
PostgreSQL pgvector 환경에서 한국어 BM25 검색 구축하기
Retrieval-Augmented Generation나 하이브리드 검색을 구현할 때, 단순 벡터 검색 외에 BM25 기반의 키워드 검색이 병행되어야 정확도가 올라갑니다.
하지만 PostgreSQL 기본 이미지에는 한국어 형태소 분석 기능이 없습니다.
본 포스팅에서는 pgvector 이미지를 베이스로 mecab-ko 엔진과 textsearch_ko 확장을 포함한 커스텀 Docker 이미지를 빌드하고, 발생 가능한 트러블슈팅 사례를 정리하였습니다.
1. Dockerfile 상세 설계
빌드 과정에서 흔히 발생하는 네트워크 및 의존성 문제를 해결하기 위해 다음과 같이 Dockerfile.pgvector를 구성했습니다.
1.1 주요 빌드 전략
-
미러 서버 변경: 기본 Debian 미러에서 발생하는
400 Bad Request를 방지하기 위해 한국 미러(ftp.kr.debian.org)를 우선 사용합니다. -
CA 인증서 포함:
ca-certificates를 명시적으로 설치하여 HTTPS 통신시의 인증 오류를 차단합니다. -
Mecab-ko 사전 경로 최적화: 빌드 후
mecabrc를 직접 수정하여 사전 경로 인식을 자동화했습니다.
1.2 Dockerfile.pgvector
FROM pgvector/pgvector:pg17
# 1. 필수 빌드 도구 설치 및 미러 서버 최적화
RUN set -e; \
for f in /etc/apt/sources.list /etc/apt/sources.list.d/*.list; do \
[ -f "$f" ] && sed -i 's|http://deb\.debian\.org|http://ftp.kr.debian.org|g' "$f" 2>/dev/null || true; \
done; \
apt-get update && apt-get install -y --no-install-recommends \
ca-certificates curl make g++ patch git \
automake autoconf libtool \
postgresql-server-dev-17 \
&& rm -rf /var/lib/apt/lists/*
# 2. mecab-ko 엔진 설치
RUN curl -LO https://bitbucket.org/eunjeon/mecab-ko/downloads/mecab-0.996-ko-0.9.2.tar.gz \
&& tar zxf mecab-0.996-ko-0.9.2.tar.gz \
&& cd mecab-0.996-ko-0.9.2 \
&& ./configure && make && make install \
&& ldconfig
# 3. mecab-ko-dic 사전 설치 및 경로 설정
RUN curl -LO https://bitbucket.org/eunjeon/mecab-ko-dic/downloads/mecab-ko-dic-2.1.1-20180720.tar.gz \
&& tar zxf mecab-ko-dic-2.1.1-20180720.tar.gz \
&& cd mecab-ko-dic-2.1.1-20180720 \
&& ./autogen.sh && ./configure && make && make install \
&& echo "dicdir = /usr/local/lib/mecab/dic/mecab-ko-dic" > /usr/local/etc/mecabrc
# 4. textsearch_ko(한국어 형태소 분석 확장) 빌드
RUN git clone --depth 1 https://github.com/i0seph/textsearch_ko.git \
&& cd textsearch_ko \
&& make USE_PGXS=1 \
&& make USE_PGXS=1 install \
&& cd .. && rm -rf textsearch_ko
2. 실행 및 연동 가이드
2.1 Docker Compose 설정
로컬 환경의 5432 포트 충돌을 방지하고 데이터 영속성을 보장합니다.
services:
pgvector:
build:
context: .
