
KOCW에 공개된 영남대 최규상 교수님 컴퓨터구조 강의를 수강 후 정리한 내용입니다.
2.14 Arrays versus Pointers
1. Arrays vs Pointers
- array를 사용할 경우 항상 array의 인덱스를 계산하기 위해 인텍스에 element size를 곱해주는 연산 + 곱한 값에 array base address를 더해주는 연산이 필요
- pointer를 사용할 경우 바로 memory adress로 접근 가능. index를 계산하는 과정이 필요없게 됨
- pointer를 사용하는 것이 성능이 더 향상될 수 있음
Example: Clearing and Array

- 두 함수는 같은 일을 수행. array의 모든 값을 0으로 초기화해줌
- 왼쪽 코드는 array, 오른쪽 코드는 pointer를 사용
- $a0: array의 시작 주소, $a1: size
- 오른쪽 코드에서
- addi $t0, $t0, 4: $t0에 4를 더해줌. 다음 element 시작 주소 값으로 변경해주는 과정
- $t2: array[size]의 시작 주소
- array를 사용할 경우 loop 안의 명령어 개수는 6개, pointer를 사용할 경우 loop 안의 명령어 개수는 4개로 구성
- loop의 반복이 많은 경우 pointer로 구현하는 것이 더 높은 성능을 보임
2. Comparison of Array vs Pointer
- 컴파일러는 포인터를 사용하는 것과 같은 비슷한 효과를 줄 수 있음
- Induction variable elimination: 인덱스 사용하는 것을 없애줌
- 컴파일러를 사용해 array 방식으로 프로그램을 구성하면 훨씬 이해하기 쉽고 버그가 생길 확률이 줄어듦
- pointer을 사용할 경우 버그가 생길 확률이 높기 때문에 일반적으로 프로그램을 구성할 때는 array를 사용하는 것을 권장
2.16 Real Stuff: ARM Instructions
Compare and Branch in ARM
- arithmetic/logical instruction의 결과에 따라 조건문을 만들 수 있음
- 각각의 명령어가 조건이 될 수 있음
- instruction word의 top 4 bits를 condition value로 채움
- 하나의 명령어로 구성된 branch를 회피할 수 있음
2.17 Real Stuff: x86 Instructions
- Intel CPU와 MIPS의 차이
- x86은 레지스터마다 길이가 다름
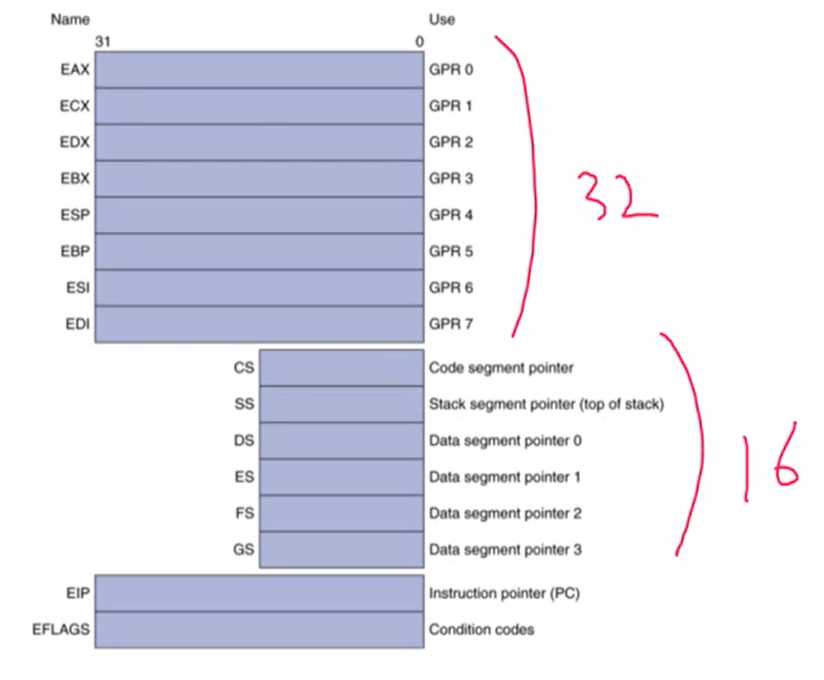
- operand에 메모리 주소를 바로 쓸 수 있음. MIPS는 load/store을 제외하고 명령어들이 메모리를 직접적으로 access하지 않음(레지스터 사이에서 연산 수행)
- MIPS는 명령어의 길이가 32bit로 고정. x86은 명령어의 길이가 다양함
- x86은 레지스터마다 길이가 다름
Implementing IA-32
- MIPS: Reduced Instruction set(RISC)
- Intel의 아키텍쳐: Complex instruction set(CISC)
- implementation이 까다롭고 높은 성능을 보이기 어려움
- 해결 방법
- 하드웨어가 하나의 명령어를 간단한 suboperaions(microoperations)으로 나눔. 하나의 명령어가 여러 개의 명령어로 나눠지게 됨
- Microengine은 microoperation을 실행하는데 이 때 Microengine이 RISC와 유사해 성능을 낼 수 있었음
