<목차>
01. 빅데이터의 이해
빅데이터의 정의와 출현 배경, 기능을 학습하고 빅데이터가 가져오는 변화 이해하기
1) 빅데이터의 이해
2) 빅데이터 출현 배경
3) 빅데이터 기능과 변화
-
데이터의 가치와 미래
빅데이터의 가치와 정부, 개인 등에 미치는 영향을 살펴보고 위기 요인과 통제 방안
1) 빅데이터의 가치와 영향
2) 비즈니스 모델
3) 빅데이터의 위기 요인과 통제 방안
4) 미래의 빅데이터 -
가치 창조를 위한 데이터 사이언스와 전략 인사이트
빅데이터 열풍 속에서 가치 기반 분석이 가지는 의미, 중요성
1) 빅데이터 분석과 전략 인사이트
2) 전략 인사이트 도출을 위한 필요 역량
3) 빅데이터 그리고 데이터 사이언스의 미래
데이터의 가치와 미래
☑️ 빅데이터 정의
- 가트너그룹(Gartner Group)의 더그 래니(Doug Laney)의 정의 (3V)
- 빅데이터는 데이터의 양(Volume), 데이터 유형과 소스 측면의 다양성(Variety), 데이터 수집과 처리 측면에서 속도(Velocity)가 급격히 증가하면서 나타난 현상이다.
-빅데이터의 새로운 특징 4V: 더그 래니의 3V에 하나의 V를 더한 것. Value(가치) 또는 Veracity(정확성) / 여기에 Visualization(시각화), Variability(가변성)등을 추가하는 견해도 있음.
빅데이터 출현 배경 3가지
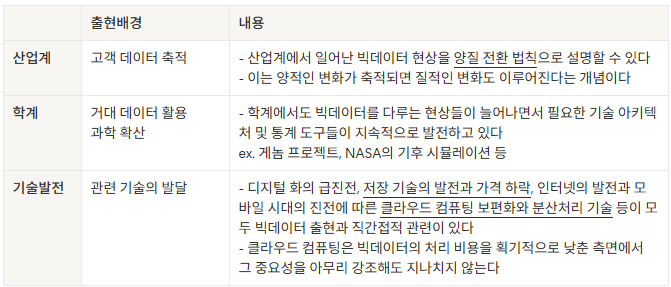
빅데이터의 기능
빅데이터는 '산업혁명의 석탄'이자 '21세기의 원유', '현미경의 렌즈', '플랫폼'
빅데이터가 만들어내는 변화
과거에서 현재로의 변화가 중요. 현재는 사후처리(데이터를 일단 모음), 전수조사, 질보다 양, 상관관계 위주로 따짐(for 신속한 의사결정)
빅데이터의 가치
빅데이터 가치 산정이 어려운 이유 3가지: 데이터 활용 방식(데이터 재사용, 재조합), 새로운 가치 창출(기존에 없던 가치를 창출함에 따라 산정이 어려움), 분석 기술의 발전(지금은 가치가 없더라도 나중에는 재료가 될 수 있음)
☑️빅데이터 활용 기본 테크닉 7가지
- 연관규칙 학습: 상관관계 분석
- 유형분석: 새로운 사건이 속할 범주/분류를 찾아내는 방법
- 유전 알고리즘: 최적화가 필요한 문제 해결책을 자연선택, 돌연변이 등과 같은 매커니즘을 통해 점진적으로 진화시켜나가는 방법(유전학의 개념 모방)
- 기계학습: 알고리즘을 활용하여 예측하는 분석 모델
- 회귀분석: 독립변수 조작->종속변수가 어떤 영향을 받는지 그 원인과 결과를 분석
- 감정분석: 비정형 데이터 마이닝의 대표적 기법. 특정 주제에 대한 의견을 낸 사람의 감정을 분석
- 소셜 네트워크 분석: 유저 사이의 관계를 분석하여 영향력 있는 사람을 찾아냄
빅데이터의 위기요인
- 사생활 침해: 우리는 매일 많은 데이터를 만들어내고, 그 데이터는 수집당하고 있다.