dockerfile: Dockerfile.pgvector
container_name: pgvector
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
POSTGRES_DB: postgres
ports:
- "127.0.0.1:5433:5432"
volumes:
- pgvector_data:/var/lib/postgresql/data
volumes:
pgvector_data:
2.2 pgAdmin 접속 이슈 해결 (Connection Refused)
개선전
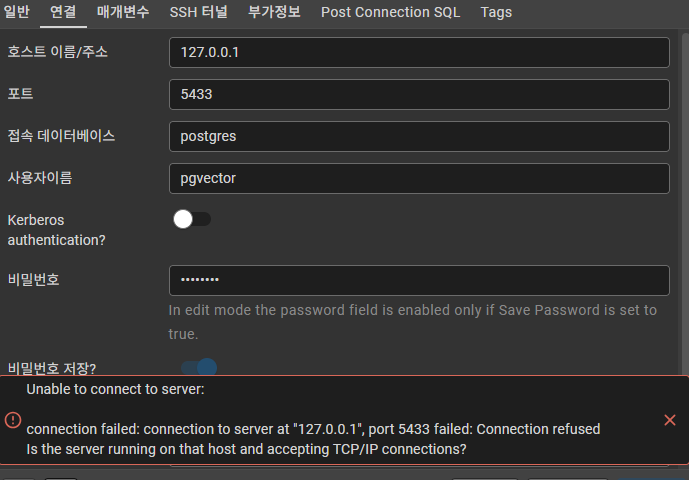
많은 분이 겪는 "pgAdmin 컨테이너 환경에서의 접속 실패" 현상은 네트워크 가상화 차이 때문입니다.
- 현상: Host를
127.0.0.1로 설정 시 접속 불가. - 원인: pgAdmin 컨테이너 내부의
127.0.0.1은 DB 컨테이너가 아닌 자기 자신을 가리킴. - 해결: Host 주소를
host.docker.internal로 변경하여 호스트 머신을 경유하도록 설정합니다. (포트는 5433 유지)
3. 동작 확인
컨테이너가 정상 구동되면 아래 명령어로 확장이 활성화되었는지 확인하십시오.
# 확장 모듈 활성화 SQL
docker exec pgvector psql -U postgres -c "
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS textsearch_ko;
SELECT extname, extversion FROM pg_extension WHERE extname IN ('vector','textsearch_ko');
"
4.한국어 전문 검색 적용
textsearch_ko 확장이 설치되었다면, 이제 이를 활용해 한국어 형태소 분석 기반의 검색 시스템을 구축할 수 있습니다.
4-1. 테스트용 테이블 생성
검색 대상이 될 제목(title)과 본문(content)을 포함한 간단한 게시판 테이블을 만듭니다.
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
content TEXT,
-- 검색 속도 최적화를 위한 텍스트 벡터 컬럼 추가
tsv_content tsvector
);
4-2. GIN 인덱스 생성
한국어 형태소 분석기를 사용하여 검색 전용 인덱스인 Generalized Inverted Index을 생성합니다.
-- 1. 본문 내용을 기반으로 GIN 인덱스 생성
CREATE INDEX idx_documents_content_fts ON documents USING GIN (to_tsvector('korean', content));
-- 2. (권장) 성능 향상을 위해 미리 계산된 컬럼(tsv_content)에 인덱스 생성
CREATE INDEX idx_documents_tsv ON documents USING GIN (tsv_content);
4-3. 실무형 검색 쿼리 작성
단순히 "포함 여부"만 체크하는 것이 아니라, 검색어와의 연관성에 따라 정렬하여 상위 결과를 가져오는 쿼리입니다.
-- '데이터베이스'라는 키워드로 검색하고 관련성 높은 순으로 정렬
SELECT
title,
ts_rank(to_tsvector('korean', content), query) AS rank
FROM
documents,
to_tsquery('korean', '데이터베이스') query
WHERE
to_tsvector('korean', content) @@ query
ORDER BY
rank DESC;
4-4. 트리거를 통한 자동 색인
매번 INSERT나 UPDATE를 할 때마다 tsvector를 수동으로 갱신하는 것은 비효율적입니다. DB 레벨에서 트리거를 설정해두면 관리 포인트가 줄어듭니다.
-- 데이터가 삽입/수정될 때마다 tsv_content 컬럼을 자동으로 업데이트하는 함수/트리거
CREATE FUNCTION documents_trigger() RETURNS trigger AS $$
begin
new.tsv_content := to_tsvector('korean', coalesce(new.title,'') || ' ' || coalesce(new.content,''));
return new;
end
$$ LANGUAGE plpgsql;
CREATE TRIGGER tsvectorupdate BEFORE INSERT OR UPDATE
ON documents FOR EACH ROW EXECUTE FUNCTION documents_trigger();
4-5. 형태소 분석 결과 확인
원하는 대로 단어가 잘리고 있는지 궁금하다면 ts_debug 함수를 활용 하면됩니다.
