
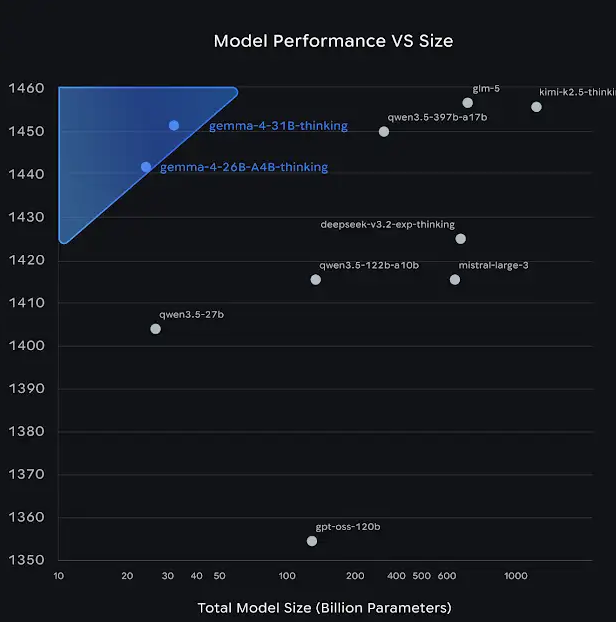
구글에서 새로운 모델 시리즈가 출시되었다는 소식을 듣고, 메일에 첨부된 벤치마크 그래프에 혹해서 직접 다운로드하여 테스트를 진행해 보았습니다.
우선 벤치마크 그래프 상으로는 31B나 27B 모델이 Qwen 3.5 300B 이상급 모델과 맞먹는 것처럼 묘사되어 있지만, 실제로는 그 정도 수준에 미치지 못합니다.
참고로 그래프 하단에 처박혀 있던 OSS 120B 모델은 여전히 현역으로 훌륭하게 동작하고 있습니다.
직접 모델들을 구동해보며 파악한 몇 가지 핵심 내용을 정리해 봅니다.
26B 모델 리뷰
이 모델은 MoE(Mixture of Experts) 아키텍처를 채택했습니다.
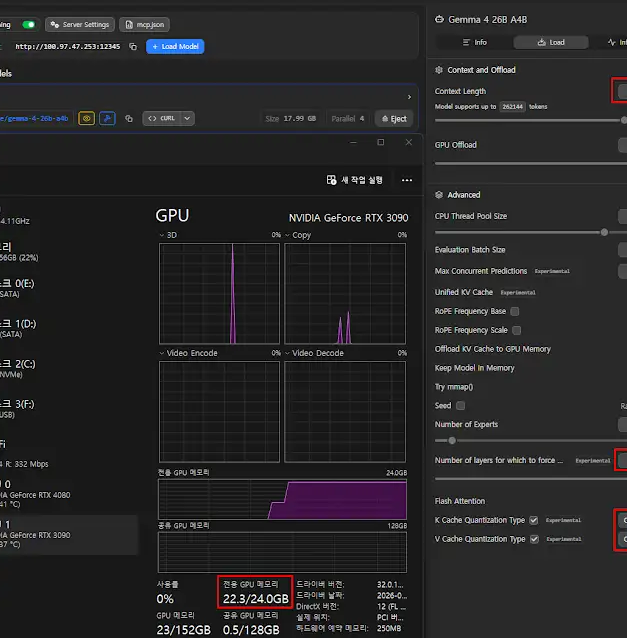
RTX 3090 기준으로 전문가 레이어의 CPU 오프로딩이 가능하며, 사실상 전부 오프로딩하더라도 속도 저하가 거의 발생하지 않습니다.
KV 캐시 양자화는 INT8 수준으로 설정해도 무리가 없으며, 이 설정을 통해 약 100K 정도의 컨텍스트를 안정적으로 확보할 수 있습니다.
LLM이 유의미하고 논리적인 추론 능력을 보여주려면 100K 정도의 컨텍스트 확보는 필수적입니다. 컨텍스트가 부족하면 모델이 임의로 질의를 축소 해석하려 들기 때문에 결과물의 품질 차이가 확연하게 벌어집니다.
모델의 고유 성향일 수도 있겠지만, 컨텍스트 크기에 따른 답변 퀄리티 편차가 상당히 커서 다소 당황스러웠습니다.
충분한 100K 컨텍스트를 제공하면 상당히 난이도 있는 문제에 대해서도 훌륭한 답변을 생성해 냅니다.
특히 Qwen 3.5 27B와 비교해 보면 전반적인 문제 해결 전략은 엇비슷하지만, 세부적인 디테일에서는 26B 모델이 더 우수하다는 인상을 받았습니다.
통상적으로 100B 이하 모델들이 디테일한 영역으로 들어갈수록 환각 현상이 심해지는 경향이 있는데, 이 모델은 그런 현상이 훨씬 덜합니다.
속도 측면에서도 앞서 언급한 세팅으로 초당 약 50토큰 이상의 고속 출력을 보여줍니다.
최적화를 거치고 컨텍스트를 약간 타협하면 초당 70토큰까지도 가능합니다.
속도와 출력 결과물 모두 훌륭하여 적극 추천할 만합니다.
31B 모델 리뷰
이 모델은 덴스 아키텍처이기 때문에 상황이 완전히 다릅니다.
