
KOCW에 공개된 고려대 영남대 최규상 교수님 컴퓨터 구조 강의를 수강 후 정리한 내용입니다!
1.6 Performance
1. CPU Time

- 성능을 향상시키기 위해서는
- clock cycles 수 감소
- clock rate 증가
- cycle 수와 clock rate는 트레이드 오프 관계
2. Instruction Count and CPI

- Instruction Count: 프로그램, ISA, 컴파일러에 의해 결정
- CPI: CPU 하드웨어가 어떻게 구성되어 있는지에 따라 결정
- 각각의 다른 instructions는 서로 다른 CPI를 요구
- 서로 다른 instructions이 섞여있을 경우 평균 CPI를 사용해야 함

- Computer A의 Clock rate: 4GHz, Computer B의 Clock rate: 2GHz
- Same ISA: Instruction Count의 값이 A, B가 서로 같음을 의미
- 성능은 Excution Time에 반비례. 컴퓨터 A가 컴퓨터 B보다 1.2배 빠름을 의미
3. CPI in More Detail
- 다른 instruction classes는 다른 cycles 수를 요구

- 평균 가중치 CPI: 여러 개의 instruction classes을 사용할 때 사용
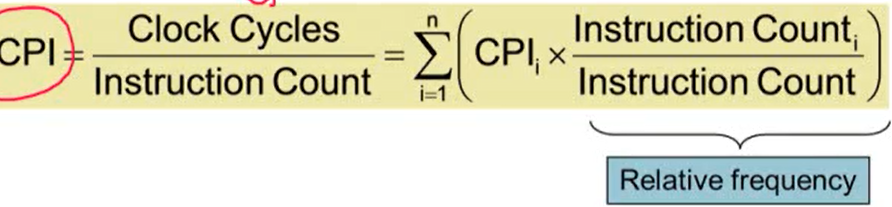
- 예시
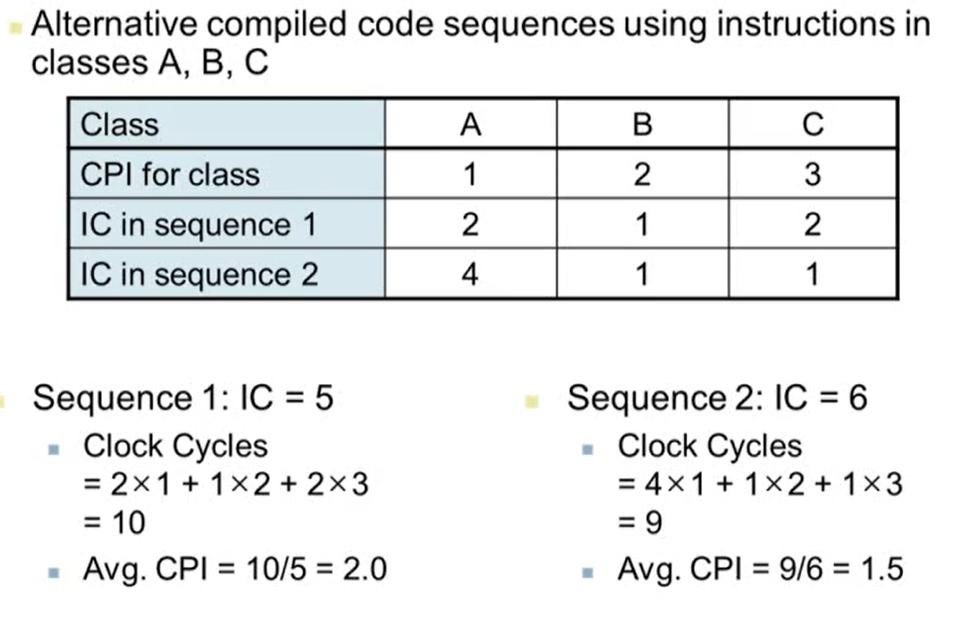
- IC: Instrcution Count
- Sequence 2가 Sequence 1보다 IC가 하나 더 많지만 Clock Cycles는 하나 작음. 즉, Sequence 2가 Sequence 1보다 실행 시간이 빠를 수 있음
- 하나의 instruction을 수행하는데 걸리는 CPI가 Sequence 1의 CPI보다 짧기 때문에 Sequence 2가 Sequence 1보다 삐르게 수행 가능
- 예시
4. Performance Summary

