
'자바의 정석 3rd Edition'을 공부하며 정리한 내용입니다.
4. 기본형 (primitive type)
4.1 논리형 - boolean
- 논리형에는 boolean 한 가지만 존재
- boolean형 변수에는 true와 false 중 하나를 저장. 기본값은 false
- 논리구현에 주로 사용 (ex. 대답(yes/no), 스위치)
- 크기: 1byte
boolean power = true;
boolean checked = False; // 에러. 대소문자 구분해야 함- 자바에서는 대소문자가 구별되기 때문에 TRUE와 true는 다른 것으로 간주됨
4.2 문자형 - char
- 문자형에는 char 한 가지만 존재
- 문자를 저장하기 위한 변수를 선언할 때 사용
- char 타입의 변수는 단 하나의 문자만 저장 가능
char ch = 'A' // 문자 'A'를 char 타입의 변수 ch에 저장
char ch = 65; // 문자의 코드를 직접 변수 ch에 저장- 실제론 문자가 아닌 '문자의 유니코드(정수)'가 저장됨. 컴퓨터는 숫자밖에 모르기 때문에 모든 데이터를 숫자로 변환하여 저장
- 문자 리터럴 대신 문자의 유니코드를 직접 저장할 수 있음
- 어떤 문자의 유니코드를 알고 싶으면 char형 변수에 저장된 값을 정수형으로 변환하면 됨
int code = (int)ch;1. 특수 문자 다루기
- 영문자 이외에 특수 문자 저장도 가능
| 특수 문자 | 문자 리터럴 |
|---|---|
| tab | \t |
| backspace | \b |
| corm feed | \f |
| new line | \n |
| carriage return | \r |
| 역슬래쉬() | \ |
| 작은 따옴표 | \' |
| 큰 따옴표 | \" |
| 유니코드(16진수) 문자 | \u유니코드 (ex. char a = '\u0041') |
2. char 타입의 표현형식
- 크기: 2byte (=16bit)
- 16자리의 2진수로 표현할 수 있는 정수의 개수인 65536개의 코드를 사용할 수 있으며 범위 내의 코드 중 하나를 저장할 수 있음
- char 타입은 문자를 저장할 변수를 선언하기 위한 것이지만, 실제론 문자가 아닌 '문자의 유니코드(정수)'가 저장되고 표현형식 역시 정수형과 동일
- 정수형과 달리 음수를 나타낼 필요가 없으므로 표현할 수 있는 값의 범위는 다름
char ch = 'A'
short s = 65;- 위의 두 변수에는 똑같은 2진수가 저장됨. 하지만 출력해보면 결과가 다름
- 이유: println()은 변수의 타입이 정수형이면 변수에 저장된 값을 10진수로 해석하여 출력하고, 문자형이면 저장된 숫자에 해당하는 유니코드 문자를 출력하기 때문
인코딩과 디코딩(encoding & decoding)
- 문자 인코딩: 문자를 코드(숫자)로 변환하는 것. 문자를 저장할 때 수행
- 문자 디코딩: 코드(숫자)를 문자로 변환하는 것. 저장된 문자를 읽어올 때 수행
4.3 정수형 - byte, short, int, long
- 크기 순 정렬: byte(1byte) < short(2byte) < int(4byte) < long(8byte)
1. 정수형 저장 형식과 범위
- 모든 정수형은 부호가 있으므로 왼쪽의 첫 번째 비트를 부호 비트(sign bit)로 사용하고 나머지는 값을 표현하는데 사용
- n비트로 표현할 수 있는 정소의 개수: 개(= 2^(n-1)개 + 2^(n-1)개)
- n비트로 표현할 수 있는 부호있는 정수의 범위: (-2)^(n-1) ~ 2^(n-1) - 1
- 최댓값에서 1을 빼는 이유는 범위에 0이 포함되기 때문
2. 정수형의 선택기준
- byte, short 보다는 int를 사용. byte와 short는 int보다 크기가 작아 메모리를 조금 더 절약할 수 있지만, 저장할 수 있는 값의 범위가 작은 편이라 연산 시에 범위를 넘어 잘못된 결과를 얻기 쉬움
- JVM의 피연산자 스택이 피연산자를 4byte 단위로 저장하기 때문에 4byte보다 작은 자료형의 값을 계산할 대는 4byte로 변환하여 연산을 수행. 따라서 int를 사용하는 것이 더 효율적
- 정수형 변수를 선언할 때는 int 타입으로 하고, int의 범위(약 -20억 ~ +20억)를 넘어서는 수를 다뤄야할 때는 long을 사용
- byte나 short는 성능보다 저장공간을 절약하는 것이 더 중요할 때 사용
3. 정수형의 오버플로우
- 오버플로우: 타입이 표현할 수 있는 값의 범위를 넘어서는 것
- Example) 1111 + 0001 = 0000
- 1111에 0001를 더할 경우 10000이지만, 4bit로는 4자리의 2진수만 저장할 수 있기 때문에 0000이 됨
- Example) 1111 + 0001 = 0000
- 오버플로우가 발생해도 에러가 발생하지는 않지만 예상했던 결과를 얻지 못함. 오버플로우가 발생하지 않게 충분한 크기의 타입을 선택해서 사용해야 함
- 오버플로우가 사용되는 예시: 자동차 주행표시기, 계수기
- 네 자리 계수기라면 0000 ~ 9999까지 표현 가능. 9999 다음의 숫자는 0000이 됨
- 0000에서 1을 감소시키면 어떻게 될까?
