1. 개요
개인적으로 Database에 대한 기술 스택은 개발자 사이에서 프로그래밍 언어에 대한 코딩 실력보다도 편차가 많이 있는 분야라고 생각한다.
하지만 진입 장벽이 높지는 않고 개발자라면 기본적으로 DB를 어느정도는 다루기 때문에 자칫 코딩보다 덜 중요한? 분야 또는 코딩 기술 스택을 쌓는 것에 비해 투자하는 시간을 현저히 줄이는 경향을 심심찮게 볼 수 있다.
물론 DB팀이 따로 존재하는 회사가 많기에 DB 설계, 튜닝 등의 DB 작업은 DB팀에 전담하고 개발자는 코딩에만 집중할 수 있을 것이다.
그럼에도 불구하고 DBA가 아니더라도 DB를 알고 공부해야 하는 이유는 간단하다.
이것은 필자의 지론인데, 어떤 분야에 대해 내가 알고서 관여하지 않는 것과 모르기 때문에 관여하지 않는 것은 천지차이라고 생각한다.
빅데이터 시대가 도래하면서 데이터의 양이 기하급수적으로 늘어나는 경우가 비일비재한 만큼 개발자라면 자신이 처리해야하는 데이터의 유형, 규모, 서비스 성향 등에 따라 적절한 Database를 선정하고 서비스 중에 데이터를 저장하고 조회하는데 있어서 발생할 수 있는 여러 사이드 이펙트를 고려하지 않을 수 없다.
또한 DB 전담팀이 따로 존재하더라도 개발을 하다보면 DB팀과 업무적으로 소통할 일도 많이 생기는데, 이 때 DB에 대한 보다 전문적인 지식을 제대로 알고 있다면 상대방의 얘기를 이해하기도 또 내 얘기를 전달하기도 한결 수월해질 것이다.
이러한 이유들로 개발자가 알아야하는 데이터베이스 관련 기술 스택은 어떤 것들이 있을 수 있을까? 필자는 아래와 같은 것들이라고 생각한다.
2. RDBMS와 NoSQL DB, DB 선정 능력
이 글에서 말하는 DB 선정 능력(필자의 주관)이란, 적재되는 데이터의 성향, 서비스의 특성 등 데이터와 관련된 여러 조건들을 분석하고 그 결과에 따라 보다 적절한 DB를 선정하는 능력을 말한다.
2-1. 데이터 및 서비스의 특성 파악
아래 서술된 것 외에도 DB를 선정하는 기준은 너무나 다양할 것이다. 아래와 같이 자신이 서비스하려는 데이터의 특성을 파악하는 작업은 DB 뿐만 아니라 개발에도 영향을 미치는 중요한 키포인트가 될 수 있을 것이다.
- 데이터 성향
- 데이터 처리양보다 무결성이 중요할 때
- 속도가 최우선 일 때
- 복잡한 Join 쿼리나 트랜잭션이 보장되어야 할 때
- 데이터의 원장성이 보장되어야 할 때
- DB의 확장 가능성을 염두해야할 때
- 서비스 성향
- 검색 조건의 다양화가 필요할 때
- 압도적인 성능(조회)이 중요할 때
- 적재보다 조회가 빈번할 때
2-2. 위 조건에 부합하는 DB 선정
간략하게 RDBMS(PostgreSQL) 과 NoSQL(MongoDB) 의 특성을 비교한 자료를 작성해보았다.
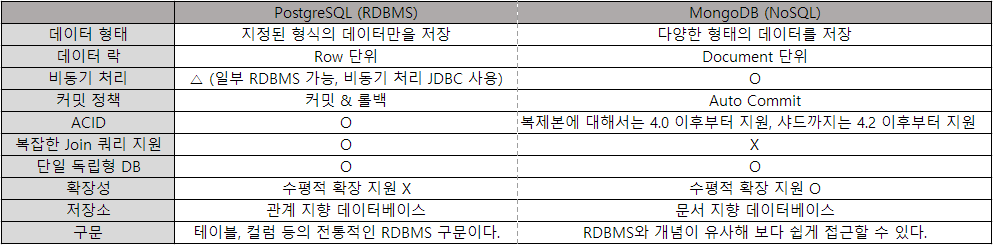
이외에도 고려할 수 있는 다양한 DB와 다양한 조건들이 있을 것이다. 또한 데이터의 형태, 조건이 다양한만큼 실제로 읽기, 쓰기 속도에 대한 부분은 절대적인 우위를 지닌 DB를 정의하기는 힘들다.
절대적인 성능 우위를 지닌 DB를 정할순 없으나 현재 내가 처리해야 하는 조건에 부합하여 최적화된 성능을 낼 수 있는 DB는 다양한 테스트를 통해서 정할 수 있다.
일반적인 벤치마크 지표를 참고해보면 트랜잭션 성능 테스트는 RDBMS(PostgreSQL)가 더 뛰어나고 단일 데이터의 CRUD는 NoSQL(MongoDB)가 더 뛰어난 성능을 보인다고 한다.
