1. 네이버 검색 API 사용하기
https://developers.naver.com/docs/serviceapi/search/blog/blog.md#python
- urllib : http 프로토콜에 따라서 서버의 요청/응답을 처리하기 위한 모듈
- urllib.request : 클라이언트의 요청을 처리하는 모듈
- urllib.parse : url 주소에 대한 분석
response, response.getcode(), response.code, response.status
>>>
(<http.client.HTTPResponse at 0x14012e15eb0>, 200, 200, 200)print(response_body)
>>>
b'{\n\t"lastBuildDate":"Mon, 11 Dec 2023 14:50:33 +0900",\n\t"total" ...# 글자로 읽을 때 decode utf-8 설정
print(response_body.decode('utf-8'))
>>>
{
"lastBuildDate":"Mon, 11 Dec 2023 14:50:33 +0900",
"total":427470,
"start":1,
"display":10, ...2. 몰스킨 데이터 정리하기(by. naver API)
순서도
gen_search_url (generate url)
➡ get_result_onpage (get data on one page)
➡ get_fields (convert pandas dataframe)
➡ actMain (all data gathering)
➡ toExcel (export to excel)def gen_search_url(api_node, search_text, start_num, disp_num):
base = "https://openapi.naver.com/v1/search"
node = "/" + api_node + ".json"
param_query = "?query=" + urllib.parse.quote(search_text)
param_start = "&start=" + str(start_num)
param_disp = "&display=" + str(disp_num)
return base + node + param_query + param_start + param_dispimport json
import datetime
def get_result_onpage(url):
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
print("[%s] Url Request Success." % datetime.datetime.now())
return json.loads(response_body.decode("utf-8"))import pandas as pd
def delete_tag(input_str):
input_str = input_str.replace("<b>", "")
input_str = input_str.replace("</b>", "")
return input_str
def get_fields(json_data):
title = [delete_tag(each["title"]) for each in json_data["items"]]
lprice = [each["lprice"] for each in json_data["items"]]
link = [each["link"] for each in json_data["items"]]
mall = [each["mallName"] for each in json_data["items"]]
result_pd = pd.DataFrame({
"title": title,
"lprice": lprice,
"link": link,
"mall": mall
}, columns=["title", "lprice", "link", "mall"])
return result_pdresult_mol = []
for n in range(1, 1000, 100):
url = gen_search_url("shop", "몰스킨", n, 100)
json_result = get_result_onpage(url)
pd_result = get_fields(json_result)
result_mol.append(pd_result)
result_mol = pd.concat(result_mol)All data gathering
result_mol.reset_index(drop=True, inplace=True)
result_mol["lprice"] = result_mol["lprice"].astype("float")
result_mol.info()
>>>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 title 1000 non-null object
1 lprice 1000 non-null float64
2 link 1000 non-null object
3 mall 1000 non-null object
dtypes: float64(1), object(3)
memory usage: 31.4+ KBExport to excel
!pip install xlsxwriterwriter = pd.ExcelWriter(
"../data/06_molskin_diary_in_naver_shop.xlsx",
engine="xlsxwriter"
)
result_mol.to_excel(writer, sheet_name="Sheet1")
workbook = writer.book
worksheet = writer.sheets["Sheet1"]
worksheet.set_column("A:A", 4)
worksheet.set_column("B:B", 60)
worksheet.set_column("C:C", 10)
worksheet.set_column("D:D", 10)
worksheet.set_column("E:E", 50)
worksheet.set_column("F:F", 10)
worksheet.conditional_format("C2:C101", {"type": "3_color_scale"})
writer.close() # writer.save() ❌
3. 시각화
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import font_manager, rc
plt.rcParams['axes.unicode_minus'] = False
rc("font", family="Malgun Gothic")
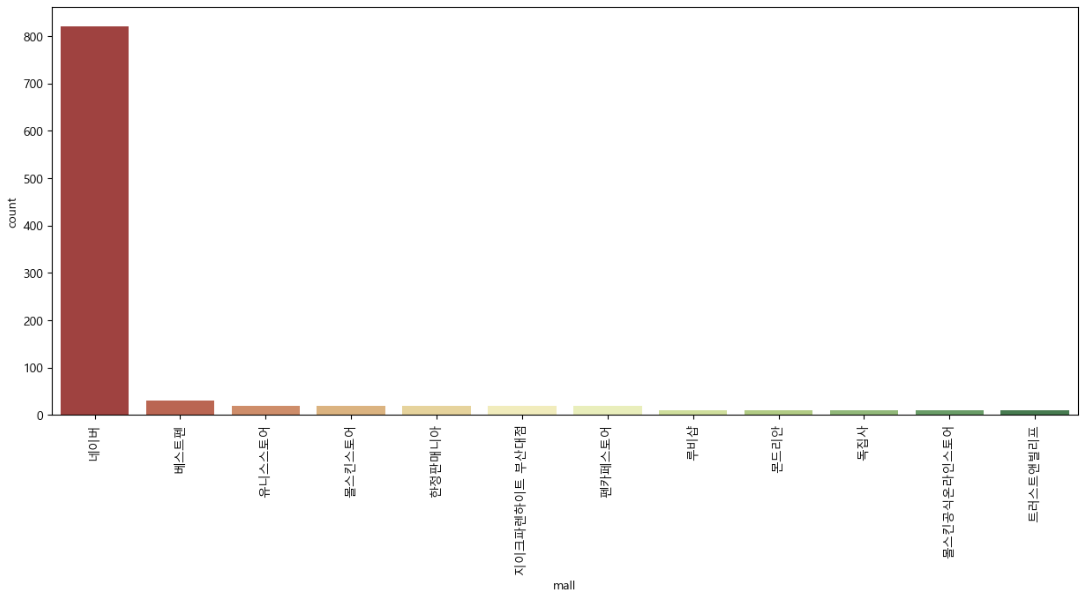
%matplotlib inlineplt.figure(figsize=(15, 6))
sns.countplot(
x=result_mol["mall"], # ⭐x= 를 넣어줘야 함
data=result_mol,
palette="RdYlGn",
order=result_mol["mall"].value_counts().index
)
plt.xticks(rotation=90)
plt.show()