1. GraphQL의 등장 배경 및 이론
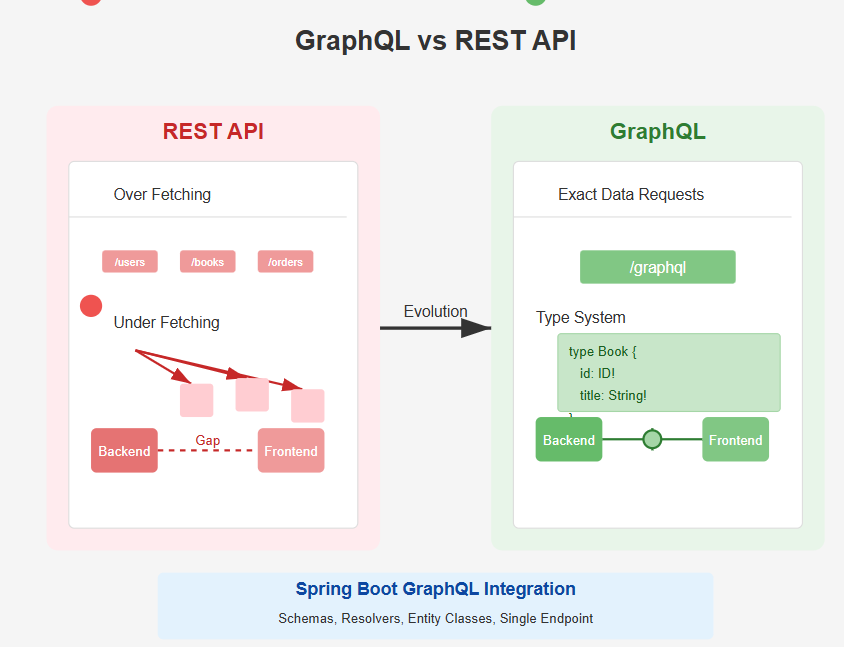
REST API의 한계
- 오버페칭 (Over Fetching): 클라이언트가 실제로 필요하지 않은 데이터까지 응답받는 문제 입니다
- 언더페칭 (Under Fetching): 필요한 데이터를 얻기 위해 여러 번 호출해야 하는 문제 입니다
- 복수의 엔드포인트 관리: 여러 리소스마다 엔드포인트가 달라 관리가 복잡합니다
- 프론트엔드와 백엔드 간의 간극: 클라이언트의 요구에 맞춰 데이터를 커스터마이징하기 어려습니다.
GraphQL의 등장 이유
- 정확한 데이터 요청과 전달: 클라이언트가 필요한 데이터만 쿼리해서 받아올 수 있습니다.
- 단일 엔드포인트 사용: 하나의 엔드포인트로 모든 데이터를 관리 합니다.
- 타입 시스템: 명확한 스키마 정의로 API 사용의 예측 가능성과 안정성을 높입니다.
- 효율적인 데이터 로딩 및 캐싱: 불필요한 데이터 전송을 줄여 성능 최적화 합니다.
- 초기 FQL과의 차이: 2012년 FQL이 소셜 데이터에 특화되었으나, 복잡성과 제한성이 있었습니다.
GraphQL은 이를 극복해 유연성을 보완 합니다.
2. GraphQL의 주요 특징
- 클라이언트 중심의 쿼리: 클라이언트가 원하는 데이터만 선택적으로 요청 합니다.
- 타입 시스템: 정해진 스키마에 따라 데이터 구조를 강제하여 안정성 및 자동완성 지원 합니다.
- 단일 엔드포인트: 모든 요청을 하나의 엔드포인트로 처리하여 API 관리가 용이 합니다.
- Over Fetching 및 Under Fetching 방지: 필요한 데이터만 정확히 요청할 수 있습니다.
- 다양한 오픈소스 생태계: Apollo Server/Client, Graphene, Spring for GraphQL 등
다양한 도구 지원 합니다
3. 스프링(Spring)에서 GraphQL 사용하기
스프링 부트와 함께 GraphQL을 사용하면 서버 사이드에서 GraphQL 스키마 작성과 리졸버를 쉽게 구현할 수 있습니다.
여기서 몇 가지 핵심 포인트와 예제 코드를 함께 설명할려고합니다.
3.1 의존성 추가 (Gradle/Maven)
Gradle 에서 추가할때
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-graphql'
implementation 'com.graphql-java:graphql-java-tools:11.1.0' // 버전은 필요에 맞게 조정
// 그 외 필요한 의존성 (예: Spring Web 등)
}
Maven 에서 추가할때
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-graphql</artifactId>
</dependency>
<dependency>
<groupId>com.graphql-java</groupId>
<artifactId>graphql-java-tools</artifactId>
<version>11.1.0</version>
</dependency>
<!-- 그 외 필요한 의존성 -->
</dependencies>3.2 스키마 파일 작성
src/main/resources 폴더에 schema.graphqls 파일을 생성하고, 다음과 같이 타입과 쿼리를 정의합니다.
type Query {
books: [Book]
}
type Book {
id: ID!
title: String!
author: String!
}
- Query 타입: 클라이언트가 요청할 수 있는 데이터 집합을 정의 합니다.
- Book 타입: 책에 대한 정보로, ID, 제목, 저자를 포함 합니다.
