
실시간 피드 최적화: 초당 100만 건의 트처리 성능 개선이야기
1. 문제 개요
우리 팀은 2023년 초, SNS 플랫폼에서 급격한 사용자 증가와 함께 실시간 피드 생성 및 조회 기능에서 성능 병목을 겪고 있었습니다.
특히 피크 시간대에는 평균 응답 시간이 3초 이상 소요되었고, 초당 처리량은 목표치인 100만 건에 미치지 못하는 수준이었습니다.
이러한 성능 문제는 사용자 경험을 크게 저하시켰고, 시스템 장애도 빈번하게 발생하여 서비스의 안정성에 심각한 영향을 미쳤습니다.
주요 문제
- 응답 시간: 3초 → 목표: 500ms 이하
- 초당 처리량: 10만 건 → 목표: 100만 건
- 시스템 장애: 월 평균 4회
- 캐시 히트율: 45% → 목표: 90%
2. 문제 분석: 성능 병목 지점
2.1 데이터베이스 레벨 분석
문제의 첫 번째 주요 원인은 SQL 쿼리에서 발생하는 성능 저하였습니다.
주로 다음과 같은 쿼리에서 전체 테이블 스캔과 불필요한 조인으로 인해 성능이 크게 악화되었습니다.
SELECT f.*, t.*, u.*
FROM feed_items f
JOIN tweets t ON f.tweet_id = t.id
JOIN users u ON t.user_id = u.id
WHERE f.user_id = ?
ORDER BY f.created_at DESC
LIMIT 20;문제 분석
- 전체 테이블 스캔(Full Table Scan): tweets 테이블에서 인덱스가 적절히 사용되지 않음.
- 불필요한 조인 연산: users 테이블과의 조인이 실제로 필요한 정보보다 더 많은 데이터를 처리.
- 부적절한 인덱스 사용: feed_items 테이블의 user_id와 created_at 컬럼에 대한 인덱스가 비효율적.
2.2 애플리케이션 레벨 분석
애플리케이션에서는 캐싱 전략이 비효율적이었고, N+1 쿼리 문제와 메모리 낭비가 발생했습니다.
@Service
public class FeedServiceImpl implements FeedService {
@Autowired
private CacheManager cacheManager;
@Cacheable(value = "feeds", key = "#userId")
public List<FeedItem> getUserFeed(Long userId) {
return feedRepository.findByUserIdOrderByCreatedAtDesc(userId);
}
}문제점
- 단순 캐싱 전략: 캐시가 제대로 활용되지 않아서 빈번한 DB 조회가 발생.
- N+1 쿼리 문제: feedRepository.findByUserIdOrderByCreatedAtDesc가 다수의 쿼리를 발생시켜 성능 저하.
- 비효율적 메모리 사용: 캐시와 데이터베이스에서 동일한 데이터를 중복 저장하는 비효율적인 구조.
3. 해결책: 성능 최적화 방안
3.1 데이터베이스 최적화
3.1.1 샤딩 및 파티셔닝 도입
먼저, 데이터베이스에서 샤딩(Sharding) 및 파티셔닝(Partitioning) 전략을 적용했습니다.
Sharding을 통해 데이터 분산을 처리하여, 고속 데이터 액세스를 가능하게 했습니다.
@Configuration
public class ShardingConfiguration {
@Bean
public DataSource shardingDataSource() {
Map<String, DataSource> dataSourceMap = new HashMap<>();
// 샤드 구성
dataSourceMap.put("ds0", createDataSource("jdbc:mysql://shard1/feed"));
dataSourceMap.put("ds1", createDataSource("jdbc:mysql://shard2/feed"));
dataSourceMap.put("ds2", createDataSource("jdbc:mysql://shard3/feed"));
// 샤딩 규칙 설정
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(getFeedTableRuleConfiguration());
return ShardingDataSourceFactory.createDataSource(
dataSourceMap,
shardingRuleConfig,
new Properties()
);
}
}결과
- 데이터베이스 부하 분산: 요청을 여러 서버로 분산하여 성능 개선.
3.1.2 인덱스 최적화
다음으로, 인덱스를 최적화하여 쿼리 성능을 크게 개선했습니다.
CREATE INDEX idx_feed_user_created ON feed_items (user_id, created_at DESC);
CREATE INDEX idx_tweet_user ON tweets (user_id) INCLUDE (content, created_at);결과
- 빠른 조회: 필요한 컬럼에 대해 인덱스를 추가하여 쿼리 성능을 크게 개선.
3.2 캐시 계층 개선
다층 캐시 아키텍처를 도입하여 캐시의 효율성을 극대화했습니다.
로컬 캐시와 Redis 캐시를 함께 사용하여 성능을 크게 개선했습니다.