- 책임 원칙 훼손(마이너리티 리포트?): 데이터 기반 예측 기술이 발전하고, 정확도가 증가하였다. 그러나 그 기술로 사람들을 판단한다면 희생양을 만들 수 있다.
- 데이터 오용: 결국 빅데이터는 과거의 데이터이므로, 이를 바탕으로 미래를 예측할 때는 경계심을 가져야 한다.
통제 방안?
- 사생활 침해의 통제 방안->'동의에서 책임으로' 데이터 사용자가 책임져야 한다.
- 책임 원칙 훼손의 통제 방안->'결과 기반 책임 원칙 고수' 성향이 아닌 행동 결과를 보고 판단한다.
- 데이터 오용의 위기요소에 대한 대응책->'알고리즘 접근권 허용/인증' 예측 알고리즘의 부당함을 반증할 수 있는 방법을 명시
(참고) 개인정보 비식별 기술의 예시
데이터 마스킹, 가명처리, 총계처리, 데이터값 삭제, 데이터 범주화
=>데이터 속에서 특정 개인을 식별할 수 있는 요인을 숨김으로써 개인을 알아볼 수 없도록 하는 기술
가치 창조를 위한 데이터 사이언스와 전략 인사이트
☑️ 빅데이터 열풍과 회의론: 과거 CRM의 부정적 학습효과, 과대 포장 (꼭 필요한가?)
Q: 어떻게 접근하는 것이 좋을까?
☑️ 빅데이터 분석, ‘Big’이 아닌 ‘인사이트’
-빅데이터는 크기가 중요한 게 아니라 분석이 중요. 의미있는 정보를 얻을 수 있는가?
-단순한 분석에서 끝나서는 안된다. 전략적 통찰력을 가지고 핵심적 비즈니스에 집중해야 한다.
Q: 일차원적인 분석은 어떤 면에서 한계가 있는가? 업계 내부의 문제에만 포커스를 두기 때문에, 비즈니스 성공에서 핵심적인 역할을 기대하기 어렵다.
데이터 사이언스의 의미와 역할
-통계학이 정형화된 실험 데이터를 분석 대상으로 하는 것에 비해, 데이터 사이언스는 정형 또는 비정형을 막론함.
-데이터 사이언티스트는 비즈니스에서 핵심요소를 짚어낼 수 있어야 함. 소통 역량 중요.
데이터 사이언스와 데이터 사이언티스트
데이터 사이언스의 핵심 구성요소: Analatics(분석적 영역), IT(Data Management), 비즈니스 분석(커뮤니케이션, 스토리텔링, 시각화)