- 0에서 1을 뺄 수 없으므로 저장되지 않은 1이 있다고 가정하고 뺄셈을 진행. 결과는 네 자리로 표현할 수 있는 최댓값이 됨
- 정리
- 최댓값 + 1 => 최솟값
- 최솟값 - 1 => 최댓값
- 이 특징 때문에 2진수의 경우 값을 무한히 1씩 증가시켜도 0000과 1111의 범위를 계속 반복하게 됨
4. 부호있는 정수의 오버플로우
- 부호없는 정수와 부호있는 정소는 최댓값 최솟값이 다르기 때문에 오버플로우가 발생하는 시점이 다름
- 부호없는 정수는 2진수로 0000이 될 때 오버플로우가 발생하고, 부호있는 정수는 부호비트가 0에서 1이 될 때 오버플로우가 발생
- 최댓값에서 최솟값이 되는 경우 오버 플로우 발생
- 부호없는 정수의 경우 표현범위가 0~15이므로 이 값이 계속 반복. 부호있는 정수의 경우 표현범위가 -8~7이므로 이 값이 무한히 반복 됨
- short와 char의 크기는 모두 16bit이므로 표현할 수 있는 값의 개수가 같음. 하지만 short는 이 중 절반을 음수를 표현하는데 사용하고 char는 전체를 양수와 0을 표현하는데 사용
4.4 실수형 - float, double
1. 실수형의 범위와 정밀도

사진 출처: 자바의 정석 3rd Edition p. 68
- 표의 범위는 양의 범위만 적은 것. - 부호를 붙이면 음의 부호가 됨
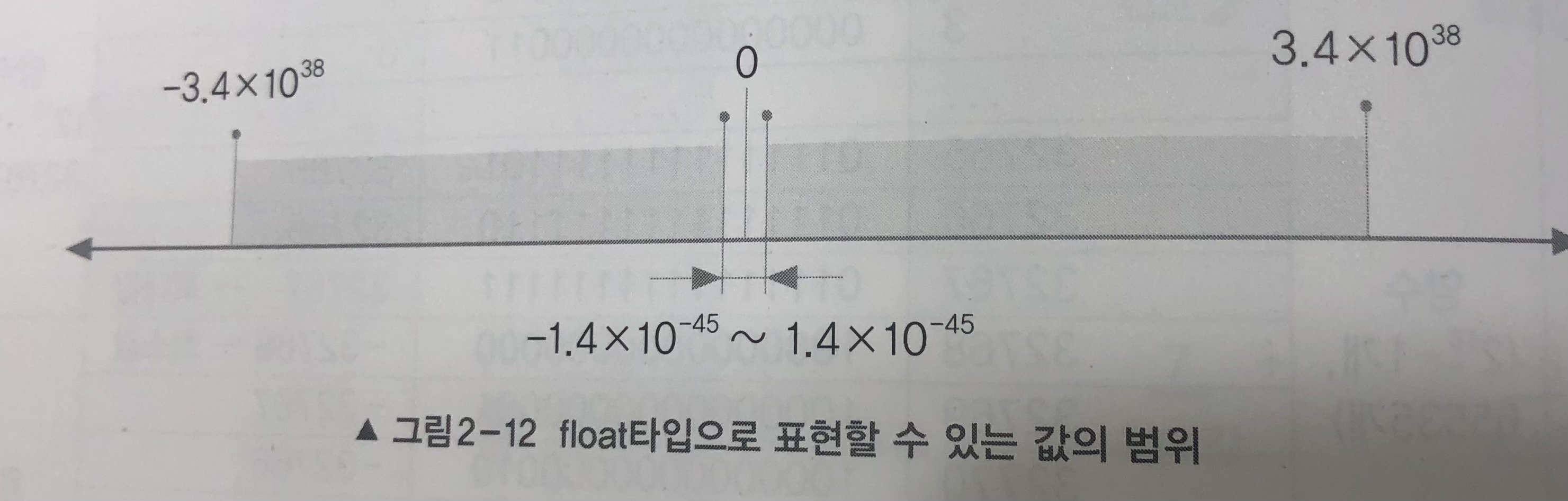
사진 출처: 자바의 정석 3rd Edition p. 68
- 중간 부분(0 제외)은 표현할 수 없음
- 실수형은 소수점수도 표현해야 하므로 얼마나 큰 값을 표현할 수 있는가뿐만 아니라 얼마나 0에 가깝게 표현할 수 있는가도 중요
Q) 실수형도 정수형처럼 저장할 수 있는 범위를 넘게 되면 오버플로어가 발생하나요?
