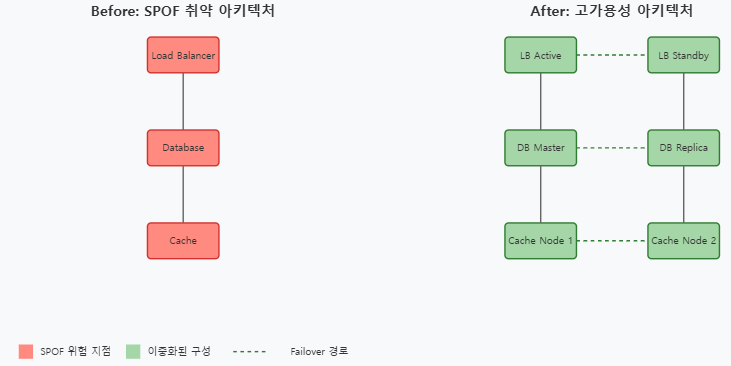
1. SPOF의 개념과 위험성
SPOF(Single Point of Failure)는 시스템의 특정 지점이 실패할 경우 전체 시스템의 동작이 중단되는 취약점을 의미합니다.
대규모 시스템에서 SPOF는 치명적인 서비스 중단을 초래할 수 있으며, 이는 직접적인 비즈니스 손실로 이어질 수 있습니다.
1.1 실제 SPOF 사례 분석
2019년 한 대형 전자상거래 플랫폼에서 발생했던 실제 장애 사례를 분석해보겠습니다.
장애 개요:
- 발생 시간: 2019년 블랙프라이데이 세일 기간
- 원인: 주문 처리 서비스의 단일 Redis 인스턴스 장애
- 영향: 4시간 동안 전체 주문 시스템 마비
- 손실: 약 20억원의 매출 손실 추정2. 고급 SPOF 탐지 전략
2.1 인프라스트럭처 레벨 모니터링
@Component
public class InfrastructureMonitor {
private final MetricRegistry metrics;
@Scheduled(fixedRate = 30000)
public void checkSystemRedundancy() {
// 로드밸런서 상태 확인
HealthStatus lbStatus = loadBalancerHealthCheck();
metrics.meter("loadbalancer.health").mark(lbStatus.isHealthy() ? 1 : 0);
// 데이터베이스 복제 지연 모니터링
Duration replicationLag = checkDatabaseReplicationLag();
metrics.histogram("database.replication.lag").update(replicationLag.toMillis());
// 캐시 클러스터 상태 확인
Map<String, CacheNodeStatus> cacheStatus = checkCacheClusterHealth();
metrics.gauge("cache.cluster.health", () ->
() -> cacheStatus.values().stream()
.filter(CacheNodeStatus::isHealthy)
.count());
}
}2.2 의존성 체인 분석
@Service
public class DependencyAnalyzer {
private final Graph<ServiceNode, DependencyEdge> dependencyGraph = new DefaultDirectedGraph<>(DependencyEdge.class);
public List<ServiceNode> findCriticalPaths() {
return new CriticalPathAlgorithm<>(dependencyGraph)
.findCriticalPaths()
.stream()
.filter(path -> path.getRedundancyScore() < 0.5)
.collect(Collectors.toList());
}
@Data
public class ServiceNode {
private String serviceName;
private int instanceCount;
private boolean hasFailover;
private double availability;
public double calculateRedundancyScore() {
return (instanceCount > 1 ? 0.5 : 0) +
(hasFailover ? 0.3 : 0) +
(availability > 0.999 ? 0.2 : 0);
}
}
}3. SPOF 해결을 위한 고급 아키텍처 패턴
3.1 데이터베이스 클러스터링
@Configuration
public class DatabaseClusterConfig {
@Bean
public DataSource routingDataSource() {
Map<Object, Object> targetDataSources = new HashMap<>();
// 마스터 DB 구성
HikariConfig masterConfig = new HikariConfig();
masterConfig.setJdbcUrl("jdbc:postgresql://master:5432/db");
masterConfig.setReadOnly(false);
// 읽기 전용 레플리카 구성
List<HikariDataSource> replicas = IntStream.range(0, 3)
.mapToObj(i -> {
HikariConfig replicaConfig = new HikariConfig();
replicaConfig.setJdbcUrl("jdbc:postgresql://replica" + i + ":5432/db");
replicaConfig.setReadOnly(true);
return new HikariDataSource(replicaConfig);
})
.collect(Collectors.toList());
// 로드밸런싱 전략 구성
return new LoadBalancedDataSource(
new HikariDataSource(masterConfig),
replicas,
new RoundRobinStrategy()
);
}
}
public class LoadBalancedDataSource extends AbstractRoutingDataSource {
private final DataSource masterDataSource;
private final List<DataSource> replicaDataSources;
private final LoadBalancingStrategy loadBalancingStrategy;
@Override
protected Object determineCurrentLookupKey() {
if (TransactionSynchronizationManager.isCurrentTransactionReadOnly()) {
return loadBalancingStrategy.chooseReplica(replicaDataSources);
}
return masterDataSource;
}
}3.2 분산 캐시 클러스터
@Configuration
public class RedisSentinelConfiguration {
@Bean
public RedisConnectionFactory redisConnectionFactory() {