3.3 엔티티 클래스 작성
GraphQL에서 사용할 데이터를 담을 간단한 엔티티 클래스를 만듭니다.
package com.example.graphql.model;
public class Book {
private String id;
private String title;
private String author;
// 생성자, getter, setter
public Book(String id, String title, String author) {
this.id = id;
this.title = title;
this.author = author;
}
// getter & setter 생략 가능(롬복 사용해도 좋음)
public String getId() {
return id;
}
public String getTitle() {
return title;
}
public String getAuthor() {
return author;
}
}3.4 Query Resolver 작성
GraphQL 쿼리를 처리할 리졸버를 생성합니다.
GraphQLQueryResolver를 구현하면 간단하게 사용할 수 있습니다.
package com.example.graphql.resolver;
import com.coxautodev.graphql.tools.GraphQLQueryResolver;
import com.example.graphql.model.Book;
import org.springframework.stereotype.Component;
import java.util.Arrays;
import java.util.List;
@Component
public class BookQueryResolver implements GraphQLQueryResolver {
public List<Book> books() {
return Arrays.asList(
new Book("1", "GraphQL for Beginners", "Author A"),
new Book("2", "Spring Boot and GraphQL", "Author B")
);
}
}
3.5 스프링 부트 메인 클래스
스프링 부트 애플리케이션을 실행하기 위한 메인 클래스를 작성 합니다.
package com.example.graphql;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class GraphqlApplication {
public static void main(String[] args) {
SpringApplication.run(GraphqlApplication.class, args);
}
}
이제 애플리케이션을 실행하면 GraphQL Playground 또는 Apollo Studio 같은 툴을 통해
http://localhost:8080/graphql 엔드포인트로 쿼리를 보내 테스트할 수 있습니다.
4. 개선 및 보완할 부분
보안 강화
- 입력 데이터 검증: GraphQL의 유연함이 보안 취약점으로 이어질 수 있으므로,
각 쿼리 및 변수를 철저하게 검증해야 합니다. - 보안 헤더 설정: CORS, CSRF 보호 등 웹 보안 헤더를 사용해 외부 공격에 대비합니다.
- 정기적인 보안 검사 및 모니터링: 로깅 및 모니터링 시스템을 구축해 의심스러운 활동을 미리 탐지합니다.
에러 핸들링
- 에러 메시지를 명확하게 전달하되, 내부 정보가 노출되지 않도록 주의 합니다.
- 사용자에게 친절한 에러 메시지를 제공하고, 로깅을 통해 문제를 추적 합니다.
성능 최적화
- 데이터 로딩 최적화: N+1 문제를 방지하기 위해 DataLoader를 활용 합니다.
- 캐싱 전략: 자주 요청되는 데이터는 캐싱을 통해 성능을 개선 합니다.
- 스키마 설계: 불필요한 필드나 복잡한 관계를 단순화해 쿼리 효율성을 높입니다.
테스트 및 모니터링
- Apollo Studio, GraphQL Playground 등 다양한 도구로 쿼리 성능과 모니터링을 실시 합니다.
- 통합 테스트 및 단위 테스트를 통해 API의 안정성을 검증 합니다.
5. 결론
GraphQL은 REST API의 한계를 극복하고, 클라이언트가 원하는 데이터를 정확하게 요청할 수 있도록
해주는 강력한 API 기술이입니다.
특히 스프링과 연동 시, 위에서 설명한 의존성 추가, 스키마 파일 작성, 리졸버 및 엔티티 클래스를
통해 쉽게 구현할 수 있습니다.
보안, 성능, 모니터링 측면에서 추가 개선 사항을 반영하면, 실제 서비스 환경에서도 안정적이고 효율적인 API를 운영할 수 있을 겁니다.
느낀점
1. REST API의 한계를 확실히 체감했다
- 기존 REST API에서는 오버페칭(Over-fetching), 언더페칭(Under-fetching) 문제가 많았습니다.
- 특히 프론트엔드에서 데이터를 최적화해 불러오기가 어려웠고, 불필요한 요청이 많아
API 응답 속도가 느려지는 문제 발생 합니다.
2. GraphQL의 강점: 클라이언트 중심의 데이터 요청
- 필요한 데이터만 가져올 수 있어 네트워크 비용이 절감 됩니다.
- 단일 엔드포인트(POST /graphql)로 모든 요청을 처리할 수 있어서 API 관리가 쉬워집니다.
3. Spring for GraphQL을 적용하며 배운 점
-
기존 @RestController 방식이 아니라 @Controller + @QueryMapping, @MutationMapping을
사용해 요청을 처리 합니다. -
GraphQL 스키마를 통해 타입을 정의하니 API 문서 없이도 직관적인 데이터 구조를 설계할 수 있습니다.
4. 샘플코드
@Component
public class BookQueryResolver {
private final BookService bookService;
public BookQueryResolver(BookService bookService) {
this.bookService = bookService;
}
@QueryMapping
public Book getBook(@Argument Long id) {
return bookService.findById(id);
}
}
- @QueryMapping을 통해 클라이언트가 원하는 데이터를 요청할 수 있도록 합니다.
- REST API처럼 여러 엔드포인트를 만들지 않아도 되고, 쿼리로 필요한 데이터만 선택 가능 합니다.
5. GraphQL 도입 시 고려해야 할 점
- 캐싱 전략이 REST와 다름 → 데이터 로딩 최적화를 위한 DataLoader 사용 필요합니다.
- 인증/인가(Authorization) 방식도 다르게 접근해야 합니다.
