
크롤링에서의 베스트 프랙티스
최근에 RestTemplate에 대해 배운 점이 있어서 포스팅으로 작성하게 되었습니다.
저는 평상시에 크롤링을 할 때 RestTemplate을 사용하곤 했는데요.
타임아웃에 대해 인지하지 못하고 있었습니다.
상황에 따라 다를 순 있겠지만, 타임아웃 설정에 따라서 문제가 생길 수 있는 부분이 있습니다.
이 부분에 대해서 글로 다뤄보도록 할려고 합니다.
목차
- 예시 설명
- RestTemplate에 Timeout을 적용하지 않은 경우 시나리오와 문제점
- RestTemplate에 Timeout 설정하기
- RestTemplate을 캐싱과 함께 사용할 때 했던 고민과 해결방법 (캐싱에 더 가까운 고민)
1. 예시 설명
예제에서 사용되는 코드 이해를 위해 간단하게 예시부터 설명드리도록 하겠습니다.
먼저 스케일아웃 되지 않은 단일 서버이고, Java + Spring Framework로 작성된 코드입니다.
그리고 캐싱같은 경우는 단일 서버이므로 글로벌 캐시가 필요 없어서
자바에서 제공되는 ConcurrentHashMap 자료구조를 이용해서 캐싱을 만들었습니다.
데이터베이스는 MySQL을 사용했습니다.
예시에 나오는 코드의 플로우는 다음과 같습니다.
클라이언트는 서버로부터 음식 정보를 크롤링합니다.
중복 크롤링을 막기 위해 캐싱에 데이터가 존재한다면 아무 행위를 하지 않습니다.
캐싱에 데이터가 없다면 첫 요청이라 간주하고 Rest Template을 이용한 크롤링을 시작합니다.
크롤링을 마쳤다면 DB에 데이터를 삽입하고, 캐싱에도 삽입해줍니다.
2. RestTemplate에 Timeout을 적용하지 않은 경우 시나리오와 문제점
위에 예시대로 크롤링을 하기 위해 다음과 같은 크롤링 구현체와 함께 Service 코드를 작성해주었습니다.
package com.ex.food.application;
import com.ex.food.domain.Food;
import com.ex.food.domain.FoodRepository;
import com.ex.food.domain.Foods;
import com.ex.food.domain.cache.FoodCache;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
@RequiredArgsConstructor
@Service
public class FoodManagementService {
private final FoodDataFetcher foodDataFetcher;
private final FoodRepository foodRepo;
@Transactional
public void updateFoodCache(final Long memberId) {
if (!FoodCache.isCachedForMember(memberId)) {
List<Food> foods = foodDataFetcher.fetchFoodData(memberId);
Foods foodCollection = new Foods(foodRepo.saveAll(foods));
FoodCache.cacheFoodData(memberId, foodCollection);
}
}
}
import com.ex.food.application.FoodFetcher;
import com.ex.food.application.dto.FoodListResponse;
import com.ex.food.domain.Food;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.http.HttpEntity;
import org.springframework.http.HttpHeaders;
import org.springframework.http.HttpMethod;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.stereotype.Component;
import org.springframework.web.client.RestTemplate;
import org.springframework.web.util.UriComponentsBuilder;
import java.net.URI;
import java.util.List;
@Slf4j
@RequiredArgsConstructor
@Component
public class FoodFetcherImpl implements FoodFetcher {
private static final String BASE_URL = "https://example.com";
private final RestTemplate restTemplate;
@Override
public List<Food> fetchFoods(final Long memberId) {
try {
return getFoodList(memberId).getFoods();
} catch (final Exception e) {
log.error("Failed to fetch food data", e);
throw new RuntimeException("Error fetching food data: " + e.getMessage(), e);
}
}
private FoodListResponse getFoodList(final Long memberId) {
URI uri = buildRequestUri();
HttpHeaders headers = createHttpHeaders();
ResponseEntity<FoodListResponse> response = restTemplate.exchange(
uri, HttpMethod.POST,
new HttpEntity<>(memberId, headers),
FoodListResponse.class
);
return response.getBody();
}
private URI buildRequestUri() {
return UriComponentsBuilder.fromUriString(BASE_URL)
.build()
.toUri();
}
private HttpHeaders createHttpHeaders() {
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
return headers;
}
}
package com.ex.food.application;
import com.ex.food.domain.Food;
import com.ex.food.domain.FoodRepository;
import com.ex.food.domain.FoodCollection;
import com.ex.food.domain.cache.FoodCache;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
@RequiredArgsConstructor
@Service
public class FoodManagementService {
private final FoodFetcher foodFetcher;
private final FoodRepository foodRepo;
@Transactional
public void refreshFoodCache(final Long memberId) {
if (!FoodCache.isCachedForMember(memberId)) {
List<Food> retrievedFoods = foodFetcher.fetchFoods(memberId);
FoodCollection foodCollection = new FoodCollection(foodRepo.saveAll(retrievedFoods));
FoodCache.updateCache(memberId, foodCollection);
}
}
}
데이터베이스에 저장하기 위해 @Transactional 어노테이션이 붙어있음을 주의해주세요.
