VRAM 한계 극복하고 대형 모델 쾌적하게 돌리기
로컬 환경에서 대규모 언어 모델을 구동해 보신 분들이라면 한 번쯤 뼈저리게 느끼는 장벽이 있습니다. 바로 제한된 자원 인 'VRAM 및 RAM'입니다.
로컬 머신은 클라우드 서버에 비해 자원이 한정적이기 때문에, 어떤 최적화 전략을 사용하느냐에 따라 토큰 출력 속도와 다룰 수 있는 모델의 크기가 천차만별로 달라집니다. 모델마다 특성이 달라 완벽한 '만능 공식'을 드릴 수는 없지만, 쾌적한 로컬 LLM 환경 구축을 위해 반드시 알아야 할 핵심 구성 요소와 실전 세팅법을 상세히 정리해 드립니다.
1. 모델 양자화 다이어트의 시작
원본 LLM은 보통 FP16(16비트 부동소수점) 포맷으로 작성되어 있어 어마어마한 용량을 자랑합니다.
이를 개인 PC에서 돌리기 위해 압축한 것이 바로 양자화 모델입니다.
이 양자화를 거치면 원본 대비 많게는 1/4 이하로 용량이 극적으로 줄어듭니다.
-
GGUF 포맷: 다양한 정수 양자화를 지원하는 가장 대중적인 포맷입니다.
성능 저하를 최소화하면서 용량을 타협할 수 있는Q4_K_M버전이 국룰이자 스위트 스팟으로 꼽힙니다.
이보다 낮으면 답변 품질이 급격히 떨어지고, 이보다 높은Q8등급은 품질은 좋지만 용량 부담이 커집니다. -
MLX 포맷: 맥 사용자라면 MLX 포맷을 사용하시면 됩니다.
별도의 복잡한 양자화 수준 선택 없이 애플 생태계에 맞춰 표준화되어 있어 편리합니다.
한 줄 요약: 애플 실리콘은
MLX, 그 외의 환경은GGUF + Q4_K_M조합이 좋다
2. 컨텍스트 크기와 VRAM의 숨막히는 눈치 게임
모델 용량 예를들어 10GB이 내 VRAM 안에 들어온다고 안심해선 안 됩니다.
컨텍스트 입출력 텍스트 길이를 크게 잡을수록 엄청난 양의 추가 VRAM이 요구되기 때문입니다.
코딩이나 AI 에이전트 용도로 사용할 때는 오픈소스 모델이 지원하는 최대 크기 보통 200k~260k를 할당하고 싶으실 겁니다.
에이전트가 피드백 루프를 제대로 돌리려면 이 정도의 기억력이 필요하니까요.
하지만 여기서 VRAM을 잡아먹는 주범이 등장합니다.
바로 'KV 캐시 Key-Value Cache '입니다.
컨텍스트가 길어질수록, 그리고 모델의 파라미터가 클수록 보관해야 할 KV 캐시의 양은 기하급수적으로 늘어납니다.
대략적인 요구량은 아래 표와 같습니다.
| 모델 파라미터 | 4k 컨텍스트 | 32k 컨텍스트 | 260k 컨텍스트 |
|---|---|---|---|
| 8B | + 0.4 GB | + 3.0 GB | + 26.0 GB |
| 14B | + 0.15 GB | + 3.0 GB | + 40.0 GB |
| 35B | + 0.2 GB | + 6.5 GB | + 52.0 GB |
| 120B | + 1.6 GB | + 13.0 GB | + 105.0 GB |
120B 모델은 Q4_K_M 기준으로 모델 자체 용량만 약 75GB입니다.
여기에 260k 컨텍스트를 주면 VRAM이 180GB 이상 필요하다는 계산이 나옵니다.
로컬에서는 불가능한 수치죠. 오픈라우터 같은 클라우드 서비스를 고를 때도 '얼마나 큰 모델인가' 못지않게 '얼마나 큰 컨텍스트를 지원하는가'가 비용과 기술력의 척도가 되는 이유입니다.
현실적인 조언: 일반적인 로컬 환경에서 대형 모델의 컨텍스트 한계는 대략 20k 수준입니다.
이는 단일 작업 수행에는 충분하지만 복잡한 에이전트 루프에는 턱없이 부족합니다.
로컬 LLM은 '작업 조율자 Orchestrator '보다는 '개별 작업 수행자'로 활용하는 것이 좋습니다.