데이터 사이언티스트의 요구 역량
하드 스킬과 소프트 스킬
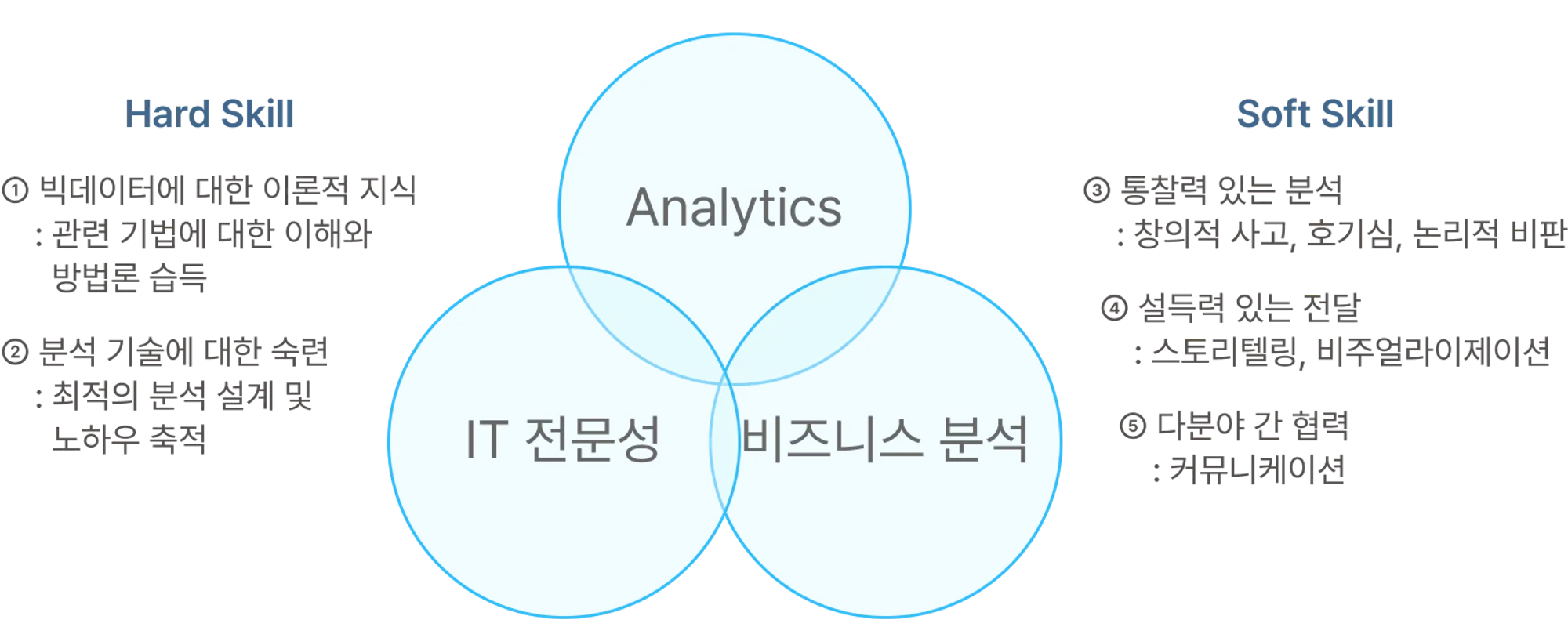
*데이터 사이언스에서는 인문학적 사고 역시 중요하다.
가치 패러다임의 변화
가치 패러다임=>경제와 산업의 원천에 있는 가치에 대한 패러다임.
3단계 변화: 디지털화->연결->에이전시
코딩 스터디
이젠 테이블이 2개입니다
오늘은 어제 아티클 스터디에서 읽은 '가독성 좋은 코드를 작성하는 습관'을 최대한 상기하면서 답안을 작성하려 노력하였다.
<오늘 가장 고민했던 부분>
- 부서별로 직원 수를 계산하는 쿼리를 작성해주세요!
SELECT d.name,
COUNT(e.id) AS employee_count
FROM departments d
LEFT JOIN employees e ON d.id = e.department_id
GROUP BY d.id;전에 SELECT 절에 언급되지 않으면 GROUP BY를 쓸 수 없다고 한 것 같은데, 왜 SELECT d.name (중략) GROUP BY d.id인가가 너무 궁금했다. d.name으로 통일하거나, d.id로 통일하면 안 되는 걸까?
우선 d.id와 d.name은 1:1 관계로, d.name은 d.id에 종속된다.
그렇다면 왜 GROUP BY d.id인가?
id는 기본키(PK) 이므로 유일하고, 그룹의 기준으로 안정적이다.
기본키(PK)가 있는 테이블에서는 GROUP BY에 PK만 써도 대개 충분하다고 한다.
Q: SELECT d.id는 안 되나?
A: 되지만, 가독성 떨어짐. 아래는 SELECT d.id를 했을 때의 결과다.
id만 보고는 부서명을 알 수 없으니, 칼럼은 d.name을 선택하는 것이 합리적이다.
| d.id | employee_count |
|---|---|
| 101 | 2 |
| 102 | 1 |
| 103 | 1 |
Q: 그럼 고민할 것 없이 둘 다 불러오는 건 어떨까?