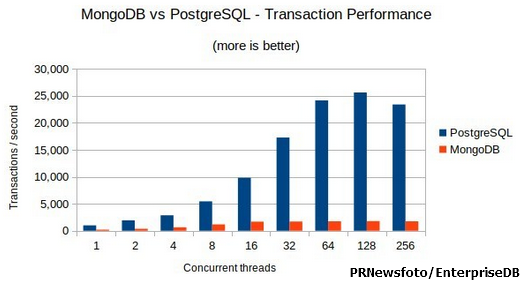
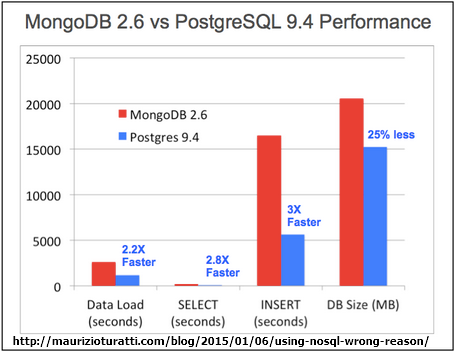
하지만 MongoDB에서도 인덱스의 데이터가 커질수록 Insert 성능이 저하되기 때문에 적정 기준을 정해야 할 것이다.
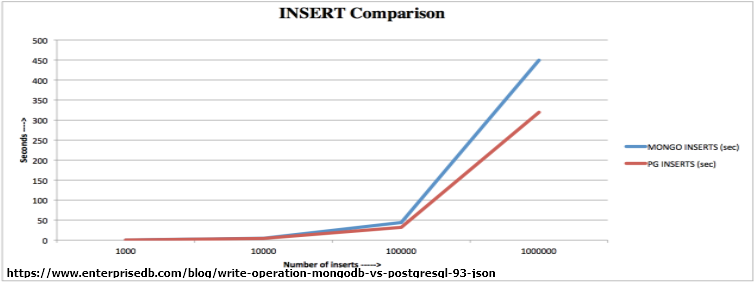
2-3. 혼합 DB의 사용
꼭 RDBMS, NoSQL DB를 하나만 선택하여 사용할 필요는 없다. 상황에 맞게 RDBMS와 NoSQL DB를 혼합하여 사용함으로써 서로가 가지는 단점들을 극복하기도 한다.
실제로 결제와 같은 데이터 정합성이 중요한 부분에는 RDBMS를 사용하고 그 외에는 MongoDB를 사용하여 성능과 안정성을 모두 개선하는 경우도 있다.
2-4. 결론
- 다루는 데이터가 1억건 이상 되지 않는다면 RDBMS의 성능으로도 충분히 서비스가 될 것이다.
- 또한 RDBMS의 파티셔닝과 인덱싱으로도 웬만한 성능 개선이 가능하다.
- 유입되는 데이터의 형태가 다양하고 데이터의 정합성보다 초당 수만건의 데이터를 처리하는 것이 우선이 되는 시스템이라면 NoSQL DB는 좋은 대안이 될 것이다.
- 또한 NoSQL DB는 데이터에 대한 Insert&Update 보다 Read가 빈번한 시스템에서 더욱 효과적이다.
3. DB 튜닝 능력
DB 튜닝이란, DB의 성능 향상을 목적으로 수행하는 모든 작업을 일컫는다.
또한 DB 튜닝은 시스템 운영 전반에 걸쳐서 다양한 분야에서 수행할 수 있다.
3-1. DB 튜닝 방안
3-1-1. 디스크 I/O를 줄인다.
디스크로의 접근 횟수를 줄이는 것이 효과적인데, I/O를 줄이는 방법은 크게 캐시를 사용하는 방법과 DB를 분산하여 데이터 저장시 각 DB가 받는 I/O를 줄이는 것이 효과적이다.
3-1-2. 적절한 캐시를 사용한다.
버퍼 캐시 사용, 공유 메모리 설정, 가상 메모리 사용 지양 등의 RDBMS에서 제공하는 다양한 캐시 기능을 사용하여 직접적인 디스크 접근을 줄이는 것이 효과적이다.
3-1-3. 최적화 작업을 수행한다.
아래와 같은 데이터를 확보하고 분석하여 최적화 작업을 수행한다.
- SQL문 정보 (어떤 테이블이지 조건(WHERE)인지, 관계(JOIN)인지 여부) 파악
- 데이터 양, 분포 등의 작업량을 예측하기 위한 통계 정보
- 풀 스캔시 한번의 I/O 로 처리하는 블록의 갯수
- 데이터 처리 속도를 기반으로 현재 CPU 클럭, I/O 성능 등을 파악
3-1-4. SQL문 수정 및 인덱싱 처리를 해준다.
잘못된 Join 등의 비효율적인 SQL문을 수정하고 FullText(전문) 검색을 지양하고 적절한 인덱싱 처리를 한다.
위 튜닝 방안 중 개발자 수준에서의 튜닝은 3-1-4. 정도가 될 것이고 나머지는 DBA 와 같은 전문 DB팀에서 고려해야 할 것이다.
3-2. 효율적인 인덱싱 기준
- 하나의 값에 인덱싱을 구성 한다면 고유한 값을 가지는 컬럼(카디널리티가 높은)을 지정한다.
- 복합 컬럼에 인덱싱을 구성 한다면 카디널리티가 높은 -> 낮은 순으로 지정한다.
- 인덱스로 지정된 컬럼은 컬럼명 그대로 사용해야 한다.
- 범위 조건(between, like 등)이 아닌 곳에 인덱스를 사용하는 것이 좋다.
- 조회하려는 데이터가 전체 데이터의 약 15% 이하일 때 효과적이다.
