
ItemReader, ItemProcessor, ItemWriter의 역할과 동작 원리
제가 작성한 ChunkOrientedTasklet이 무한 루프를 돌기 시작했습니다. 정확히 말하자면, 처음부터 무한히 돌기 시작한 것이지요.

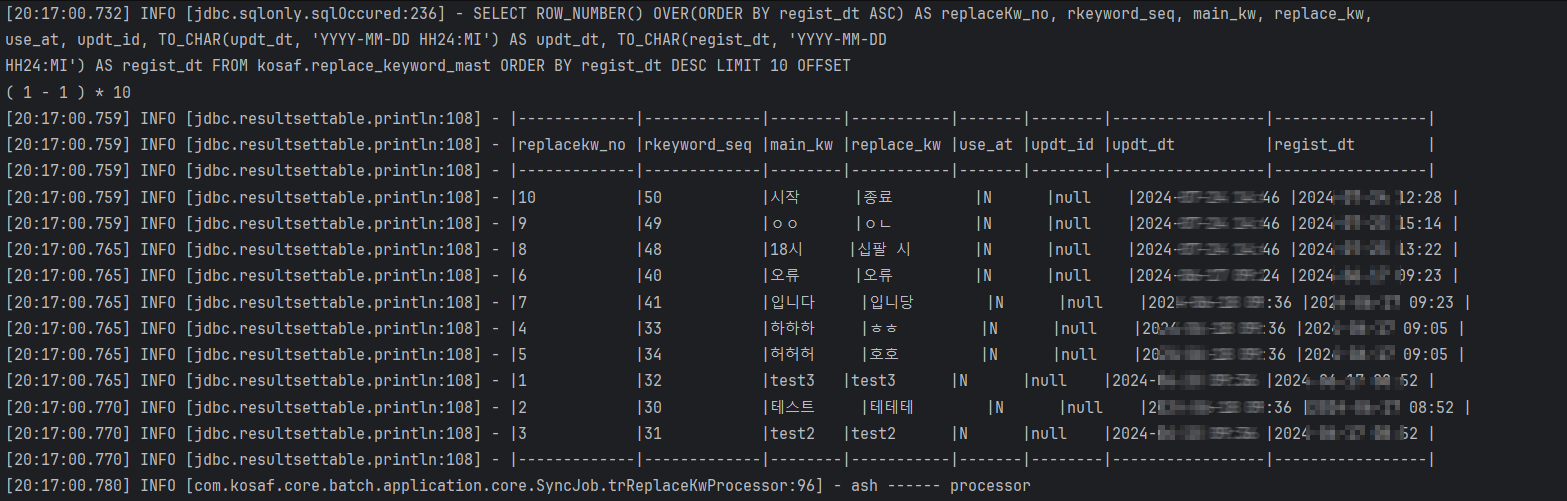

ItemReader, ItemProcessor, ItemWriter를 수행한 후 제가 심어놓은 로그는 찍히지도 않고, 단지 무한히 DB에서 값을 가져오는 상황이었습니다.
아니, Reader로 chunk 사이즈만큼 읽어온 데이터를 하나씩 Processor에서 가공하고,
모은 것을 Writer에서 저장하며, 다시 Reader에서 chunk만큼 읽어오는 것이 아니라는
말인가요?
좀 더 깊이 파고들어야 할 것 같습니다.
ChunkOrientedTasklet?
ChunkOrientedTasklet에 대해 설명하자면,
chunk 단위로 반복되는 Tasklet을 실행하는 구조로 보입니다.
구글링한 결과, 실제로 Tasklet을 구현한
ChunkOrientedTasklet 클래스를 찾을 수 있었습니다.