오프로딩할 만한 가중치가 마땅치 않습니다.
Q4KM 양자화 기준으로 모델 크기만 19.9GB에 육박하며, KV 캐시를 로딩하기도 전에 이미 VRAM을 18GB 정도 차지합니다.
게다가 덴스 모델 특성상 모든 레이어에서 풀 KV 캐시가 발생하므로, 컨텍스트를 4K만 잡아도 3GB의 VRAM이 추가로 증발합니다.
즉, 아무런 추가 작업 없이 4K 컨텍스트만 설정해도 VRAM 20GB를 소모하게 됩니다.
결과적으로 KV 캐시를 GPU에 온전히 올릴 수 있는 마지노선은 KV INT8 양자화 기준으로 8K 컨텍스트가 한계입니다.
문제는 속도입니다.
위 세팅으로 구동해도 초당 10토큰조차 나오지 않을 정도로 느립니다.
비전 인코더의 오프로딩 이슈도 있고, 복잡한 연산 구조 탓에 VRAM에 모델이 수용되더라도 CPU와의 상호작용이 과도하게 발생하기 때문으로 보입니다.
어차피 느린 김에 KV 캐시 전체를 CPU로 오프로딩하고 컨텍스트를 최대로 끌어올려 테스트도 진행해 보았습니다.
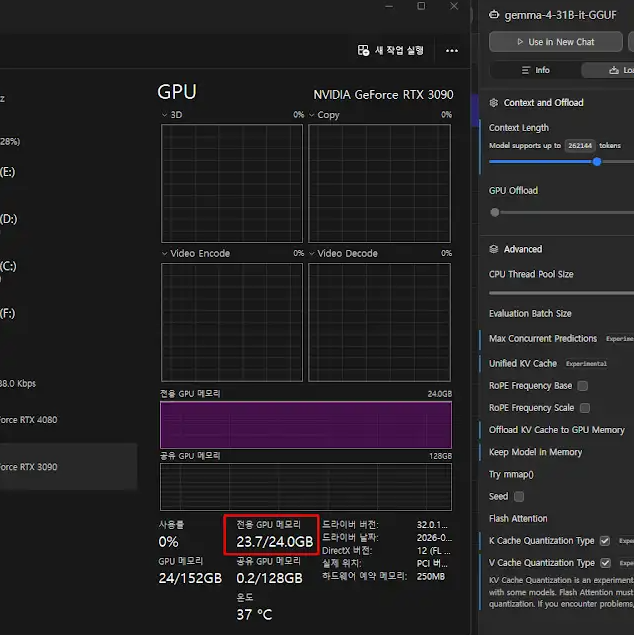
결과적으로 시스템 RAM을 약 120GB나 추가로 소모했고 262K 컨텍스트를 전부 활용할 수 있었지만, 출력 속도는 초당 6토큰 수준으로 처참했습니다.
이 정도 리소스를 소모할 바에는 차라리 Qwen 3.5 122B를 사용하는 것이 훨씬 합리적입니다.
결국 31B 모델에서 262K 컨텍스트를 제대로 활용하려면 120GB 이상의 시스템 메모리가 필수적입니다.
VRAM에 올리고 싶다면 기본 모델 사이즈 18GB 외에 추가로 120GB의 VRAM이 더 필요하며, 그게 아니라면 강제로 CPU 오프로딩을 해야만 합니다.
가장 중요한 성능을 Opus와 GPT를 활용해 교차 평가해 본 결과,
오히려 '26B (100K)가 31B 보다 압도적으로 우수하다'는 결론이 나왔습니다.
따라서 31B 모델은 강력히 비추천합니다.
Qwen 3.5 시리즈와의 비교 및 결론
Qwen 3.5 시리즈는 27B가 덴스 모델입니다. 그래서 하드웨어 자원이 제한적인 환경에서는 전문가 레이어를 오프로딩할 방법이 없어 애매해지고, 오히려 MoE인 35B 모델이 효율성 측면에서 훨씬 유리합니다.
그런데 이번 시리즈는 정확히 그 반대입니다. 26B가 스파스 모델이고, 31B가 덴스 모델입니다. 따라서 VRAM이 제한적인 환경에서는 무조건 26B를 선택해야 합니다.
사실 하드웨어가 넉넉하더라도 성능 면에서 26B가 더 낫습니다.
모델의 고유 성향도 확연히 차이가 나는데, 코딩이나 개발 관련 작업에서는 26B 모델의 성향이 훨씬 적합하게 느껴졌습니다.
절대적인 성능 수치만 놓고 보면 여전히 Qwen 3.5 35B가 우위에 있습니다.
하지만 RTX 3090 기준으로 Qwen 3.5 35B가 초당 25토큰 수준의 속도를 내는 반면, 이번 26B 모델은 초당 50토큰으로 무려 2배 빠른 출력 속도를 자랑합니다.
성능 격차가 체감될 정도로 크지 않으며, 오히려 세부적인 디테일 구현에서는 26B가 더 뛰어난 지점도 분명 존재합니다.
따라서 빠른 응답 속도가 요구되는 에이전트환경이나 스피디한 작업 전개가 필요한 상황에서는 26B 모델이 확실한 강점을 가집니다.
마치 전용 코딩 어시스턴트의 고속 모드를 사용하는 듯한 쾌적함을 경험할 수 있었습니다.