- 알고리즘: Instruction Count, CPI에 영향을 줄 수 있음
- 프로그램 언어: IC와 CPI에 영향을 줄 수 있음
- 컴파일러: IC와 CPI에 영향을 줄 수 있음
- ISA(Instructon Set Architecture): IC, CPI, Clock Cycle time에 영향을 줄 수 있음
1.7 The Power Wall
Power Wall
- voltage(전력)을 더 이상 낮추지 못하므로 이로 인해 발생하는 열을 없앨 수 없음
- 따라서 기존에 사용했던 성능 향상 방법을 더 이상 사용할 수 없게 됨
- 새로운 방법인 multi-core를 사용해 성능을 향상시키고자 함
1.8 The Sea Change: The Switch to Multiprocessors
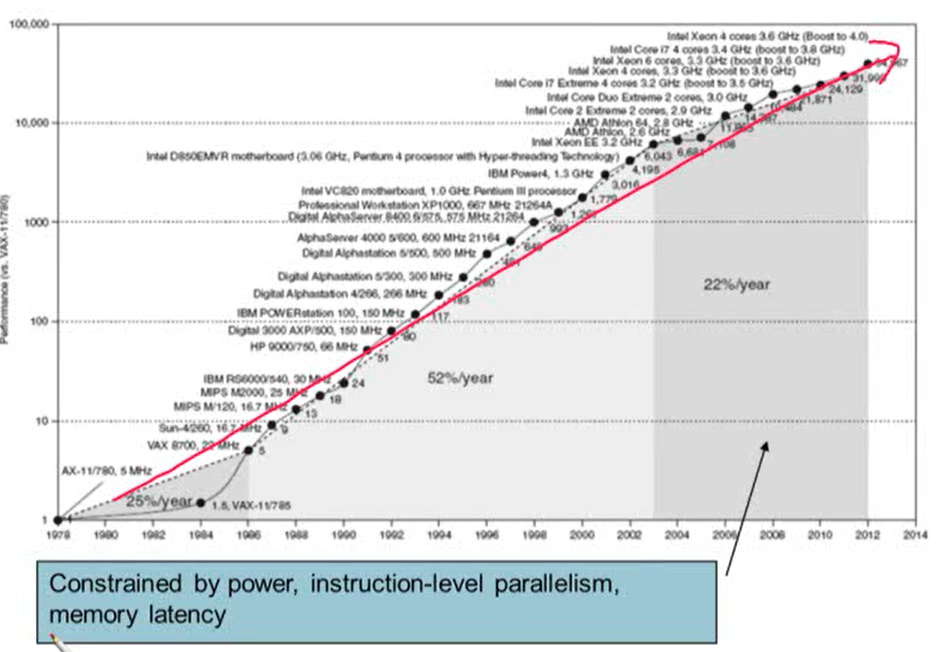
- power(전력), instruction-level parallelism, memory latency로 인해 싱글 코어일 때보다 성능 향상 퍼센트가 낮아짐
1. Multiprocessors
- Multicore microprocessors: 하나의 칩 안에 여러 프로세서를 넣음
- 멀티코어의 성능 향상을 위해서는 parallel programming을 사용해야 함
- 기존의 sequencial programming을 사용할 경우 멀티 코어에서의 성능 향상은 없음. 기존 프로그램을 parallel programming으로 바꿔야만 성능이 향상됨
- instruction level parallelism: 하드웨어가 알아서 동시에 명령어를 수행해주는 것
- parallel programming: 프로그래머가 하나하나 프로그램을 짜야 함
- 하나의 일을 여러 개로 나눴을 경우 나눠진 일들이 비슷한 load를 가져야 함
- parallel programming에서 발생하는 communication과 synchronization 문제를 줄여주어야 함
- 멀티코어에서의 성능 향상을 위해서는 parallel programming을 사용해야하는데 parallel programming을 사용하는 것 자체가 어렵기 때문에 유니 코어(싱글 코어)에 비해 성능 향상 속도가 낮을 수 밖에 없음
2. SPEC CPU Benchmark
- SPEC: Standard Performance Evaluation Corp
- CPU, I/O, Web 등의 성능을 측정해주는 benchmarks를 만드는 회사
- SPEC CPU Benchmark
- CPU의 성능을 측정하는 benchmark
- SPEC CPU 2006
- 여러 개의 프로그램을 실행해 실행한 프로그램의 총 실행 시간을 더함
- 아주 작은 I/O를 사용하므로 I/O 시간을 무시할 수 있고 CPU 성능을 측정하는데 집중
- 기존의 표준 성능으로 잡은 reference machine과 비교해 얼마나 성능이 향상되었는지 비교 가능
- integer 프로그램용인 CINT2006과 floating-point 프로그램용인 CFP2006으로 나눠짐
- 여러 개의 프로그램을 실행해 실행한 프로그램의 총 실행 시간을 더함
1.9 Concluding Remarks
1. Cost/performance is improving
- 무어의 법칙에 의해 가격 대비 성능이 계속 향상되고 있음
2. Hierarchical layers of abstraction
3. Instuction set architecture
- 컴퓨터 구조에서의 abstraction은 ISA라고 할 수 있음
- ISA는 하드웨어와 소프트웨어의 인터페이스
- 하드웨어와 소프트웨어가 통신하는 방식이 instruction임
4. Excution Time
- 가장 좋은 성능 측정 방법
5. Power is a limiting factor
- power 문제는 성능을 향상시키는데 제약이 됨
- 이 문제는 멀티코어 방식을 사용해 해결하려고 하고 멀티 코어에서는 parallelism을 사용해야만 성능 향상이 가능
1.10 Fallacies and Pitfalls
1. Pitfall: Amdahl's Law
- 컴퓨터의 한 부분의 성능을 향상 시키면 전체 performance의 성능 향상은 비례한다

