오늘은 "왜 우리가 알던 아름다운 REST API와 관계형 엔티티 설계가 LLM 앞에서는 무용지물이 되는지", 그리고 "진정한 AI-Ready API는 어떤 모습이어야 하는지"에 대해 깊이 있게 이야기해 보겠습니다.
LLM이 당신의 REST API를 싫어하는 이유
(feat. AI 친화적 API 설계법)
최근 스터디와 여러 기술 세미나를 거치며 큰 충격을 받았습니다.
우리가 그토록 정석이라 믿고 따랐던 '엔티티 기반의 무결성'과 'RESTful API'가, AI 시대에는 오히려 발목을 잡는 레거시가 될 수 있다는 사실 때문입니다.
왜 그런지, 핵심적인 이유 4가지를 짚어보겠습니다.
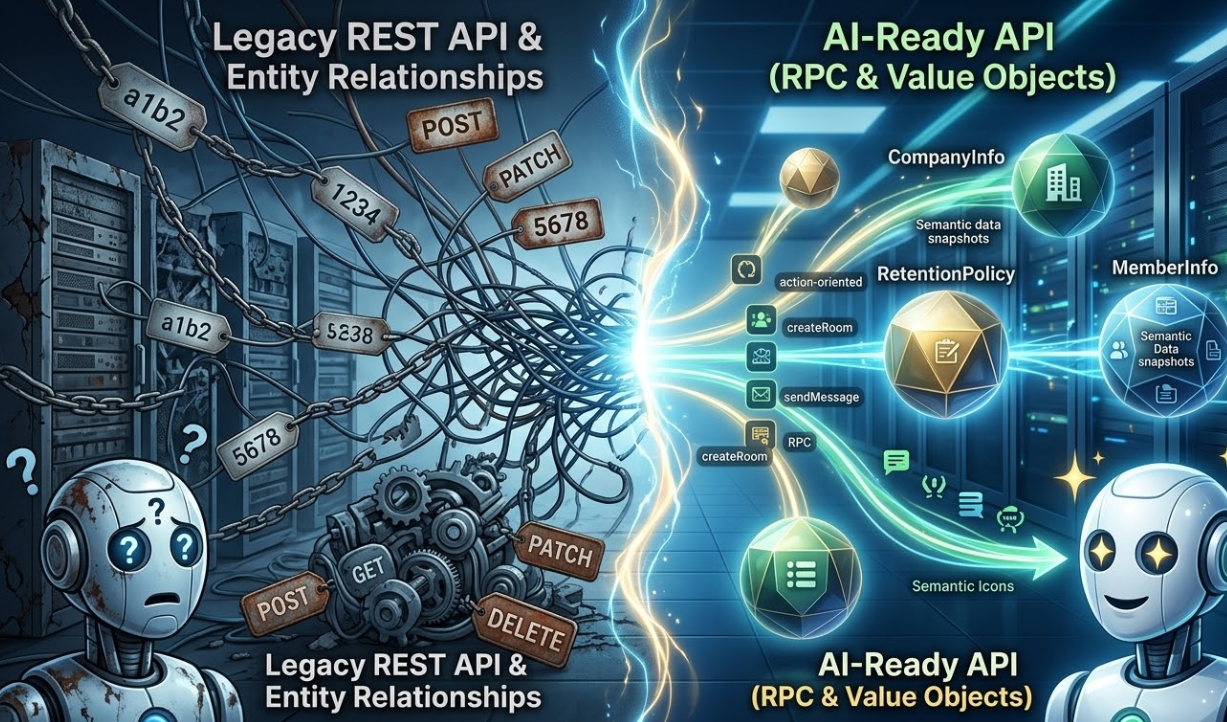
1. LLM은 '의미 없는 ID'에 매우 취약하다
전형적인 관계형 DB 설계에서 우리는 회사를 만들면 companyId를 얻고, 이를 이용해 정책을 만들어 policyId를 얻으며, 최종적으로 이 두 ID를 조합해 채팅방을 만듭니다.
인간 개발자는 이 절차를 코드로 짜서 변수에 ID를 담아두고 일관성 있게 사용합니다.
하지만 LLM에게 ID는 자연어처리 관점에서 아무런 의미가 없는 토큰 쪼가리에 불과합니다.
- 학습 데이터에 이런 무작위 ID의 패턴이 존재할 리 없습니다.
- LLM은 이 무의미한 토큰에 어텐션을 부여하기 어려워합니다.
- 여러 턴의 대화가 이어지면, LLM은 이 ID를 까먹거나 비슷하게 생긴 다른 ID를 지어내는 할루시네이션을 엄청난 확률로 발생시킵니다.
즉, 무의미한 참조 키에 기대어 멀티턴으로 API를 정상 호출할 것이라 기대하는 것은 무리입니다.
2. 엔티티 관계 추론 vs 값객체의 완결성
엔티티 간의 1:N, M:N 관계나 도메인의 복잡한 직교성을 이해하려면 LLM은 엄청난 '컨텍스트 예산'과 '추론 능력'을 낭비해야 합니다.