예시대로 코드는 캐싱 데이터가 없다면 크롤링을 시도하고, 데이터베이스에 저장하게 됩니다.
여기서 우리가 RestTemplate에 Timeout 설정을 따로 해주지 않게 된다면 어떤 일이 일어날까요?
먼저 크롤링을 하는 RestTemplate에 응답 시간이 지연된다면, Transactional 어노테이션이 붙은 메서드는 크롤링이 지연된 시간만큼 MySQL 커넥션을 물고있게 됩니다.
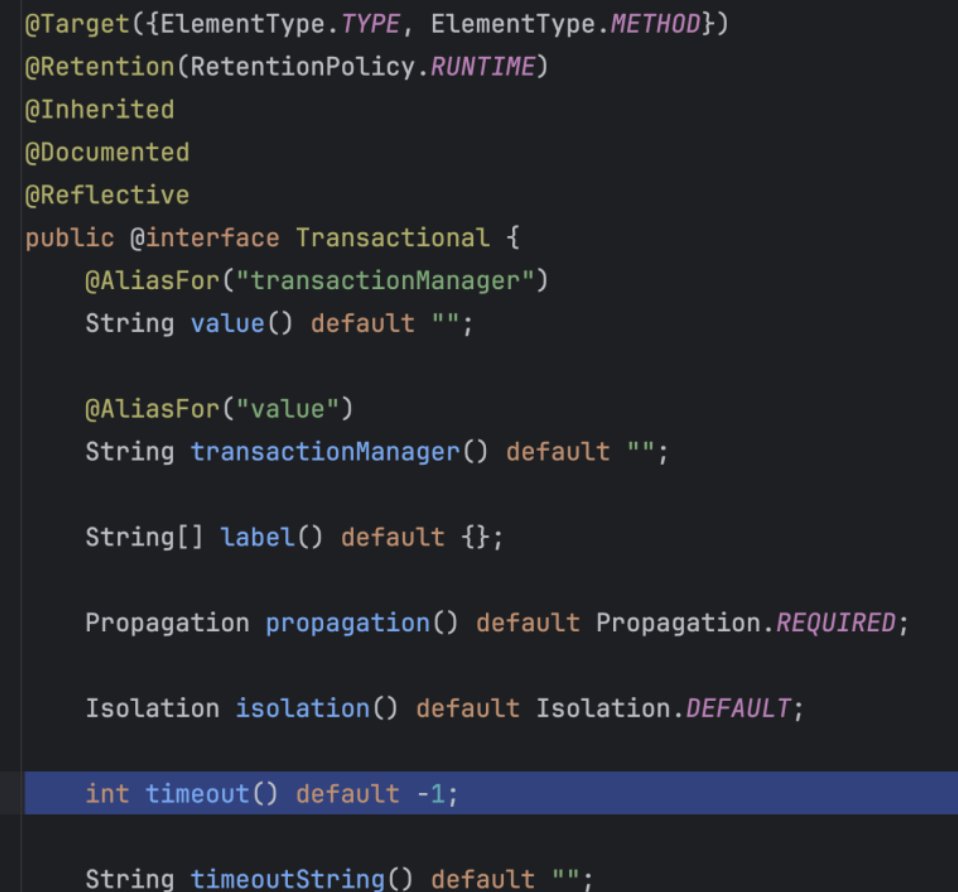
Transactional 어노테이션은 위에 이미지처럼 timeout 기본 값은 -1이고, 설정하지 않았다면 무한정 트랜잭션이 길어질 수 있음을 의미합니다.
