문제
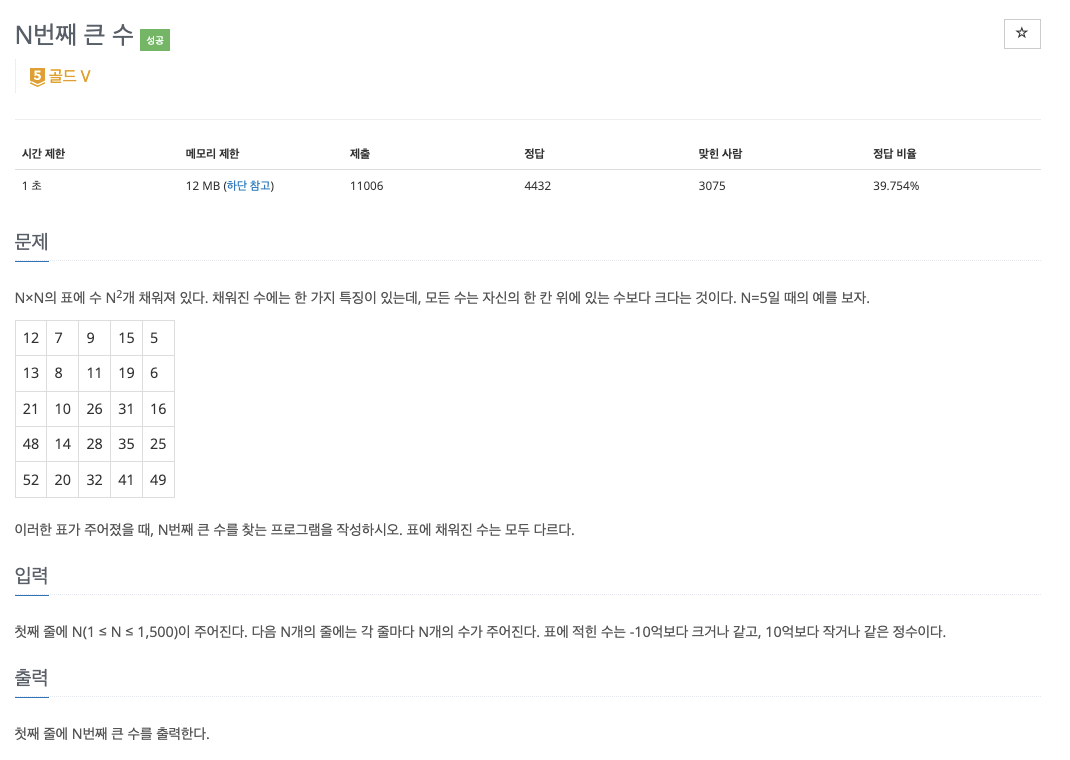
입력 , 출력
solution
import heapq
import sys
input = sys.stdin.readline
n = int(input())
heap = []
for i in range(n):
arr = list(map(int, input().split()))
for j in range(n):
if len(heap) == n:
a = heapq.heappop(heap)
if a < arr[j]:
heapq.heappush(heap, arr[j])
else:
heapq.heappush(heap, a)
else:
heapq.heappush(heap, arr[j])
print(heapq.heappop(heap))설명
시행착오
1번 메모리 초과
import heapq
import sys
input = sys.stdin.readline
n = int(input())
heap = []
for i in range(n):
arr = list(map(int, input().split()))
for j in range(n):
heapq.heappush(heap, (-arr[j], arr[j]))
for i in range(n):
a = heapq.heappop(heap)[1]
print(a)틀린이유
최대힙으로 만들어서
n번째를 출력하는 방식으로 구현을 함
하지만 메모리초과..
why??
n은 최대 1500
처음 반복문 에서 nlogn(n = 1500* 1500 =2250000)
4500000log(1500)≈14292410.665750567
두번째 nlogn (n = 1500)
1500log(1500)≈4764.136888584
으로 반복횟수로만은 충분한 시간이라고 생각했다.
그래서 굳이 두번째 반복문을 사용할 필요가 없어서
2번 메모리 초과
import heapq
import sys
input = sys.stdin.readline
n = int(input())
heap = []
for i in range(n):
arr = list(map(int, input().split()))
for j in range(n):
heap.append(arr[j])
heap.sort()
print(heap[n * n - n])이렇게 풀리면 골드 문제가 아니였겠지..
또 메모리 초과..
시간의 문제가 아니라
배열이 너무 커서 메모리초과가 난듯 했다.
배열의 최대 크기가 2250000 이라서
그래서 배열의 크기를 줄일 수 있는 방법은
n번째 큰 수를 찾기 위해서는 우선순위큐 , 최소힙으로 크기를 n으로 고정 해서
첫번째 인덱스를 출력하면 n 번째 큰 수 이기 때문에
heap의 크기가 n일 경우에는 pop을 하여서 비교 한 뒤 입력받은 크기가 pop한 수보다 클 경우에는
입력받은 숫자를 heap에 넣고 아닐경우에는 다시 pop한 숫자를 넣는 방식으로
heap의 크기를 n으로 고정하는 풀이를 선택했다.
후기
틀린 이유를 시간복잡도만 생각해서 틀렸었다.
맨날 시간복잡도만 생각했는데 공간복잡도도 생각해봐야 하는 계기가 되었다.

이것저것합니다