RedisSentinelConfiguration sentinelConfig = new RedisSentinelConfiguration()
.master("mymaster")
.sentinel("redis-sentinel-1", 26379)
.sentinel("redis-sentinel-2", 26379)
.sentinel("redis-sentinel-3", 26379);
LettuceClientConfiguration clientConfig = LettuceClientConfiguration.builder()
.commandTimeout(Duration.ofSeconds(2))
.shutdownTimeout(Duration.ZERO)
.build();
return new LettuceConnectionFactory(sentinelConfig, clientConfig);
}
@Bean
public RedisTemplate<String, Object> redisTemplate() {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory());
template.setKeySerializer(new StringRedisSerializer());
template.setHashKeySerializer(new StringRedisSerializer());
template.setHashValueSerializer(new JdkSerializationRedisSerializer());
template.setValueSerializer(new JdkSerializationRedisSerializer());
return template;
}
}3.3 서비스 디스커버리와 로드밸런싱
@Configuration
public class ServiceDiscoveryConfig {
@Bean
public ServiceRegistry serviceRegistry(
DiscoveryClient discoveryClient,
LoadBalancerClient loadBalancer) {
return new ServiceRegistry(discoveryClient, loadBalancer) {
@Override
public ServiceInstance chooseService(String serviceId) {
List<ServiceInstance> instances = discoveryClient.getInstances(serviceId);
// 헬스체크 실패한 인스턴스 제외
instances = instances.stream()
.filter(this::isHealthy)
.collect(Collectors.toList());
if (instances.isEmpty()) {
throw new NoAvailableInstanceException(serviceId);
}
// 가중치 기반 로드밸런싱 적용
return loadBalancer.choose(serviceId, instances);
}
private boolean isHealthy(ServiceInstance instance) {
try {
RestTemplate restTemplate = new RestTemplate();
ResponseEntity<Health> health = restTemplate.getForEntity(
instance.getUri() + "/actuator/health",
Health.class
);
return health.getBody().getStatus() == Status.UP;
} catch (Exception e) {
return false;
}
}
};
}
}4. SPOF 개선 사례 연구
4.1 결제 시스템 SPOF 개선 사례
기존 아키텍처의 문제점
1. 단일 결제 처리 서버
2. 단일 데이터베이스
3. 동기식 외부 API 호출개선된 아키텍처
@Configuration
public class PaymentProcessorConfig {
@Bean
public PaymentProcessor resilientPaymentProcessor(
CircuitBreakerFactory circuitBreakerFactory,
KafkaTemplate<String, PaymentEvent> kafkaTemplate) {
return new ResilientPaymentProcessor(
circuitBreakerFactory.create("payment-circuit"),
kafkaTemplate,
paymentProperties
);
}
}
@Service
@Slf4j
public class ResilientPaymentProcessor implements PaymentProcessor {
private final CircuitBreaker circuitBreaker;
private final KafkaTemplate<String, PaymentEvent> kafkaTemplate;
private final PaymentProperties properties;
@Override
public PaymentResult processPayment(PaymentRequest request) {
// 서킷 브레이커 패턴 적용
return circuitBreaker.run(
() -> processPaymentWithRetry(request),
throwable -> handlePaymentFailure(request, throwable)
);
}
private PaymentResult processPaymentWithRetry(PaymentRequest request) {
return Retry.decorateFunction(
RetryConfig.<PaymentResult>custom()
.maxAttempts(3)
.waitDuration(Duration.ofMillis(100))
.build(),
paymentRequest -> {
// 비동기 이벤트 발행
kafkaTemplate.send("payment-events",
new PaymentEvent(request, PaymentStatus.PROCESSING));
// 실제 결제 처리
PaymentResult result = doProcessPayment(request);
// 결과 이벤트 발행
kafkaTemplate.send("payment-events",
new PaymentEvent(request, result.getStatus()));