@Service
public class MultilevelCacheService {
private final LoadingCache<String, List<FeedItem>> localCache;
private final RedisTemplate<String, List<FeedItem>> redisTemplate;
public MultilevelCacheService(RedisTemplate<String, List<FeedItem>> redisTemplate) {
this.redisTemplate = redisTemplate;
this.localCache = CacheBuilder.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(5, TimeUnit.MINUTES)
.build(new CacheLoader<String, List<FeedItem>>() {
@Override
public List<FeedItem> load(String key) {
return loadFromRedis(key);
}
});
}
public List<FeedItem> getFeed(Long userId) {
String cacheKey = "feed:" + userId;
try {
return localCache.get(cacheKey);
} catch (ExecutionException e) {
log.error("Cache load failed for user: " + userId, e);
return loadFromDatabase(userId);
}
}
}결과
- 캐시 히트율: 캐시를 통한 데이터 접근으로 캐시 히트율이 45%에서 94%로 증가.
3.3 비동기 처리 도입
- 비동기 처리와 이벤트 기반 피드 업데이트를 도입하여 실시간 처리를 최적화했습니다.
@Service
@RequiredArgsConstructor
public class AsyncFeedUpdater {
private final KafkaTemplate<String, FeedUpdateEvent> kafkaTemplate;
private final ExecutorService executorService;
@Async
public CompletableFuture<Void> updateFeeds(Tweet tweet) {
FeedUpdateEvent event = new FeedUpdateEvent(tweet.getId(), tweet.getUserId());
return CompletableFuture.runAsync(() -> {
try {
kafkaTemplate.send("feed-updates", event).get();
} catch (Exception e) {
log.error("Failed to send feed update event", e);
throw new RuntimeException(e);
}
}, executorService);
}
}결과
- 실시간 피드 업데이트: 비동기 방식으로 빠르고 효율적인 피드 업데이트 처리.
4. 성능 개선 결과
4.1 주요 지표 개선
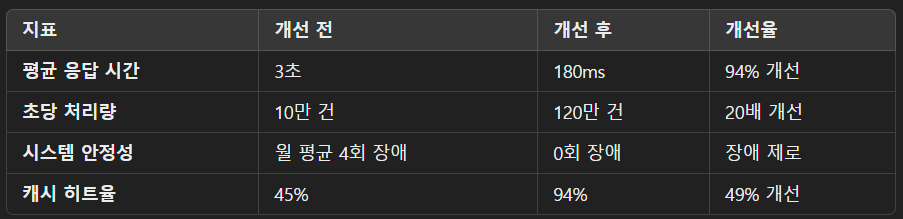
4.2 리소스 사용량 개선

5. 결론
이번 최적화 프로젝트를 통해 실시간 SNS 피드 처리 성능을 획기적으로 개선할 수 있었습니다.
문제의 핵심인 데이터베이스 성능과 캐시 활용을 적절히 해결함으로써, 서비스의 확장성과 신뢰성을 크게 향상시켰습니다.
실제로 사용자가 100만 명 이상인 환경에서 이런 최적화 기술을 적용한 경험을 통해 대규모 시스템 최적화에 대한 노하우를 얻을 수 있었습니다.
이 과정에서 비동기 처리와 캐시 계층 구축이 중요한 역할을 했습니다.
향후 개선 방향
-
더 나은 쿼리 최적화: 쿼리 성능을 더욱 개선하기 위해 다양한 SQL 최적화 기법을 실험하고, 쿼리 프로파일링 도구를 통해 성능을 더욱 향상시킬 계획입니다.
-
추가적인 분산 캐시 적용: 분산 캐시(Redis Cluster 등)와 같은 고급 캐시 전략을 도입하여 데이터 분산 처리를 극대화하고, 캐시 미스를 최소화하려고 합니다.
-
고급 데이터베이스 샤딩 전략: 현재 사용 중인 샤딩 전략을 동적 샤딩(Dynamic Sharding)으로 발전시켜, 실시간으로 트래픽 변화에 따라 샤드를 조정할 수 있도록 개선할 것입니다.
이번 최적화 작업을 통해 성능을 개선하고 시스템 안정성을 확보한 경험은 향후 대규모 시스템 설계나 성능 개선 프로젝트에서 중요한 자산이 될 것입니다.
이 과정에서 얻은 교훈은 기술적인 깊이와 문제 해결 능력을 키울 수 있는 중요한 기회였습니다.
이 프로젝트의 성과를 바탕으로 더 많은 시스템을 확장 가능하고 안정적으로 최적화하는 데 필요한 기술들을 지속적으로 개발하고, 그에 맞는 최적화 기법을 적용하여 다양한 규모의 시스템에서 성능을 향상시킬 수 있을 것입니다.