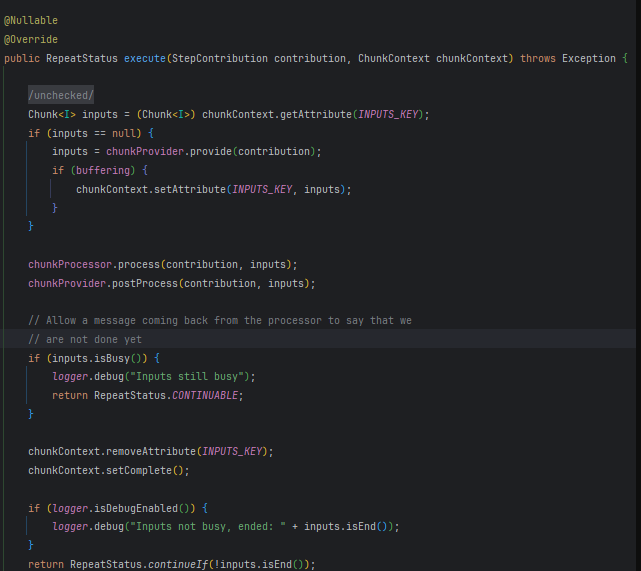
이 클래스에서 제 코드를 실행하는 메소드는 execute라고 합니다.
chunkProvider.provide(contribution)을 통해 데이터를 읽어오며,
제가 구현한 ItemReader를 이용하여 chunkSize만큼 데이터를 가져옵니다.
그리고 chunkProcessor.process(contribution, inputs)를 통해
데이터를 가공하고 저장하는데, 여기서 ItemProcessor와 ItemWriter를 사용합니다.
Provide
ChunkProvider를 구현한 SimpleChunkProvider의 provide 메소드입니다.
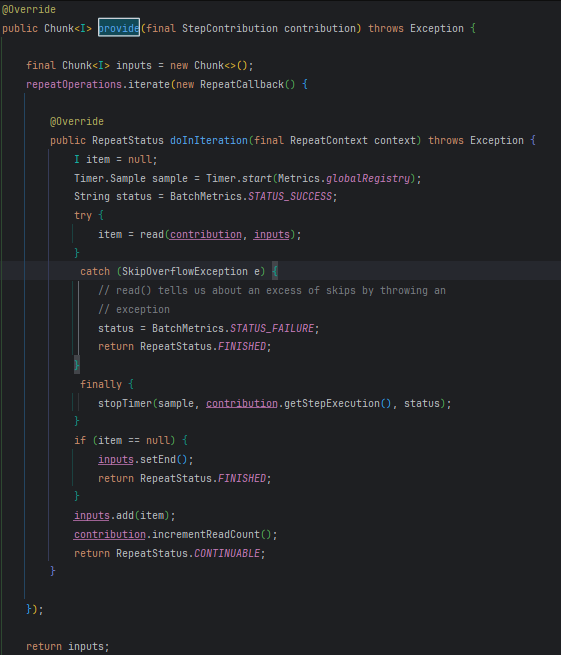
repeatOperations.iterate(new RepeatCallback() {/*내용*/}); 코드를 통해 반복자를 사용함을 확인할 수 있습니다.
이 함수는 chunkSize만큼 데이터가 쌓일 때까지 반복됩니다.
여기서 데이터는 read라는 함수를 통하여 처리됩니다.
이 read는 아래의 doread를 호출합니다.
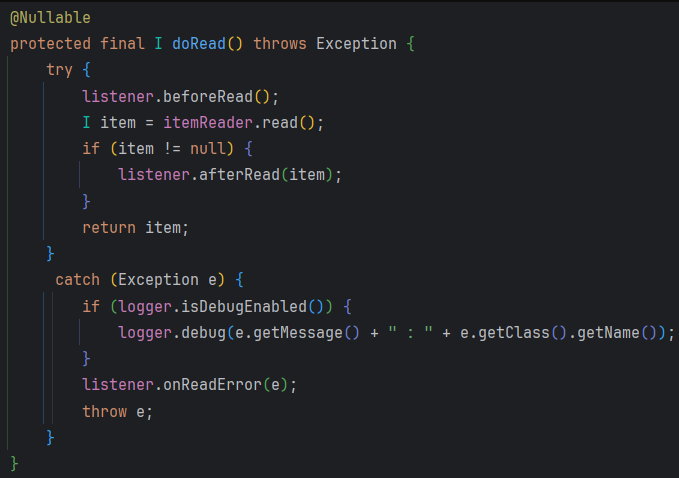
여기서 itemReader.read()는 제가 설정한 ItemReader 데이터를 조회하고, chunkSize가 될 때까지 데이터를 쌓습니다.