실수형에서도 변수의 값이 표현범위의 최댓값을 벗어나면 오버플로우가 발생. 실수형에서 오버플로우가 발생하면 변수의 값은 무한대가 됨.
언더플로우도 존재. 언더플로우는 실수형으로 표현할 수 없는 아주 작은 값, 즉 양의 최소값보다 작은 값이 되는 경우를 의미. 이 때 변수의 값은 0이 됨
- 같은 4byte이지만 float형이 정수형보다 큰 값을 표현할 수 있는 이유
- 값을 저장하는 형식이 다르기 때문
- int 타입: 부호(S, 1bit)와 값(31bit)로 구성
- float 타입: 부호(S, 1bit), 지수(E, 8bit), 가수(M, 23bit)로 구성
- 2의 제곱을 곱한 형태(+- X )로 저장하기 때문에 큰 범위의 값을 저장하는 것이 가능
- 실수형은 오차가 발생할 수 있다는 단점이 있어 정밀도(precision)가 중요
- float 타입의 정밀도는 7자리. 7자리의 10진수를 오차없이 저장할 수 있다는 의미
- 7자리 이상의 정밀도가 필요하다면, 변수의 타입을 double로 해야함
- 연산속도의 향상이나 메모리를 절약하려면 float를 선택하고, 더 큰 값의 범위 혹은 더 높은 정밀도를 필요호 한다면 double을 선택
2. 실수형의 저장 형식
- 값을 부동소수점수(floating-point)의 형태로 저장. 부동소수점수는 부호(Sign), 지수(Exponent), 가수(Mantissa) 부분으로 이루어짐
- float: 1(S) + 8(E) + 23(M) = 32(4byte)
- double: 1(S) + 11(E) + 52(M) = 64(8byte)
- 부호(Sign bit)
- 0이면 양수, 1이면 음수를 의미
- 2의 보수법을 사용하지 않기 때문에 양의 실수를 음의 실수로 바꾸려면 부호비트만 0에서 1로 변경
- 지수(Exponent)
- 지수는 부호있는 정수이고 8bit이므로 -127~128의 값이 저장됨
- -127과 128은 'NaN(숫자 아님)' 이나 '양의 무한대(POSITIVE_INFINITY)', '음의 무한대(NEGATIVE_INFINITY)'와 같이 특별한 값의 표현을 위해 예약되어 있어 실제 사용 가능한 범위는 -126~127
- 가수(Mantissa)
- 실제 값인 가수를 저장하는 부분
- 2진수 23자리 저장 가능. 2진수 23자리로는 약 7자리의 10진수를 저장할 수 있는데 이것이 float의 정밀도가 됨
- double의 경우 기수를 저장할 수 있는 공간이 52자리로 float의 약 2배. double이 float보다 약 2배의 더 좋은 정밀도를 가짐
3. 부동소수점의 오차
- 실수 중에는 무한소수가 존재하므로 저장할 때 오차가 발생할 수 있음. 2진수로 저장하기 때문에 10진수로는 유한소수이더라도 2진수로 변환하면 무한소수가 되는 경우도 있음
- 2진수로는 10진 소수를 정확히 표현하기 어렵고 2진수로 유한소수이더라도 가수를 저장할 수 있는 자리수가 한정되어 있으므로 저장되지 못하고 버려지는 값들이 있으면 오차가 발생
- 정규화: 2진수로 변환된 실수를 저장할 때 '1.xxx X '의 형태로 변환하는 과정
- 정규화된 2진 실수는 항상 '1.'으로 시작하기 때문에 이를 제외한 23자리의 2진수가 가수로 저장되고 이후는 잘림
- 지수는 기저법(부호있는 정수를 저장하는 방법, 저장할 때 특정값을 더했다가 읽어올 때 다시 뺌)으로 저장
- Float 클래스의
floatToIntBits()는 float 타입의 값을 int 타입의 값으로 해석해서 반환

예비 백엔드 개발자