"이 정책 ID가 저 회사 ID와 매칭되는 게 맞나?"를 매번 고민하게 만드는 구조 자체가 문제인 것이죠.
여기서 지난 시간에 강조했던 값객체가 빛을 발합니다.
값객체는 외부 ID를 참조하는 대신, 그 자체로 완결된 하나의 세계를 가집니다.
정보 내에 비의미론적인 ID 참조를 최대한 배제하고, "현재 이 채팅방의 상태는 이러하다"라는 완전한 문맥을 한 번에 LLM에게 던져주면, LLM은 불필요한 추론 없이 자연스럽게 상황을 이해하고 다음 행동을 결정할 수 있습니다.
3. 멱등성과 부수효과의 통제
LLM은 본질적으로 논리적인 일관성이나 완벽한 기억력을 가진 주체가 아닙니다.
원하는 결과가 안 나오면, 혹은 오류 메시지가 모호하면 자신이 만족할 때까지 똑같은 생성/수정/삭제 요청을 반복하는 경향이 있습니다.
-
멱등성 확보
동일한 식별자나 동일한 컨텍스트의 요청이 여러 번 들어와도 시스템 상태가 한 번만 변경되도록 혹은 동일한 결과를 반환하도록 만들어야 합니다.
에러를 뱉기보다는 멱등적인 결과를 반환하는 것이 대화 흐름을 이어가는 데 훨씬 유리합니다. -
복원 가능성
롤백, 취소 기능은 물론이고dry-run작업을 실제로 수행하기 전에 결과만 미리 예상해 보는 기능 을 제공하여, 최종 확정 전에 LLM이나 인간 사용자가 검증할 수 있는 안전망이 필수입니다. -
명확한 에러 메시지
에러가 났을 때{code: 1234, messageKey: "ERROR_01"}같은 비언어적 응답은 최악입니다. LLM이 이해하고 다음 행동을 수정할 수 있도록 "질문한 키워드에 대한 26년 1월 20일까지의 검색 결과는 없습니다."처럼 풍부한 자연어로 응답해야 합니다.
4. 리소스 중심의 REST API vs 행동 중심의 RPC
가장 뼈맞은 부분입니다.
우리는 "채팅방을 만들고 '반가워요'라고 인사해 줘"라는 미션을 줄 때, REST API가 얼마나 LLM에게 불친절한지 알아야 합니다.
[REST API의 접근]
POST /chatRooms {payload: "무제"}호출 -> 응답으로{id: 123}획득POST /123/messages {payload: "반가워요. LLM토론방입니다"}호출
REST는 문제를 '리소스의 상태 변화'로 번역해야 합니다.
인간은 이 패러다임에 훈련되어 있지만, LLM에게는 너무 복잡한 추론 과정입니다.
[RPC의 접근]
createRoom(title)sendMessage(roomId, message)
이 얼마나 자연어에 가깝고 직관적인가요? AI 친화적인 API는 요청과 응답이 자연어의 맥락에 가까울수록, 그리고 구조적인 포맷 JSON의 괄호 같은 비언어적 기호 에 덜 의존할수록 오류 확률이 극적으로 낮아집니다.
마무리
이번 스터디를 통해 지난 개발했던시간들이 "이게 정답이야!"라고 믿어왔던 백엔드 설계 철학이 크게 흔들리는, 이른바 '행복한 멘붕'을 겪었습니다.
그동안 저는 어떻게 하면 URI를 더 예쁘게 짤까, 어떻게 하면 중복 데이터를 없애고 테이블 정규화를 완벽하게 할까만 고민해 왔습니다.
하지만 AI Agent 시대에 진입하면서 "사용자가 문맥을 잃지 않고 쉽게 쓸 수 있는가?"라는 본질적인 질문 앞에서는 그 모든 레거시 관행이 장애물이 될 수 있음을 깨달았습니다.
채팅창에서 누군가 남겨주신 "개발자일수록 더 감이 없을 때가 많아요. 익숙한 하늘이 존재하는 게 당연한 것처럼."이라는 말이 유독 귓가를 맴돕니다.
우리가 당연하게 여기던 식별자 참조 로직이나 REST의 제약들이, 정작 기계가 시스템을 제어하는 시대에는 철저히 재평가되어야 한다는 사실을요.
앞으로는 AI를 위한 API를 설계할 때, "이 파라미터가 정말 LLM에게 직관적인가?", "멀티턴 대화 중에도 무결성을 유지할 수 있도록 값객체 단위로 설계되었는가?"를 가장 먼저 고민하는 개발자로 거듭나야겠습니다.
NoSQL에서 반강제적으로 쓰이던 비정규화와 도큐먼트 지향 설계가, 이제는 AI라는 강력한 무기를 만나 백엔드의 새로운 표준이 되어가는 과정을 지켜보는 것이 무척이나 흥미롭습니다!