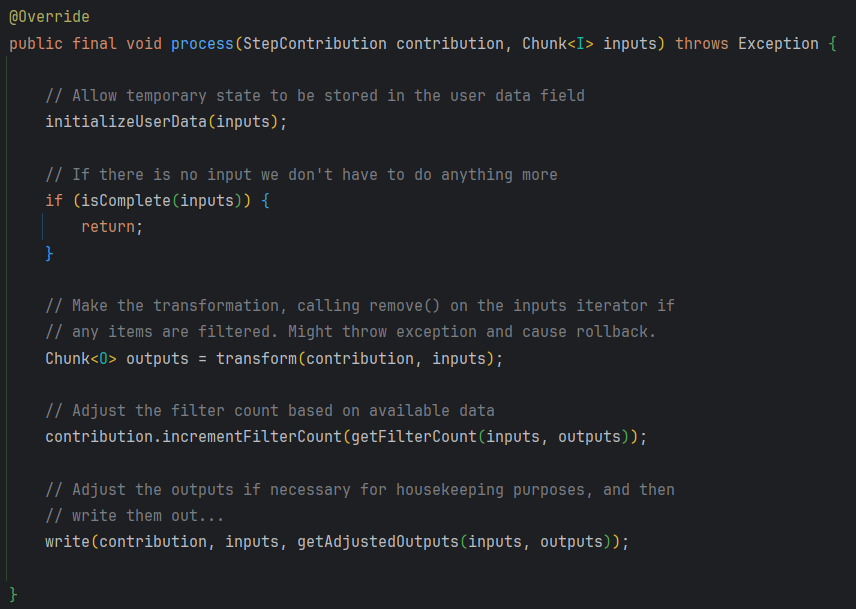
process에서는 ChunkProcessor를 구현한 SimpleChunkProcessor의 process 메소드가 호출되며, 여기서 먼저 transform 함수를 호출합니다.
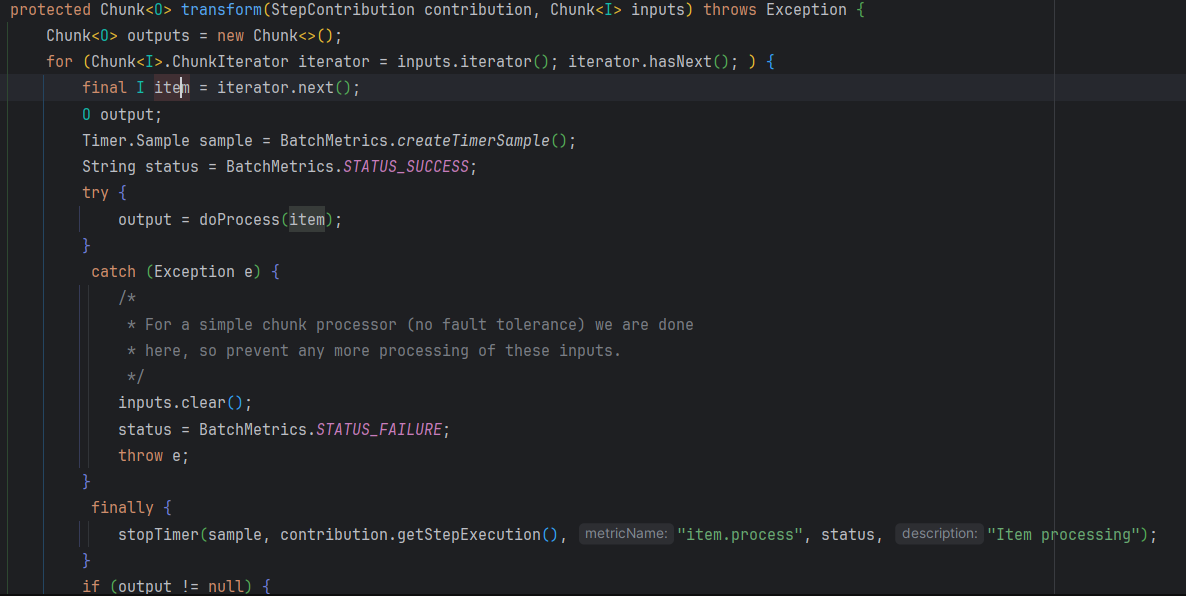
해당 함수에서는 반복자로 iterator.next()를 계속 호출하여 데이터를 하나씩 가져오고, doProcess를 통해 데이터 가공을 진행합니다.
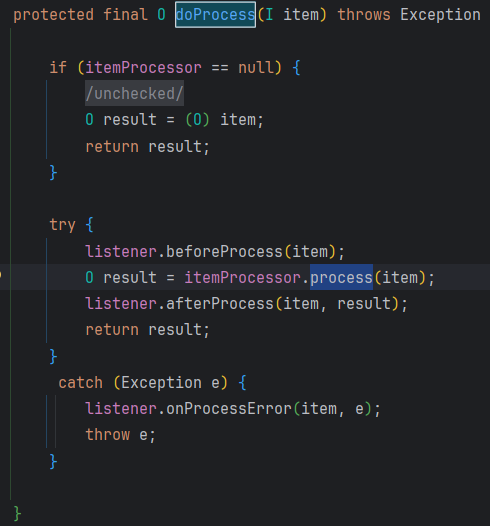
이 과정에서 제가 구현한 ItemProcessor를 통해 데이터를 가공하고 반환합니다.