결국 이 Transactional이 붙은 메서드 범위에서 RestTemplate의 응답 시간이 길어진다면 트랜잭션의 길이도 길어질 수 있다는 뜻입니다.
트랜잭션이 길어진다면 상황에 따라 여러 문제가 생길 수 있는데 데드락이 생긴다거나, DB 커넥션 부족으로 이어질 수 있습니다.
피크 타임에 무수히 많은 사용자가 크롤링 API를 사용하는데, 크롤링하는 서버에 문제가 생겨 응답이 엄청나게 길어진다면 요청마다 트랜잭션이 끝나지 않아 MySQL 커넥션을 계속 가지고 있게 되고 이는 결국 성능에 문제가 생길 수 있다는 것을 의미합니다.
이런 문제를 해결하기 위해서 RestTemplate에 우리는 timeout 설정을 해줘야합니다.
(혹은 @Transactional 어노테이션의 timeout을 설정해줘도 되는데 개인적으로는 메서드 범위에 붙은 트랜잭션 설정 보다는 사용부인 RestTemplate의 설정을 건드는 것이 크롤링에 대한 타임아웃 설정이라 생각해서 이는 생략하도록 하겠습니다.)
3. RestTemplate에 Timeout 설정하기
RestTemplate에 Timeout을 설정하는 건 간단합니다.
저는 Bean으로 등록해서 사용하는 걸 선호하기 때문에 아래와 같이 설정을 해주었습니다.
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestTemplate;
import org.springframework.boot.web.client.RestTemplateBuilder;
import org.springframework.http.converter.StringHttpMessageConverter;
import java.nio.charset.StandardCharsets;
import java.time.Duration;
@Configuration
public class RestTemplateConfiguration {
private static final int CONNECTION_TIMEOUT_SECONDS = 10;
private static final int READ_TIMEOUT_SECONDS = 10;
@Bean
public RestTemplate createRestTemplate(final RestTemplateBuilder restTemplateBuilder) {
return restTemplateBuilder
.setConnectTimeout(Duration.ofSeconds(CONNECTION_TIMEOUT_SECONDS))
.setReadTimeout(Duration.ofSeconds(READ_TIMEOUT_SECONDS))
.messageConverters(new StringHttpMessageConverter(StandardCharsets.UTF_8))
.build();
}
}
위에 코드에서 타임아웃 설정을 상황에 맞게 설정하시고, 크롤링 상황에 맞춰 RestTemplateBuilder에 추가적인 체이닝을 걸어주시면 됩니다.
이렇게 설정을 한다면 위에 코드에서 크롤링 서버가 문제가 생기더라도 타임아웃 이후에 롤백이 발생할 것을 예상할 수 있게 됩니다.
- RestTemplate을 캐싱과 함께 사용할 때 했던 고민과 해결방법
(이 부분은 개인적인 생각을 담고 있는 부분이라 생략하셔도 됩니다!)
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
@RequiredArgsConstructor
@Service
public class FoodCacheService {
private final FoodDataFetcher foodDataFetcher;
private final FoodRepository foodRepository;
@Transactional
public void updateFoodCache(final Long memberId) {
if (!FoodCache.isCachedForMember(memberId)) {
List<Food> foodsToCache = foodDataFetcher.fetchFoods(memberId);
FoodCollection foodCollection = new FoodCollection(foodRepository.saveAll(foodsToCache));
FoodCache.updateCache(memberId, foodCollection);
}
}
}
아까와 같은 코드입니다.
고민1. 비동기 처리와 캐싱을 통한 중복 요청 제거와 캐싱 사이즈
저는 사용자가 스크랩 시간을 기다릴 필요가 없다고 생각해서 보통 이런 메서드는 쓰레드풀 설정과 함께 비동기로 처리합니다.
즉 타 클래스에서 FoodService.scrapFoods(...)를 비동기 호출하게 되는데요.