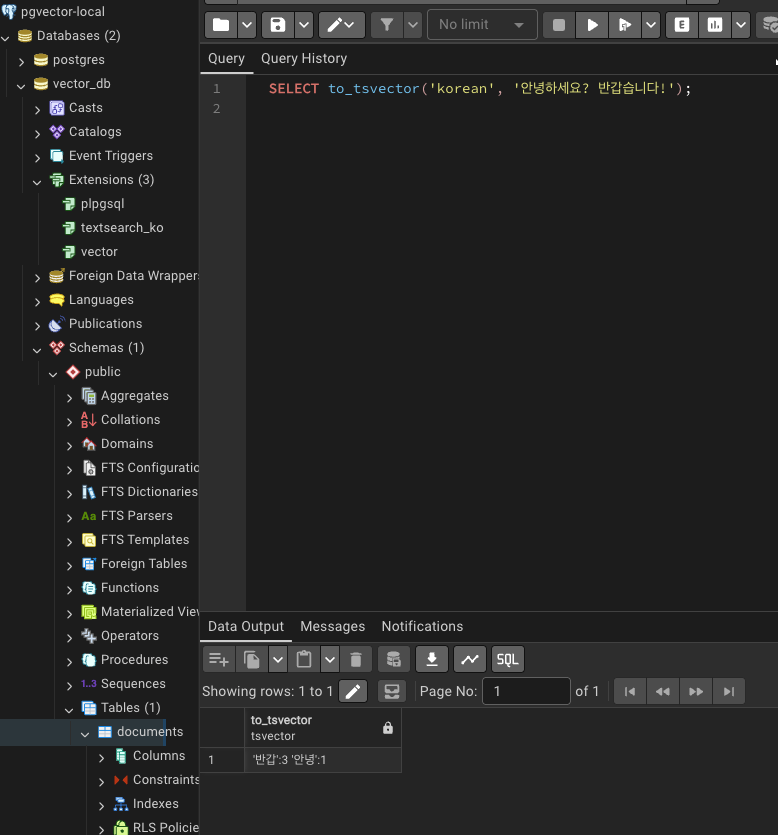
SELECT * FROM ts_debug('korean', '형태소 분석이 잘 되는지 확인합니다.');
4-6. 하이브리드 검색으로의 확장
현재 구성된 BM25(키워드 검색)와 이전에 설치한 pgvector(벡터 검색)를 결합하여 Reciprocal Rank Fusion(RRF) 알고리즘 등을 적용하면, 훨씬 더 강력한 RAG 시스템을 구축할 수 있습니다.
단순히 검색 결과에 포함되는 것을 넘어, "사용자가 의도한 결과가 최상단에 오게 하는 법"에 대한 기술적 해결책입니다.
5. 필드별 가중치 부여
검색어가 '제목'에 포함된 문서가 '본문'에 포함된 문서보다 더 중요할 가능성이 높습니다. PostgreSQL은 A, B, C, D 네 단계의 가중치를 정의했습니다.
- A: 제목 (가장 높음)
- B: 요약/키워드
- C: 본문
- D: 기타 주석
-- 제목(A)과 본문(B)에 차등 가중치를 부여하여 tsvector 생성
-- (coalesce는 NULL 값을 빈 문자열로 처리하기 위함)
UPDATE documents
SET tsv_content =
setweight(to_tsvector('korean', coalesce(title, '')), 'A') ||
setweight(to_tsvector('korean', coalesce(content, '')), 'B');
이렇게 설정된 가중치는 ts_rank 계산 시 자동으로 반영되어, 제목에 키워드가 있는 문서가 검색 결과 상단에 배치됩니다.
6. Reciprocal Rank Fusion를 활용한 하이브리드 검색
가장 트렌디한 방식입니다.