return result;
}
).apply(request);
}
private PaymentResult handlePaymentFailure(
PaymentRequest request, Throwable throwable) {
log.error("Payment processing failed", throwable);
// 보상 트랜잭션 처리
kafkaTemplate.send("payment-compensation",
new PaymentCompensationEvent(request));
return PaymentResult.failure(
request.getPaymentId(),
FailureReason.SYSTEM_ERROR
);
}
}4.2 데이터베이스 SPOF 해결 사례
멀티 리전 데이터베이스 구성
@Configuration
public class MultiRegionDatabaseConfig {
@Bean
public DataSource multiRegionDataSource() {
// 리전별 데이터소스 구성
Map<Region, DataSource> regionalDataSources = new EnumMap<>(Region.class);
Arrays.stream(Region.values()).forEach(region -> {
regionalDataSources.put(region, createRegionalDataSource(region));
});
return new MultiRegionRoutingDataSource(
regionalDataSources,
new RegionAwareRoutingStrategy(regionResolver)
);
}
@Bean
public TransactionManager distributedTransactionManager() {
return new ChainedTransactionManager(
// 리전별 트랜잭션 매니저 구성
regionalTransactionManagers.stream()
.map(tm -> new ResourceTransactionManager(tm))
.collect(Collectors.toList())
);
}
private DataSource createRegionalDataSource(Region region) {
HikariConfig config = new HikariConfig();
config.setJdbcUrl(region.getJdbcUrl());
config.setUsername(region.getUsername());
config.setPassword(region.getPassword());
// 커넥션 풀 최적화
config.setMaximumPoolSize(50);
config.setMinimumIdle(10);
config.setConnectionTimeout(2000); // 2초
return new HikariDataSource(config);
}
}
@Slf4j
public class MultiRegionRoutingDataSource extends AbstractRoutingDataSource {
private final Map<Region, DataSource> regionalDataSources;
private final RegionAwareRoutingStrategy routingStrategy;
@Override
protected Object determineCurrentLookupKey() {
Region currentRegion = routingStrategy.determineCurrentRegion();
log.debug("Routing to database in region: {}", currentRegion);
return currentRegion;
}
public void handleRegionFailure(Region failedRegion) {
log.warn("Region {} failed, activating failover", failedRegion);
routingStrategy.markRegionDown(failedRegion);
// 자동 페일오버 프로세스 시작
Region failoverRegion = routingStrategy.determineFailoverRegion(failedRegion);
if (failoverRegion != null) {
log.info("Failing over to region: {}", failoverRegion);
routingStrategy.setPreferredRegion(failoverRegion);
}
}
}5. SPOF 예방을 위한 아키텍처 설계 원칙
5.1 확장성 있는 메시지 큐 시스템 구축
@Configuration
public class MessageQueueConfig {
@Bean
public KafkaTemplate<String, Object> kafkaTemplate(
ProducerFactory<String, Object> producerFactory) {
return new KafkaTemplate<>(producerFactory);
}
@Bean
public ProducerFactory<String, Object> producerFactory() {
Map<String, Object> config = new HashMap<>();
// 고가용성을 위한 설정
config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
"kafka1:9092,kafka2:9092,kafka3:9092");
config.put(ProducerConfig.ACKS_CONFIG, "all");
config.put(ProducerConfig.RETRIES_CONFIG, 3);
config.put(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, 1);
// 메시지 순서 보장
config.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
return new DefaultKafkaProducerFactory<>(config);
}
@Bean
public ConsumerFactory<String, Object> consumerFactory() {
Map<String, Object> config = new HashMap<>();
// 컨슈머 그룹 설정으로 이중화
