Kafka 소비자 그룹 ID 관리와 시작 위치 설정의 중요성
Kafka를 사용할 때 소비자 그룹 ID는 매우 중요한 요소입니다.
이 글에서는 소비자 그룹 ID를 관리하지 않았을 때 발생할 수 있는 문제와 이를 해결하기 위한 방법을 설명합니다.

1. 소비자 그룹 ID란?
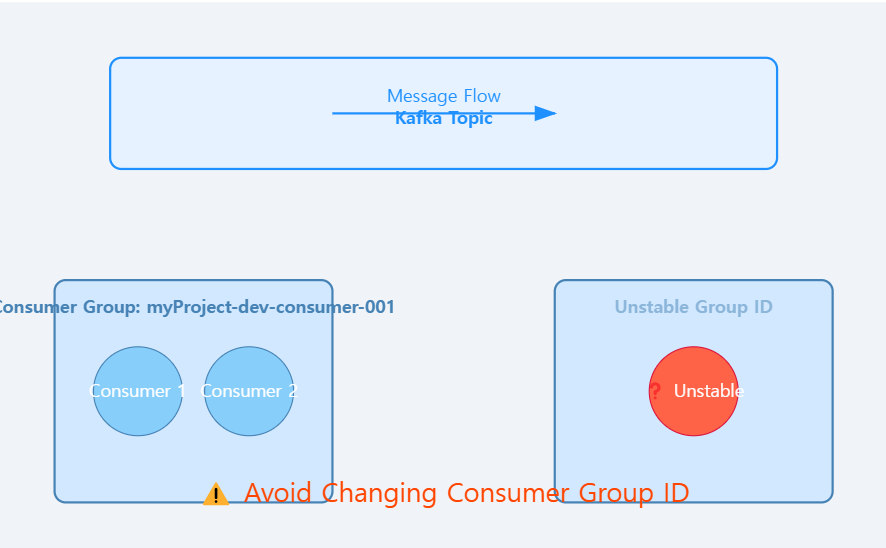
Kafka에서 소비자 그룹(Consumer Group)은 같은 ID를 공유하는 컨슈머들이 하나의 그룹으로 묶여 토픽의 메시지를 분산하여 처리하는 구조입니다.
특정 컨슈머가 토픽에서 데이터를 읽어올 때, 소비자 그룹 ID(Consumer Group ID)를 기반으로 Kafka가 해당 컨슈머가 어디까지 데이터를 읽었는지 관리합니다.
2. 소비자 그룹 ID 변경 시 발생하는 문제
만약 소비자 그룹 ID가 변경되면, Kafka는 새로운 컨슈머가 등록된 것으로 인식합니다.
이렇게 되면 Kafka는 해당 컨슈머가 관리하는 큐(Offset)를 처음부터 다시 컨슈밍하도록 이벤트를 발생시킵니다.
즉, 이미 처리한 데이터까지 다시 읽게 되어 중복 데이터 처리 문제가 발생할 수 있습니다.
⚠️ 주의: 소비자 그룹 ID를 관리하지 않고 기본값(랜덤 값)으로 설정하면
언제부터 데이터를 소비하는지 파악하기 어렵고,
중복된 데이터 처리가 발생할 가능성이 큽니다.
3. 해결 방법: 소비자 그룹 ID 관리와 시작 위치 설정
이러한 문제를 방지하기 위해서는 소비자 그룹 ID를 명확한 네이밍 규칙으로 관리하는 것이 중요합니다.

✅ 소비자 그룹 ID 네이밍 규칙
- 프로젝트명 + 환경(개발/운영) + 역할 + 고유번호
- 예: myProject-dev-consumer-001
이렇게 하면 같은 소비자 그룹을 유지하면서 불필요한 중복 컨슈밍을 방지할 수 있습니다.
✅ 추가 해결 방법: 시작 위치 타임스탬프 설정
Kafka에서 컨슈머가 데이터를 읽어오는 시작 위치(Offset)을 직접 지정할 수도 있습니다.
📌 시작 위치 설정 옵션
- LATEST → 가장 최신 데이터부터 읽기
- EARLIEST → 큐의 가장 처음부터 읽기
- TIMESTAMP → 특정 시점 이후의 데이터부터 읽기
특히, 중복 데이터 문제를 방지하기 위해 타임스탬프(Timestamp) 기준으로 시작 위치를 설정할 수 있습니다.
이렇게 하면 과거 데이터는 무시하고 앞으로 들어올 데이터만 컨슈밍하도록 설정할 수 있습니다.
🛠️ 예제 설정
특정 시간 이후 데이터만 컨슈밍하도록 설정할 경우
- 타임스탬프 설정: 2016/09/01 00:00:00.000
4. 결론
Kafka의 소비자 그룹 ID를 적절히 관리하지 않으면 데이터 중복 소비 및 혼란이 발생할 수 있습니다.
이를 방지하기 위해
✔ 소비자 그룹 ID를 명확한 네이밍 규칙으로 설정
✔ 시작 위치를 타임스탬프로 설정하여 중복 데이터를 방지
이 두 가지 원칙을 잘 지키면 Kafka의 컨슈밍 프로세스를 보다 안정적으로 운영할 수 있습니다. 🚀