SELECT d.id, d.name, COUNT(e.id) AS employee_count
FROM departments d
LEFT JOIN employees e ON d.id = e.department_id
GROUP BY d.id;d.id, d.name 둘 다 불러오면 다음과 같은 결과가 나온다. 연산 시간이 오래걸리려나 하는 생각도 들었지만, 보기 좋다는 느낌이 들었다.
| d.id | d.name | employee_count |
|---|---|---|
| 101 | 인사팀 | 2 |
| 102 | 마케팅팀 | 1 |
| 103 | 기술팀 | 1 |
키(key)란?
오늘 처음 들었는데 매우 중요한 개념이라 생각해서 추가 학습을 진행했다.
테이블 내에서 각 행(row)을 식별하거나, 테이블 간 관계를 만드는 기준이 되는 컬럼(또는 컬럼 집합)
즉, 키는 누가 누구인지 정확히 구별하기 위한 식별자 & 두 테이블을 연결하는 고리
🔑 데이터베이스의 주요 키 종류
| 키 종류 | 설명 | 예시 |
|---|---|---|
| Primary Key (기본 키) | 테이블 내에서 각 행을 유일하게 식별하는 컬럼 | 주민등록번호, 사번, 학번 등 |
| Foreign Key (외래 키) | 다른 테이블의 기본키를 참조하는 컬럼 | 직원 테이블의 department_id → 부서 테이블의 id |
| Candidate Key (후보 키) | 기본키로 쓸 수 있는 후보군. 유일성과 최소성을 만족 | 주민번호, 이메일, 휴대폰 번호 |
| Composite Key (복합 키) | 여러 컬럼을 묶어서 하나의 기본 키로 사용 | (학번, 과목코드) 같이 2개 조합 |
| Unique Key (유니크 키) | 중복을 허용하지 않는 키 (기본키와 비슷하지만 NULL 허용 가능) | 이메일 주소, 아이디 등 |
🧠 키의 역할을 쉽게 정리하면
| 역할 | 설명 |
|---|---|
| 기본키(PK) | "이 행은 누구인가?" 식별 기준 |
| 외래키(FK) | "이 행은 다른 테이블의 어떤 행과 연결되는가?" |
| 유니크키 | "이 값은 중복되면 안 돼!" → 로그인용 아이디 등 |
| 후보키 | "기본키로 써도 될 만한 것들" |
키는 중복 데이터를 방지 하고, 빠르고 정확한 검색을 가능하게 한다.
또 JOIN 문법을 사용하는 데에도 중요하다고 한다.
MySQL에서 지원하는 JOIN 문법
강의에서 배운 JOIN은 INNER JOIN, LEFT JOIN뿐이었는데 그 밖에도 다양한 JOIN의 종류가 있는 걸 알았다. 다만 MySQL에서 지원하지 않는 JOIN 문법(FULL OUTER JOIN)도 있으니 사용에 유의해야 한다.
| JOIN 종류 | 설명 | 공통 문법 |
|---|---|---|
| INNER JOIN | 두 테이블 모두에서 일치하는 데이터만 조회 | ... FROM A INNER JOIN B ON A.id = B.a_id |
| LEFT JOIN (또는 LEFT OUTER JOIN) | 왼쪽 테이블 A의 모든 행 + 일치하는 B | ... FROM A LEFT JOIN B ON A.id = B.a_id |
| RIGHT JOIN (또는 RIGHT OUTER JOIN) | 오른쪽 테이블 B의 모든 행 + 일치하는 A | ... FROM A RIGHT JOIN B ON A.id = B.a_id |
| CROSS JOIN | 모든 행의 카테시안 곱 (A×B 전부 조합) | ... FROM A CROSS JOIN B |
| SELF JOIN | 같은 테이블을 자기 자신과 조인 | ... FROM A a1 JOIN A a2 ON a1.id = a2.manager_id |
Q: 나머지는 이해가 가는데, SELF JOIN은 대체 무엇이며 왜 필요한 걸까?
예시
SELECT e.name AS 직원, m.name AS 관리자
FROM employees e
JOIN employees m ON e.manager_id = m.id;• 하나의 테이블을 두 개로 나눠 별명(Alias)를 붙이고 JOIN할 수 있다.
• 조직도, 계층 구현에 필요하다.