만약 별 다른 설정을 해주지 않으면 클라이언트가 크롤링 API를 계속 요청한다면 크롤링이 중복적으로 진행되고 이는 데이터베이스에 중복된 데이터도 쌓일 수 있게 됩니다.
이를 따닥이라고도 많이 부르는데 저는 이를 해결하기 위해선 캐싱을 생각했습니다.
스케일아웃되지 않은 단일 환경이므로 자바의 ConcurrentHashMap 자료구조를 활용했고, 사용부에선 크롤링 비동기 요청 전 캐시에 요청한 정보를 담습니다. (key: memberId / value: ...)
(* 만약 조금 더 섬세하게 다루고 싶다면 시간과 데이터 등등
여러 조합을 통해 멱등키를 만들어도 좋을 것 같습니다.)
이를 통해 중복 요청은 처리할 수 있습니다.
여기서 캐싱을 사용해서 생길 수 있는 문제도 있는데요.
1.캐싱 데이터가 많이 쌓일 수 있다. (메모리 과사용)
2.캐싱이 된 후 크롤링을 하는데 크롤링이 실패한다면 사용자는 캐싱을 비워주기 전까지 크롤링을 하지 못한다.
3.스케일 아웃 후 글로벌 캐싱이 다운된다면 DB로 급격한 조회 요청이 들어온다.
(이는 크롤링 외에 다른 API에서 조회하는 경우)
1번인 '캐싱 데이터가 많이 쌓일 수 있다. (메모리 과사용)' 문제는 다음과 같이 해결할 수 있습니다.
현재 캐싱에 사용되는 ConcurrentHashMap 자료구조 캐싱에서 일정 시간 주기로 초기화를 해준다.
모든 데이터를 제거하면 캐싱 스탬피드 문제 발생 우려가 된다.
일정 데이터 이상 캐싱이 되었다면, 신규 데이터 추가시마다 오래된 데이터를 제거하고 신규 데이터를 추가한다.
2번인 '캐싱이 된 후 크롤링을 하는데 크롤링이 실패한다면 사용자는 캐싱을 비워주기 전까지 크롤링을 하지 못한다.' 문제는 다음과 같이 해결할 수 있습니다.
크롤링한 데이터를 담는 캐싱 외에도 중복 크롤링을 방지하기 위한 캐싱을 분리한다.
크롤링 요청시 캐싱이 되고, 크롤링 완료시 캐싱이 제거되는 구조이다.
TTL을 직접 구현해서 <일정 시간> 이 지나도 완료되지 않은 캐싱 데이터를 초기화 한다.
3번인 '스케일아웃 후 Redis 글로벌 캐싱이 다운된다면 DB로 급격한 조회 요청이 들어온다.'
(이는 크롤링 외에 다른 API에서 조회하는 경우)
캐시 스탬피드 현상은 캐시 MISS로 인해 DB에 요청이 들어오는 현상인데, 이를 해결하기 위해선 복제 혹은 페일오버를 적용 하여 해당 현상에 대비한다.
위 예제 같은 경우는 이정도로도 충분히 예방할 수 있을 것 같습니다.
3번인 '스케일아웃 후 Redis 글로벌 캐싱이 다운된다면 DB로 급격한 조회 요청이 들어온다.' (이는 크롤링 외에 다른 API에서 조회하는 경우)
캐시 스탬피드 현상은 캐시 MISS로 인해 DB에 요청이 들어오는 현상인데, 이를 해결하기 위해선 복제 혹은 페일오버를 적용 하여 해당 현상에 대비한다.
위 예제 같은 경우는 이정도로도 충분히 예방할 수 있을 것 같습니다.
이렇게 RestTemplate과 캐싱을 사용하면서 겪은 문제, 고민한 점에 대해서 작성해봤습니다.
생각보다 하나에서 시작한 문제가 여러 문제들로 파생될 수 있기 때문에 신중하고 많은 고민 후에 기술을 도입하고 예방책을 미리 공부해둬야 된다고 많이 느꼈습니다.
참고 자료
Setting a Request Timeout for a Spring REST API
캐시 문제 해결 가이드 - DB 과부하 방지 실전 팁
혹시나 잘못된 부분이 있다면 피드백 부탁드립니다!