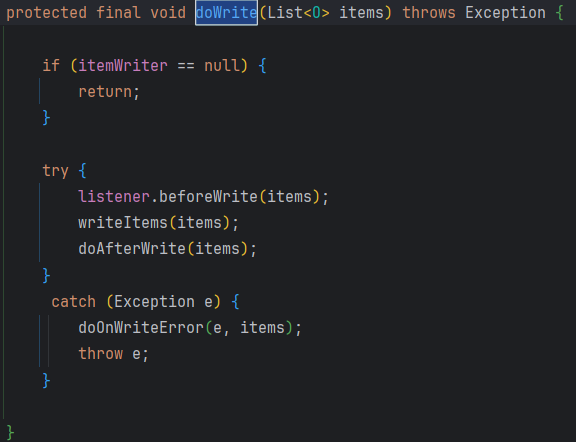
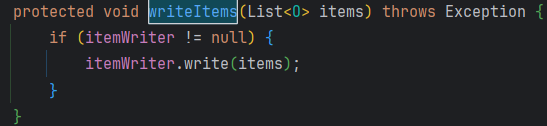
마지막으로 writer는 doWrite를 호출하며, 그 안에서 제가 구현한 ItemWriter가 실행됩니다.
따라서,
- Reader는 반복을 통해 읽어온 데이터의 수가 chunkSize와 같을 때까지 데이터를 하나씩 읽어오고,
- Processor는 반복자를 통해 Reader에서 읽어온 데이터를 하나하나 가공하며,
- Writer는 읽어온 chunk 단위의 데이터를 저장합니다.
그렇다면, 왜 제 코드는 무한 반복을 도는 것인지 이해가 되지 않네요.
[출처]
