
DynamoDB가 더 나은 성능과 유연성을 제공한다는 사실, 알고 계셨나요?🧐
오늘은 완전 관리형 NoSQL 데이터베이스, DynamoDB의 기본 특성부터 모드까지 포스팅할려고합니다.!
✨ DynamoDB의 특성과 성능
DynamoDB는 빠르고 유연한 NoSQL 데이터베이스로, AWS가 서버 관리 및 백업을 처리하여 사용자는 유지보수에서 벗어날 수 있습니다.
10밀리초 미만의 빠른 성능을 제공합니다.
💡 읽기 연산과 일관성 수준
DynamoDB는 두 가지 일관성 수준(최종적 일관된 읽기, 강력한 일관된 읽기)을 제공하여, 데이터 정확성과 성능을 상황에 맞게 선택할 수 있습니다.
🔄 모드 및 백업 기능
DynamoDB는 예측 가능한 트래픽에 적합한 프로비저닝 모드와 자동으로 트래픽에 대응하는 온디맨드 모드를 지원하며, 백업 및 복구 기능은 자동으로 암호화되어 안전하게 관리됩니다.
1. DynamoDB 소개
AWS DynamoDB는 완전 관리형 NoSQL 데이터베이스 서비스로, 어떤 규모에서도 10밀리초 미만의 성능을 제공합니다. 서버리스 아키텍처를 지원하며, 자동 스케일링과 고가용성을 기본으로 제공합니다.
주요 장점
- 완전 관리형 서비스
- 자동 스케일링
- 글로벌 테이블 지원
- 서버리스 아키텍처 통합
- 내장된 보안 기능
2. 핵심 특성과 성능
데이터 일관성 수준
DynamoDB는 두 가지 읽기 일관성 모델을 제공합니다
1. 최종적 일관된 읽기 (Eventually Consistent)
- 기본 옵션
- 지연 시간: ~10ms
- 읽기 용량 단위(RCU) 1개 소비
2. 강력한 일관된 읽기 (Strongly Consistent)
- 항상 최신 데이터 보장
- 지연 시간: ~20ms
- RCU 2개 소비
가용성 아키텍처
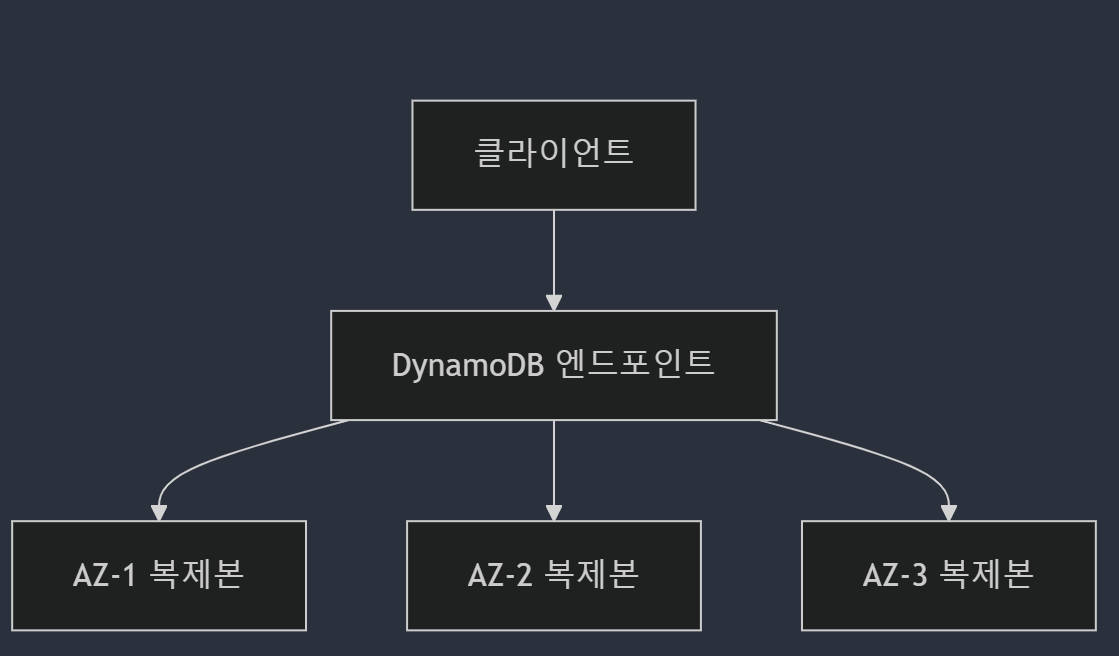
3. 운영 모드
프로비저닝 모드 CloudFormation
프로비저닝 모드는 사전에 정의된 읽기 및 쓰기 용량(throughput)을 미리 지정하고, 이를 기준으로 리소스를 관리하도록 설정하는 방식입니다.
작업량(workload)에 따라 프로비저닝된 처리량이 부족한 경우, 오토 스케일링(auto scaling)을 통해 읽기 용량(RCU, read capacity units)과 쓰기 용량(WCU, write capacity units)을 조정할 수 있습니다.
처리량을 미리 지정하기 때문에 트래픽 변동이 적은 경우 비용을 효율적으로 관리할 수 있습니다.
일정하고 예측 가능한 트래픽 패턴을 가진 경우에 적합합니다. 예상 트래픽 패턴을 정확히 파악하지 못하는 경우 용량 부족(throttling)이나 용량 낭비가 발생할 수 있습니다.