config.put(ConsumerConfig.GROUP_ID_CONFIG, "resilient-consumer-group");
config.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
config.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
return new DefaultKafkaConsumerFactory<>(config);
}
}5.2 서비스 헬스체크 및 자동 복구
@Service
@Slf4j
public class ServiceHealthMonitor {
private final ScheduledExecutorService scheduler =
Executors.newScheduledThreadPool(4);
private final Map<String, ServiceHealth> serviceHealthMap =
new ConcurrentHashMap<>();
@PostConstruct
public void startMonitoring() {
scheduler.scheduleAtFixedRate(
this::performHealthChecks,
0, 30, TimeUnit.SECONDS
);
}
private void performHealthChecks() {
serviceHealthMap.forEach((serviceId, health) -> {
try {
boolean isHealthy = checkServiceHealth(serviceId);
health.updateStatus(isHealthy);
if (!isHealthy && health.getFailureCount() >= 3) {
initiateAutomaticRecovery(serviceId);
}
} catch (Exception e) {
log.error("Health check failed for service: " + serviceId, e);
}
});
}
private void initiateAutomaticRecovery(String serviceId) {
log.warn("Initiating automatic recovery for service: {}", serviceId);
CompletableFuture.runAsync(() -> {
try {
// 서비스 재시작 시도
restartService(serviceId);
// 상태 확인
if (checkServiceHealth(serviceId)) {
log.info("Service recovery successful: {}", serviceId);
serviceHealthMap.get(serviceId).reset();
} else {
// 백업 서비스로 전환
switchToBackupService(serviceId);
}
} catch (Exception e) {
log.error("Recovery failed for service: " + serviceId, e);
alertOperations(serviceId, e);
}
});
}
}6. 결론 및 베스트 프랙티스
6.1 주요 SPOF 방지 체크리스트
1. 인프라스트럭처 레벨
- 모든 중요 컴포넌트의 이중화 구성
- 자동 페일오버 메커니즘 구현
- 다중 가용영역/리전 배포
2. 애플리케이션 레벨
- 서킷 브레이커 패턴 적용
- 비동기 처리 및 메시지 큐 활용
- 타임아웃 및 재시도 정책 구현
3. 데이터 레벨
- 데이터베이스 클러스터링
- 캐시 분산 구성
- 데이터 복제 및 백업 전략
6.2 모니터링 및 알림 전략
@Configuration
public class MonitoringConfig {
@Bean
public MetricRegistry metricRegistry() {
MetricRegistry registry = new MetricRegistry();
// JVM 메트릭 등록
registry.register("jvm.memory", new MemoryUsageGaugeSet());
registry.register("jvm.gc", new GarbageCollectorMetricSet());
registry.register("jvm.threads", new ThreadStatesGaugeSet());
// 커스텀 메트릭 등록
registry.register("application.errors", new Meter());
registry.register("application.requests", new Timer());
return registry;
}
@Bean
public HealthCheckRegistry healthCheckRegistry() {
HealthCheckRegistry registry = new HealthCheckRegistry();
// 핵심 서비스 헬스체크 등록
registry.register("database", new DatabaseHealthCheck());
registry.register("cache", new CacheHealthCheck());
registry.register("messageQueue", new MessageQueueHealthCheck());
return registry;
}
}6.3 결론 및 느낀점
현대 클라우드 인프라는 단순한 시스템 운영을 넘어 지능적이고 자율적인 환경으로 진화하고 있습니다.
AI 기반 예측 분석을 통해 장애를 사전에 감지하고 대응할 수 있게 되었으며, 이는 서비스의 안정성과 신뢰성을 크게 향상시킬 것입니다.
서버리스 아키텍처로의 전환은 운영 부담을 크게 줄이면서도 효율적인 리소스 관리가 가능하게 합니다.
특히 자동 확장/축소 기능은 비용 최적화와 직결되어, 비즈니스의 경제성을 높이는데 큰 도움이 될 것입니다.
보안 측면에서는 제로 트러스트 아키텍처의 도입과 자동화된 보안 시스템 구축이 매우 시의적절합니다.
사이버 위협이 나날이 증가하는 상황에서, 선제적이고 체계적인 보안 체계 구축은 필수적입니다.
결론적으로, 이러한 방향성은 더욱 스마트하고, 효율적이며, 안전한 클라우드 환경을 구축하는데 초점을 맞추고 있습니다.
특히 자동화와 AI 기술의 적극적인 도입은 운영 효율성을 극대화하면서도 보안성을 강화할 수 있는 균형 잡힌 접근방식이라고 평가할 수 있습니다.
SPOF는 시스템 설계에서 가장 중요한 고려사항 중 하나이며, 지속적인 모니터링과 개선이 필요한 영역이라 생각됩니다.