3. VRAM 다이어트를 위한 3가지 특수 옵션 튜닝
그렇다면 컨텍스트를 최대한 확보하면서 모델을 굴리려면 어떻게 해야 할까요?
다음 세 가지 옵션을 적극 활용해야 합니다.
① KV 캐시 GPU 오프로딩 끄기
- 원리: 기본적으로 KV 캐시를 GPU VRAM에 보관하면 처리 속도는 매우 빨라집니다.
하지만 VRAM을 엄청나게 소모하죠. - 적용: 대규모 컨텍스트를 설정해야 한다면 이 옵션을 반드시 꺼야 합니다.
캐시를 CPU RAM으로 돌림으로써 VRAM 공간을 크게 확보할 수 있습니다.
② FFN 오프로딩
- 원리: 모델 용량의 절반 이상은 가중치가 차지합니다.
최신 모델들은 대부분 MoE 아키텍처를 사용하므로, 모든 가중치가 항상 GPU에 상주할 필요가 없습니다. - 적용: 활성화되지 않은 전문가는 CPU RAM에 두고, 필요할 때만 GPU로 올려 연산하는 방식입니다.
최근에는 유지할 전문가 숫자가 아닌, "몇 개의 레이어를 CPU로 보낼 것인가"를 결정하는 방식으로 발전했습니다.
이를 조절하면 내 VRAM 용량에 딱 맞게 모델을 깎아서 적재할 수 있습니다.
③ KV 캐시 양자화
- 원리: 앞서 모델을 양자화한 것처럼, 메모리를 차지하는 KV 캐시 자체도 양자화할 수 있습니다.
- 적용: 기본
FP16에서INT8이나Q8수준으로만 줄여도 용량이 절반으로 뚝 떨어지지만, 품질 저하는 거의 체감되지 않습니다.
VRAM에 두든 CPU RAM에 두든 전체적인 메모리 요구량을 크게 낮춰주는 효자 옵션입니다.
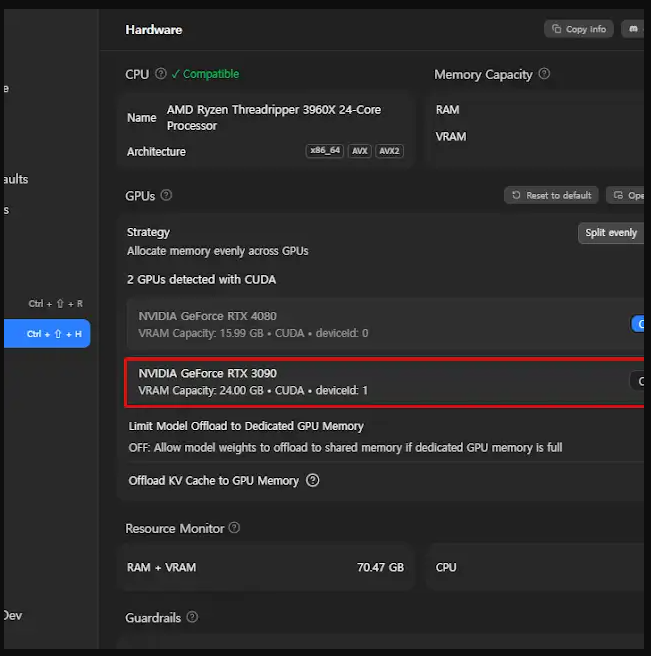
4. RTX 3090으로 122B 대형 모델 굴리기
이론을 알았으니 실제 제 세팅 사례를 공유해 보겠습니다.
- 시스템 환경: CPU RAM 128GB / GPU RTX 3090
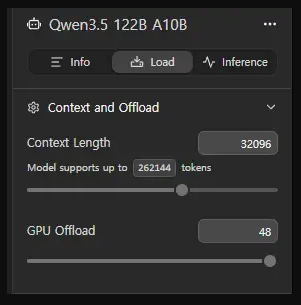
- 대상 모델: Qwen3.5 122b-A10b Q4_K_M
- 목표: 32k 컨텍스트 환경에서 초당 5~7 토큰 이상의 출력 속도 확보
고작 24GB VRAM으로 72GB짜리 모델을, 그것도 32k 컨텍스트로 초당 0.5 토큰 같은 답답한 속도가 아니라 실사용 가능한 속도로 굴릴 수 있을까요?