오토 스케일링을 사용하면 비용 측면에서 높은 값의 고정된 프로비저닝 용량을 사용하는 것보다 더 이득을 볼 수 있습니다.
Resources:
MyDynamoDBTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: MyTable
BillingMode: PROVISIONED
ProvisionedThroughput:
ReadCapacityUnits: 5
WriteCapacityUnits: 5
AttributeDefinitions:
- AttributeName: "PK"
AttributeType: "S"
- AttributeName: "SK"
AttributeType: "S"
KeySchema:
- AttributeName: "PK"
KeyType: "HASH"
- AttributeName: "SK"
KeyType: "RANGE"온디맨드 모드 CloudFormation
온디맨드 모드는 사용한 만큼만 비용을 지불하는 방식입니다.
트래픽이 갑자기 증가하거나 감소하더라도 DynamoDB가 자동으로 처리량을 확장하거나 축소합니다.
트래픽 패턴을 예측할 필요가 없으며, 설정에 따른 성능 문제나 요청 제한에 대해 신경 쓰지 않으셔도 됩니다. 다만, 매우 높은 트래픽이 장기간 유지되는 경우에는 비용이 급격히 증가할 수 있습니다.
Resources:
MyDynamoDBTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: MyTable
BillingMode: PAY_PER_REQUEST
AttributeDefinitions:
- AttributeName: "PK"
AttributeType: "S"
KeySchema:
- AttributeName: "PK"
KeyType: "HASH"4. 데이터 모델링
싱글 테이블 디자인
싱글 테이블 디자인은 DynamoDB의 핵심 모범 사례입니다. 아래는 전자상거래 시스템의 입니다.
// 사용자 항목
{
"PK": "USER#123",
"SK": "METADATA#123",
"name": "홍길동",
"email": "hong@example.com"
}
// 주문 항목
{
"PK": "USER#123",
"SK": "ORDER#2024-02-10",
"orderStatus": "SHIPPED",
"total": 50000
}
// 주문 상세
{
"PK": "ORDER#2024-02-10",
"SK": "ITEM#1",
"productId": "PROD#777",
"quantity": 2
}보조 인덱스 설계
GlobalSecondaryIndexes:
- IndexName: GSI1
KeySchema:
- AttributeName: "GSI1PK"
KeyType: "HASH"
- AttributeName: "GSI1SK"
KeyType: "RANGE"
Projection:
ProjectionType: "ALL"5. 고급 쿼리 패턴
복합 쿼리 예제
const params = {
TableName: "MyTable",
KeyConditionExpression:
"PK = :pk AND begins_with(SK, :sk)",
ExpressionAttributeValues: {
":pk": "USER#123",
":sk": "ORDER#2024"
}
};배치 작업 최적화
const params = {
RequestItems: {
"MyTable": [
{
PutRequest: {
Item: {
"PK": "USER#123",
"SK": "ORDER#1"
}
}
},
{
PutRequest: {
Item: {
"PK": "USER#123",
"SK": "ORDER#2"
}
}
}
]
}
};6. 성능 최적화
핫 파티션 방지 전략
1. 파티션 키 다양화
// 나쁜 예
PK: "STATUS#active"
// 좋은 예
PK: "STATUS#active#${timestamp}"2. Write Sharding
// 샤딩 접미사 추가
PK: `ORDER#${orderId}#${Math.floor(Math.random() * 10)}`효율적인 인덱스 설계
- 프로젝션 최적화
- 스파스 인덱스 활용
- 오버로딩 패턴 사용
7. 모니터링 및 운영
CloudWatch 대시보드 예시
Resources:
DynamoDBDashboard:
Type: AWS::CloudWatch::Dashboard
Properties:
DashboardName: DynamoDBMonitoring
DashboardBody: |
{
"widgets": [
{
"type": "metric",
"properties": {
"metrics": [
["AWS/DynamoDB", "ConsumedReadCapacityUnits"]
],
"period": 300,
"stat": "Sum",
"region": "us-east-1",
"title": "Read Capacity"
}
}
]
}알림 설정
Resources:
HighConsumptionAlarm:
Type: AWS::CloudWatch::Alarm
Properties:
AlarmName: DynamoDBHighConsumption
ComparisonOperator: GreaterThanThreshold
EvaluationPeriods: 1
MetricName: ConsumedWriteCapacityUnits
Namespace: AWS/DynamoDB
Period: 300
Statistic: Sum
Threshold: 10008. 실전 예제
사용자 세션 관리 시스템
// 세션 저장
const params = {
TableName: "Sessions",
Item: {
"PK": `USER#${userId}`,
"SK": `SESSION#${sessionId}`,
"ttl": Math.floor(Date.now() / 1000) + 86400,
"deviceInfo": deviceInfo,
"lastAccess": new Date().toISOString()
}
};
// 세션 조회
const params = {
TableName: "Sessions",
KeyConditionExpression:
"PK = :pk AND begins_with(SK, :sk)",
ExpressionAttributeValues: {
":pk": `USER#${userId}`,
":sk": "SESSION#"
}
};마무리
DynamoDB는 강력한 기능과 유연성을 제공하는 NoSQL 데이터베이스 라는것을 잠시나마 알게되었습니다.
적절한 설계와 최적화를 통해 고성능, 고가용성 애플리케이션 사이드 프로젝트를 만들고 싶기에
기회가 되면 요구사항에 맞는 최적의 데이터베이스를 구현 해보고 싶습니다.