벡터 검색의 의미론적 결과와 textsearch_ko의 키워드 결과 점수를 합산하여 최종 순위를 결정합니다.
-- RRF 하이브리드 검색 예시 (Pseudo-code 기반)
WITH vector_search AS (
-- 1. 벡터 검색 결과 (상위 50개)
SELECT id, row_number() OVER (ORDER BY embedding <=> '[0.1, 0.2, ...]') as rank
FROM documents
ORDER BY embedding <=> '[0.1, 0.2, ...]' LIMIT 50
),
keyword_search AS (
-- 2. BM25 키워드 검색 결과 (상위 50개)
SELECT id, row_number() OVER (ORDER BY ts_rank(tsv_content, to_tsquery('korean', '검색어')) DESC) as rank
FROM documents
WHERE tsv_content @@ to_tsquery('korean', '검색어')
ORDER BY rank LIMIT 50
)
-- 3. 두 결과의 순위를 역수로 합산 (RRF)
SELECT
COALESCE(v.id, k.id) AS id,
(COALESCE(1.0 / (60 + v.rank), 0) + COALESCE(1.0 / (60 + k.rank), 0)) AS rrf_score
FROM vector_search v
FULL OUTER JOIN keyword_search k ON v.id = k.id
ORDER BY rrf_score DESC;
RRF의 분모에 들어가는 상수
60은 낮은 순위의 결과가 전체 점수를 왜곡하는 것을 방지하는 완충 역할을 합니다.
실제 서비스 데이터에 맞춰 조정하며 최적의 값을 찾는 과정이 필요합니다.
EXPLAIN ANALYZE로 성능 검증하기
이론적으로 완벽한 쿼리도 데이터가 쌓이면 느려질 수 있습니다.
PostgreSQL의 실행 계획을 분석하여 병목 지점을 찾는 방법입니다.
1. 인덱스 스캔 확인하기
우리가 만든 GIN 인덱스가 제대로 작동하는지 확인하려면 쿼리 앞에 EXPLAIN ANALYZE를 붙여 실행합니다.
EXPLAIN ANALYZE
SELECT title
FROM documents
WHERE tsv_content @@ to_tsquery('korean', '데이터베이스');
체크 포인트:
- Index Scan : 정상입니다. 인덱스를 사용하여 빠르게 찾고 있다는 뜻입니다.
- Seq Scan : 주의가 필요합니다.
인덱스를 무시하고 테이블 전체를 처음부터 끝까지 읽고 있다는 뜻이며, 데이터가 많아지면 장애의 원인이 됩니다.
2. 하이브리드 검색의 실행 비용 분석
RRF 쿼리는 공통 테이블 표현식을 사용하므로 각 단계별 소요 시간을 확인하는 것이 중요합니다.
EXPLAIN (ANALYZE, BUFFERS)
WITH vector_search AS (...) -- 생략
SELECT ...
- Execution Time: 실제 쿼리 실행에 걸린 총 시간입니다.
- Buffers: 디스크가 아닌 메모리에서 데이터를 얼마나 가져왔는지 보여줍니다.
이 수치가 높을수록 캐시가 잘 작동하고 있다는 의미입니다.
마무리하며
단순히 "기능이 돌아가게 만드는 것"과 "시행착오 없이 쓸 수 있는 환경을 만드는 것"의 차이를 다시 한번 체감했습니다.
처음에는 textsearch_ko 확장을 설치하는 단순한 빌드 과정이라 생각했지만, 실제 환경에서는 네트워크 미러 서버의 불안정성이나 Docker 컨테이너 간의 네트워크 루프백(127.0.0.1 이슈) 같은 실무적인 복병들이 많았습니다.
이러한 디테일한 기록이 모여 블로그의 수준을 높이고, 시간을 아껴줄 수 있다고 믿습니다.
특히 벡터 검색과 전통적인 키워드 검색의 결합은 현대 검색 아키텍처의 핵심인 만큼, 서비스의 검색 품질을 한 단계 끌어올리는 밑거름이 되었으면 합니다.