- 겉으로는 CISC이지만 내부적으로는 RISC
- Intel은 구조적으로는 MIPS에 비해 안 좋은 구조를 가지지만, 내부적으로는 MIPS와 같은 RISC 아키텍쳐를 따르기 때문에 CISC 명령어를 microoperations으로 나눠주는 오버헤드를 제외하면 내부적인 성능은 비슷
2.19 Fallacies and Pitfalls
1. Fallacies
-
Powerful instruction(하나의 명령어가 여러 개의 일을 한 번에 처리하는 것)을 사용하면 높은 성능을 보여줄 것
- 이유: 명령어의 수가 줄기 때문
- 실제로는 복잡한 명령어는 구현하기 어렵기 때문에 컴파일러는 powerful instruction보다 간단한 명령어 여러 개를 사용해서 만든 코드가 더 높은 성능을 보임
-
어셈블리 코드를 사용하면 높은 성능을 보여줌
- 실제로 높은 성능을 보일 순 있지만 최근의 컴파일러는 C언어로 작성한 코드도 어셈블리어로 작성한 코드와 유사한 성능을 보여줌
- 어셈블리 코드를 사용할 경우 line 수가 증가하기 때문에 더 많은 에러가 발생할 수 있고 생산성이 떨어짐. 따라서 특수한 경우(ex. 임베디드)를 제외하고는 high-level language를 사용하는 것이 좋음
-
Backward compatibility(예전 것이 새로운 환경에서도 지원이 되는 것)을 지원한다는 것이 instruction set이 바뀌지 않는다는 것을 의미
- instruction set이 바뀌지 않는다는 것을 의미하는 것은 아님
- instruction set는 계속 변경되지만 예전에 지원한 instruction이 현재에도 지원되기 때문에 backward compatibility를 보장
2. Pitfalls
-
Sequential words는 sequential addresses가 아님
- word의 크기는 4byte이므로 주소가 1이 아닌 4씩 증가
-
procedure 내에서 전역 변수를 가리키는 포인터를 사용했을 때 포인터가 함수가 끝난 후면 포인터가 가리키는 메모리 주소는 유효한 메모리 주소가 아니게 됨
- stack에서 pop될 때 포인터는 유효한 메모리 주소를 가리키지 않음
- 함수 내에서 정의한 포인터는 함수 내부에서만 사용해야 함
2.20 Concluding Remarks
1. Design principles
- Simplicity favors regularity
- Smaller is faster
- Make the common case fasst
- Good design demands good compromises
2. Layers of software/hardware
- Compiler, assembler, hardware
- 프로그램이 어떻게 실행 파일이 되고 실행 파일이 어떻게 실행되는지
3. MIPS: typical of RISC ISAs
- cf) x86: typical of CISC
- MIPS는 benchmark 프로그램
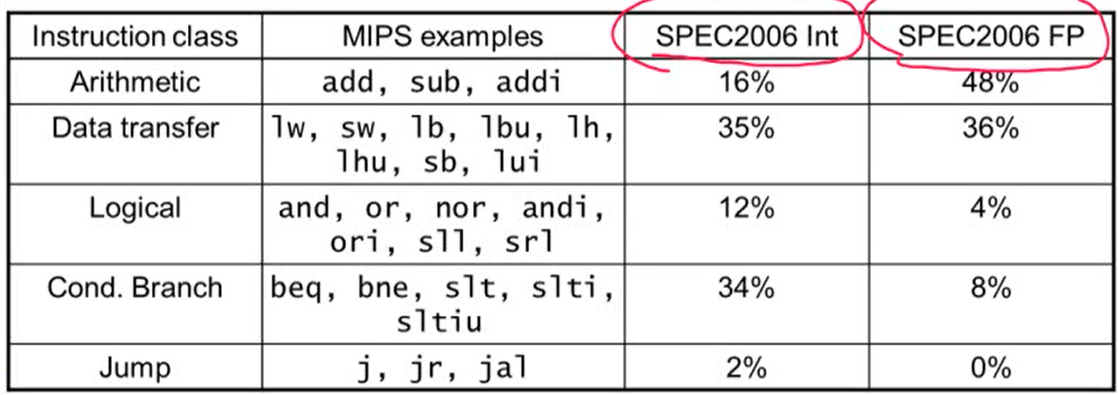
- Consider making the common case fast
- Integer의 경우 Data transfer과 Condition Branch를 빠르게 하는 것이 중요
- Floating point의 경우 Arithmetic과 Data transfer를 빠르게 하는 것이 중요
- Consider making the common case fast
5주차 끝!!!
게시물에 사용된 사진은 강의 내용을 캡쳐한 것입니다.

예비 백엔드 개발자