- T_affected: 한 부분의 향상시킨 후의 성능
- T_unaffected: 성능을 향상시키지 않았을 때의 성능
- improvement factor: 성능을 향상시킨 한 부분
- 시스템의 한 컴포넌트 성능을 향상시키면 전체 시스템의 성능 향상은 그 컴포넌트가 시스템의 얼마만큼을 차지하는지의 비율에 비례한만큼만 향상됨

- 곱하기 연산은 전체 100초 연산 중 80초를 차지. 이럴 경우 multiply performance를 향상시켜 전체 성능을 5배 향상시키고자 함. 이럴 경우 곱하기 연산의 성능은 얼만큼 향상되어야 하는가?
- n이 무한대로 갈 경우에만 식이 성립하므로 불가능하다는 의미. 곱하기 성능 향상만으로는 전체 성능을 5배로 향상시킬 수 없다
- 결론: 어떤 시스템의 성능을 향상시키기 위해서는 그 시스템에서 가장 많은 portion을 차지하는 컴포넌트를 가장 빠르게 만드는 것이 전체 시스템 성능을 향상시킬 수 있는 방법
2. Fallacy: Low Power at Idle
- processor를 만들 때 load에 비례해서 전력 소모를 할 수 있도록 만들어야 함
3. Pitfall: MIPS as a Performace Metric
- MIPS: Millions of Instructions Per Second (시간당 몇 백만개의 instructions을 실행하는가)
- MIPS를 Performance Metric으로 사용했지만 MIPS를 Performance Metric으로 사용할 경우 오해를 불러올 수 있음
- 컴퓨터마다 ISA가 다르기 때문
- 명령어마다 복잡성이 다르기 때문

- MIPS는 CPI에 의해 좌우됨. 하지만 CPI는 프로그램과 CPU에 의해 달라질 수 있음. 따라서 성능 측정 단위로 사용하기 어려움
- 정확한 성능 측정을 위해서는 앞에 나온 SPEC CPU Benchmark를 사용하는 것이 좋음
공식 암기
- performance = 1/Execution Time
- CPU Time = Instruction Count X CPI X Clock Cycle Time
2주차 끝!!!
게시물에 사용된 사진의 출처는 강의 동영상에 나온 사진을 캡쳐한 것입니다.

예비 백엔드 개발자