으로 CT데이터 대신 CXR을 사용해 연구를 하게 된 이유..
- CXR의 침투율이 높고 비용이 낮기 때문에 CXR을 기반으로 한 COVID-19 감지 시스템은 더 큰 가치를 가짐 + 더 많은 개인에게 도움을 줌
- CXR 진단은 건강 및 전염병 예방 업무에 기여할뿐만 아니라 더 많은 잠재적 데이터를 발견해 진단을 빨리 해결하기 위한 긍정적 사이클 형성 + 판단에 기여
