
우리는 Job을 알고, Job 안에 Step이 있으며,
Step 안에 ItemReader, ItemProcessor, ItemWriter가 있다는 사실을 알았습니다.
이제 이를 구현해 보겠습니다.
Job, Step 간단 코드
@Slf4j
@Configuration
@RequiredArgsConstructor
public class SyncJob {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Bean(name = "syncKwJob")
public Job syncJob(Step syncStep) {
log.info(">>>syncJob");
return jobBuilderFactory.get("syncKwJob")
.start(syncStep)
.build();
}
@JobScope
@Bean("syncStep")
public Step syncStep(ItemReader<ReplaceKw> trReplaceKwReader, ItemProcessor<ReplaceKw, ReplaceKw> trReplaceKwProcessor, ItemWriter<ReplaceKw> trReplaceKwWriter) {
log.info(">>syncStep");
return stepBuilderFactory.get("syncStep")
.<ReplaceKw, ReplaceKw>chunk(5) // 제네릭 타입을 명확하게 명시
.reader(trReplaceKwReader)
.processor(trReplaceKwProcessor)
.writer(trReplaceKwWriter)
.build();
}
}
JOB
Job 별거 없습니다.
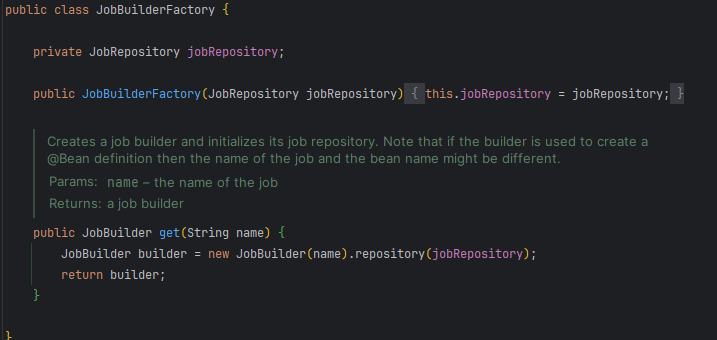
JobBuilderFactory에 Job을 추가하고, Step도 명시해 주시면 됩니다.
JobBuilderFactory는 Job을 실행시키기 위한 JobBuilder를 생성합니다.
get() 메서드를 통해 인자로 받은 name으로 JobBuilder를 생성합니다.
Step
Step StepBuilderFactory도 보이는데, reader, processor, writer와 같은 메서드도
확인할 수 있습니다.
StepBuilderFactory
StepBuilder를 생성하는 팩토리 클래스로, get() 메서드를 통해 인자로
받은 name으로 StepBuilder를 생성합니다.
이 코드는 JobBuilderFactory와 동일하여 코드를 생략했습니다.
StepBuilder
Step을 구성하는 설정 조건에 따라 다섯 개의 하위 빌더 클래스를 생성하고,
실제 Step 생성을 위임합니다.
Step을 구성하는 설정 조건에는 Tasklet 방식, ChunkOrientedTasklet 방식,
멀티 쓰레드 방식 등이 있으며, 이러한 방식에 따라 빌더가 결정됩니다.
SpringBuilder에 있는 <T, T>Chunk는 <reader에서 읽을 데이터 타입,
writer에서 받을 데이터 타입>으로, 몇 개씩 덩어리로 만들지 결정합니다.
ChunkOrientedTasklet
Step은 여러 방식으로 실행된다고 말씀드렸습니다.
그 중 Tasklet은 복잡한 로직을 반복 수행하고,
Chunk는 reader, processor, writer에 따라 데이터를 가공할 수 있습니다.
이 Chunk 지향 프로세싱에 대해 설명하겠습니다.
[개념]
1. ItemReader, ItemProcessor, ItemWriter로 데이터 입력, 가공, 출력을 담당합니다.
2. TaskletStep에 의해 반복 실행되며, ChunkOrientedTasklet이 실행될 때마다
새로운 트랜잭션이 생성되어 처리가 이루어집니다.
- 구현체
- ChunkProvider: ItemReader를 핸들링합니다.
- ChunkProcessor: ItemProcessor, ItemWriter를 핸들링합니다.
ItemReader,ItemProcessor,ItemWriter구현
private ItemReader<String> itemReader() {
return new ListItemReader<>(getItems());
}
⠀
private ItemProcessor<String, String> itemProcessor() {
return item -> item + " now processor!!";
}
⠀
private ItemWriter<String> itemWriter() {
return items -> log.info("### writer : " + items.toString());
}-
ItemReader: getItems()에서 가져온 List를 반환합니다.
다양한 입력으로부터 데이터를 읽어서 제공하는 인터페이스입니다.
파일 스트림을 열거나 종료, DB 커넥션을 열거나 종료, 입력 장치 초기화 등의 작업을 합니다. ExecutionContext는 read와 관련된 여러 가지 상태 정보를 저장하여
재시작 시 참조하도록 지원합니다. -
ItemProcessor: 가져온 Item에 문자열을 더해서 처리합니다.
데이터를 가공, 변형, 필터링합니다.
null을 반환할 경우, Chunk에 저장되지 않아 ItemWriter로 전달되지 않습니다. -
ItemWriter: Chunk size대로 읽은 String을 List로 출력합니다.
ItemReader와 1대 1 매칭이 되는 데이터 종류들을 전달받습니다.
아이템 하나가 아닌 아이템 리스트를 전달받습니다.
ItemStream
ItemReader와 ItemWriter 처리 과정 중 상태를 저장하고 오류 발생 시 실패한 곳에서 재실행하도록 지원합니다.
리소스를 열고 닫거나 초기화하는 경우 사용하며,
ExecutionContext를 매개변수로 받아 상태 정보를 업데이트합니다.
ItemReader와 ItemWriter는 이 ItemStream을 구현하고 있습니다.
