1. 성분 사전 데이터 정리
1-1. PDF 파일 ➡ pickle 파일
PDF 파일에 담긴 정보를 파이썬으로 불러와서 작업하고 싶다면?
https://wikidocs.net/110788
단순한 텍스트가 아니라 규칙이 있는 데이터를 파일로 저장할 때는 데이터 형식을 유지할 수 있어야 한다. 파이썬에서 형식을 유지하면서 데이터를 저장하는 가장 쉬운 방법은 pickle 모듈을 사용하는 것이다.
pip install tabula-pyingredients_list = tabula.read_pdf("경로", pages="all", lattice=True)
type(ingredients_list)
>>>
list # 데이터프레임 형태의 리스트리스트를 pickle 파일로 저장하고
with open('./datas/ingredients_list.pkl', 'wb') as f:
pickle.dump(ingredients_list, f)다시 Pickle 파일을 불러온다.
==
with open('./datas/ingredients_list.pkl', 'rb') as f:
ingredients_list_pkl = pickle.load(f)1-2. 성분 사전 데이터프레임 만들기
pandas.concat()
조건 : index 기준으로 join 없이 단순히 합치기
힌트 : ingredients_list_pkl는 여러 개의 데이터프레임이 element로 들어있는 리스트
ingredients_df = pd.concat(ingredients_list_pkl)1-3. 성분 사전 데이터프레임 수정하기

PDF 파일에서 두 줄이 넘어가는 경우에 \r이 들어가는 모양이다.
제거해준다.
ingredients_df["표준 성분명"] = ingredients_df["표준 성분명"].str.replace("\r", "")
ingredients_df["구명칭"] = ingredients_df["구명칭"].str.replace("\r", "")
ingredients_df["표준 영문명"] = ingredients_df["표준 영문명"].str.replace("\r", " ")
ingredients_df["구영문명"] = ingredients_df["구영문명"].str.replace("\r", " ")PDF를 데이터프레임으로 전환하면서 누락된 데이터를 채워준다.
replace_dict = {'Acetobacter/Lycium Chinense ... }
ingredients_df["표준 영문명"] = ingredients_df["표준 영문명"].replace(replace_dict)2. Target Data 수정
df_target = pd.read_csv("경로", encoding="utf-8")맨 끝에 마침표가 있다면 마지막 마침표만 제거
for idx, row in df_target.iterrows():
if df_target.loc[idx, "Ingredients"][-1:] == ".":
df_target.loc[idx, "Ingredients"] = df_target.loc[idx, "Ingredients"][:-1]". May Contain"을 포함하고 있다면 ". May Contain" 이후 데이터 제거
text = ". May Contain"
tmp_Ingredients = df_target["Ingredients"].str.split(text)
for idx, row in df_target.iterrows():
df_target.loc[idx, "Ingredients"] = tmp_Ingredients[idx][0]replace_str_dict을 이용하여 데이터 변경
for key, value in replace_str_dict.items():
for idx, row in df_target.iterrows():
replace = df_target.loc[idx, "Ingredients"].replace(key, value)
df_target.loc[idx, "Ingredients"] = replace'Ingredients' 컬럼의 데이터를 변환하여 'Ingredients List' 컬럼 만들기
- 'Ingredients' 컬럼의 각 데이터를 ', '로 분리하고 리스트로 변환
- 리스트의 각 element 앞뒤에 공백이 있다면 제거
- 'Ingredients List' 컬럼을 새로 생성하여 앞에서 만든 리스트를 각 행에 맞게 입력
tmp_list = df_target["Ingredients"].str.split(", ")
for i in range(len(tmp_list)):
for j in range(len(tmp_list[i])):
tmp_list[i][j] = tmp_list[i][j].strip()
df_target["Ingredients List"] = tmp_list
3. 성분 사전을 이용하여 Mapping
3-1. Ingredients List 컬럼을 이용하여 Code List 컬럼 만들기
- Ingredients List에 대응하는 Code List의 순서는 같아야 함
- "표준 영문명", "구영문명" 컬럼에서 찾기
- 대소문자 차이가 있을 수 있음
standard_lower = ingredients_df["표준 영문명"].str.lower()
past_lower = ingredients_df["구영문명"].str.lower()
code_list = []
for idx, list in tqdm_notebook(enumerate(df_target["Ingredients List"])):
tmp_code_list = []
for i in range(len(list)):
code = ingredients_df[(standard_lower == list[i].lower()) |
(past_lower == list[i].lower())]["성분코드"].values
if len(code) != 0:
tmp_code_list.append(code[0])
else:
tmp_code_list.append(None)
code_list.append(tmp_code_list)처음에 standard_lower, past_lower 없이 아래와 같이 코드를 작성했더니, 코드 실행 시간이 너무 길었다. (9분 18초)
for문을 돌 때마다 소문자로 변환하는 데 시간이 꽤 걸리는 모양이다.
for i in range(len(list)):
code = ingredients_df[(ingredients_df["표준 영문명"].str.lower() == list[i].lower()) |
(ingredients_df["구영문명"].str.lower() == list[i].lower())]["성분코드"].values3-2. 조건을 만족하는 code를 찾아서 code에 해당하는 dataframe 구하기
- Code List 컬럼을 각 행 내에서 중복 없이 모두 합쳐 두 번 나온 수를 오름차순으로 정렬하고, 첫 번째부터 다섯 번째까지의 수를 찾아 성분 사전을 이용하여 해당 Code들의 dataframe 구하기
- 두 번 나온 수, 오름차순, 첫 번째부터 다섯 번째까지 다시 확인하기
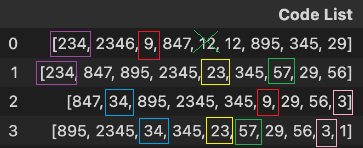
???
문제를 제대로 이해하지 못한 걸까? 답이 절대 안 나온다.
다음에 해설 강의를 참고해서 다시 시도해봐야겠다.