결론부터 말씀드리면 가능합니다. 아래와 같이 세팅하면 됩니다.
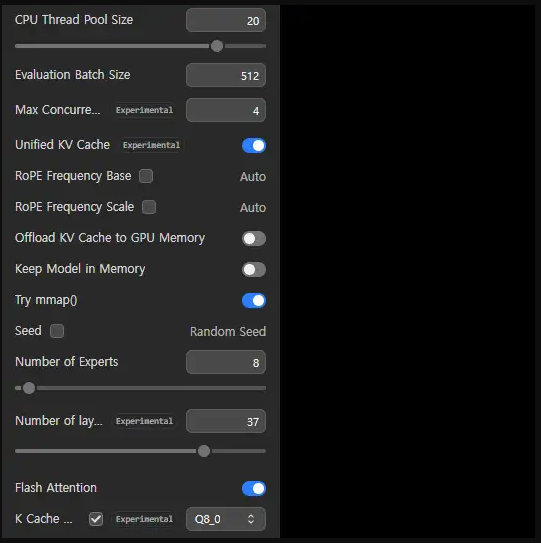
필수 설정 세트
- Offload KV Cache to GPU Memory:
OFF(컨텍스트 확보를 위해 필수) - Keep Model in Memory:
OFF(항상 꺼두는 것을 추천합니다) - Number of Experts:
8유지 (낮추면 품질이 저하됩니다) - Number of layers to force the Expert into CPU (
--n-cpu-moe):37 - Flash Attention:
ON(속도 향상) - KV Cache 양자화:
Q8적용
왜 --n-cpu-moe를 37로 설정했을까?
이 값은 찍은 것이 아니라 VRAM과 모델 아키텍처를 바탕으로 계산된 최적값입니다.
AI에게 직접 물어본 분석 결과는 다음과 같습니다.
"RTX 3090에서 Qwen3.5-122B Q4_K_M 구동 시, VRAM이 넉넉하지 않으므로 활성 전문가일부라도 GPU에 남겨두는 것이 토큰 출력 속도에 유리합니다.
--n-cpu-moe는 첫 N개 레이어만 CPU로 보내는 방식입니다."
분석에 따른 최적 출발점은 38입니다.
- 최고 속도 지향: 36 ~ 38
- 밸런스 추천: 38
- 안정성 지향 : 39 ~ 40
(※ 전제조건: 컨텍스트 4k~8k, KV는 CPU + Q4 양자화, Flash attention ON, 멀티모달 미사용 시 mmproj 제외)
이 계산을 바탕으로 속도와 컨텍스트 확보의 타협점인 37로 설정하여 쾌적한 구동에 성공했습니다.
Qwen 3.5 모델 활용 실전 노하우
부록 1. Qwen3.5 122B의 귀찮은 점과 35B의 재발견
물론 성능 자체는 122B 모델이 압도적입니다.
하지만 122B 버전에는 추론 과정을 끄는 옵션이 없습니다.
간단한 질문에도 막대한 컴퓨팅 자원을 써서 깊게 생각하느라, 결과적으로 토큰 출력 시간이 오래 걸려 답답함을 유발합니다.
반면 Qwen3.5 35B 모델은 품질도 꽤 준수하면서 Thinking 옵션을 끌 수 있습니다.
단순 요약 업무부터 복잡한 에이전트 작업까지 훨씬 빠르고 폭넓게 사용하기 좋습니다.
부록 2. Qwen3.5 35B 모델 최대 컨텍스트로 쥐어짜기
앞서 배운 원리를 그대로 적용하면 35B 모델의 한계치인 260k 컨텍스트를 로컬에서 사용할 수 있습니다.
- 반드시 Offload KV Cache to GPU 옵션을 끕니다.
- KV 캐시 양자화를 켭니다.
- 자신의 VRAM에 맞춰 전문가 오프로딩 레이어 수를 최대한 낮게 조절합니다.
24GB VRAM 사용자라면 FFN 오프로딩을 6개까지 낮춰도 VRAM이 18GB 선에서 컷팅되어 연산 공간이 충분히 남습니다.
반면 16GB VRAM 사용자 분들은 절반 이상의 레이어를 CPU로 오프로딩해야 메모리 에러를 뿜지 않을 것입니다.
이렇게 최적화 세팅을 마치면 260k의 광활한 컨텍스트 환경에서도 초당 20 토큰 이상의 시원시원한 답변 속도를 즐기실 수 있습니다!