
1. 각 복구 전략의 선택 기준과 적용하기
1. 선택 기준
1. RPO와 RTO의 차이와 복구 전략 매핑
- RPO가 긴 경우 → 백업/복구 전략이 적합 (예: 장기 보관 데이터, 저빈도 트래픽 서비스)
- RTO와 RPO 모두 짧아야 하는 경우 → Multi-Site Approach 선택 (예: 금융, 의료 분야)
2. 비용 대 복구 시간 분석
- 각 전략의 비용 분석 및 비용 효율성 비교
- AWS 서비스 사용 예산 계산 (예: EC2, RDS, Route53, S3)
3. 트래픽 패턴과 서비스 중요도에 따른 선택
- 계절성 트래픽 (온디맨드 확장 가능한 Warm Standby 추천)
- 24/7 서비스 (Multi-Site Approach 필수)
4. 업종 및 산업군에 따른 적용 사례
- 금융권: Multi-Site Approach → 데이터 손실 시 법적 문제 방지
- 스타트업: Pilot Light → 비용 효율성과 확장 가능성
2. 프로젝트 적용 후
1. Pilot Light
- 상황: 식품 전자상거래 사이트(예: 운영중 쇼핑몰)에서 상품 주문 내역이 중요하지만, 이미지나 리뷰 데이터는 덜 중요.
- 적용
- RDS를 이용해 주문 데이터를 실시간 복제.
- EC2는 꺼둔 상태에서 Route53 페일오버 트리거 사용.
- 재해 시 EC2를 스케일 업하여 복구.
- 결과: 데이터 손실 0%, 복구 시간 15분, 비용 절감 50%.
2. Warm Standby
- 상황: SaaS 기반 프로젝트 관리 도구에서 중단 시 고객 불만 발생 가능성.
- 적용
- EC2 Auto Scaling Group 최소 인스턴스 유지.
- 트래픽 급증 시 Lambda 함수로 ASG 스케일 업.
- RDS는 Multi-AZ 구성으로 데이터 손실 방지.
- 결과: 평균 복구 시간 5분, 중단 없는 서비스 제공.
3. Multi-Site Approach
- 상황: 대규모 온라인 게임 서비스(예: MMORPG).
- 적용
- AWS Global Accelerator를 통해 클라이언트 요청 분산.
- S3 크로스 리전 복제 및 DynamoDB 글로벌 테이블 구성.
- 여러 리전의 EC2와 ALB를 항상 운영.
- 결과: 복구 시간 0, 데이터 손실 없음, 글로벌 트래픽 처리 가능.
2. 재해복구 자동화 및 혼란 테스트의 구체적 구현 하기
1. 재해복구 자동화
1. CloudFormation을 활용한 인프라 자동화
- 주요 스택 구성
- EC2, RDS, S3, Route53, ELB 등 포함.
- 재해 발생 시, Change Set으로 빠르게 복구 환경 배포.
- YAML 기반 스택 템플릿.
Resources:
MyEC2Instance:
Type: AWS::EC2::Instance
Properties:
InstanceType: t3.medium
ImageId: ami-0abcd1234efgh5678
KeyName: MyKeyPair
2. AWS Lambda 기반 복구 트리거
- CloudWatch 알람 이벤트 발생 → Lambda가 Route53 Failover 호출.
- 주요 구현 코드 예시 (Python).
import boto3
def lambda_handler(event, context):
client = boto3.client('route53')
response = client.change_resource_record_sets(
HostedZoneId='Z1234EXAMPLE',
ChangeBatch={
'Changes': [
{
'Action': 'UPSERT',
'ResourceRecordSet': {
'Name': 'example.com',
'Type': 'A',
'TTL': 60,
'ResourceRecords': [{'Value': '192.0.2.44'}]
}
}
]
}
)
return response
2. 혼란 테스트
1. Chaos Engineering 원칙
- 장애를 일부러 만들어 인프라의 복원 능력을 테스트.
- Netflix의 Simian Army에서 배운 교훈
- Chaos Monkey: 무작위로 EC2 종료.
- Chaos Gorilla: 특정 AZ를 종료.
- Chaos Kong: 리전 전체를 종료.
2. AWS Fault Injection Simulator (FIS) 활용
-
EC2, RDS, EKS 등에서 장애를 시뮬레이션.
-
실습 시나리오.
- EC2 인스턴스 종료 시 복구 시간 측정.
- DynamoDB 쓰기 제한 초과 시 대체 프로세스 작동 확인.
3. 혼란 테스트 자동화 스크립트 예시
-
CloudWatch Event + Lambda + FIS를 조합한 구현
{
"Name": "EC2InstanceFault",
"Targets": [
{
"ResourceType": "aws:ec2:instance",
"SelectionMode": "ALL",
"FaultType": "STOP_INSTANCE"
}
]
}
3: 실시간 데이터 복제를 통한 무중단 복구 시스템 설계
1. 데이터 복제 기술 비교
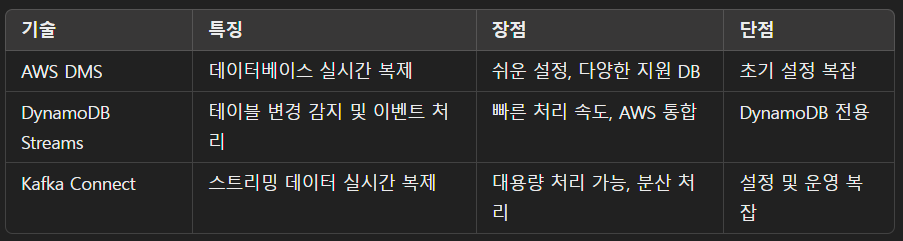
2. 무중단 복구 시나리오
1. AWS DMS + RDS Multi-AZ 구성
- 적용: 서비스 중단 없는 RDS 데이터 복제.
- 장점: 장애 발생 시 대체 DB로 자동 페일오버.
2. DynamoDB Streams + Lambda
- 적용: DynamoDB 테이블 변경 사항을 다른 리전으로 실시간 동기화.
- Lambda 코드
import boto3
def process_stream(event, context):
dynamodb = boto3.resource('dynamodb', region_name='us-east-1')
target_table = dynamodb.Table('TargetTable')
for record in event['Records']:
if record['eventName'] == 'INSERT':
target_table.put_item(Item=record['dynamodb']['NewImage'])
3. Kafka Connect 기반 실시간 데이터 복제
- 적용: 스트리밍 서비스에서 여러 데이터 소스를 통합 복제.
- 구성: Kafka Connect + AWS MSK + S3 Sink.

레거시를 이해하면서도 새로운 기술을 현실적으로 적용할 수 있는 백엔드 개발자가 되는 것이 목표입니다.