31장 RegExp
31.1 정규 표현식이란?
정규 표현식(regular expression)은 일정한 패턴을 가진 문자열의 집합을 표현하기 위해 사용되는 형식 언어다.
정규 표현식은 자바스크립트의 고유 문법이 아니며, 대부분의 프로그래밍 언어와 코드 에디터에 내장되어 있다.
정규 표현식은 문자열을 대상으로 패턴 매칭 기능을 제공한다. 패턴 매칭 기능이란 특정 패턴과 일치하는 문자열을 검색하거나 추출 또는 치환할 수 있는 기능을 말한다.
정규 표현식을 사용하면 반복문과 조건문 없이 패턴을 정의하고 테스트하는 것으로 간단히 체크할 수 있다. 다만 정규 표현식은 주석이나 공백을 허용하지 않고 여러 가지 기호를 혼합하여 사용하기 때문에 가독성이 좋지 않다.
31.2 정규 표현식의 생성
- 정규 표현식 생성 방법
- 정규 표현식 리터럴
- RegExp 생성자 함수
일반적인 방법은 정규 표현식 리터럴을 사용하는 것이다.
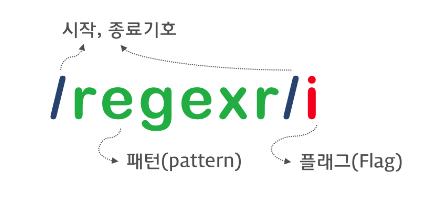
(출처 : https://poiemaweb.com/)
이처럼 정규 표현식 리터럴은 패턴과 플래그로 구성된다.
const target = 'Is this all there is?';
// 패턴: is
// 플래그: i => 대소문자를 구별하지 않고 검색한다.
const regexp = /is/i;
// test 메서드는 target 문자열에 대해 정규표현식 regexp의 패턴을 검색하여 매칭 결과를 불리언 값으로 반환한다.
regexp.test(target); // -> trueRegExp 생성자 함수를 사용하여 RexExp 객체를 생성할 수도 있다.
const target = 'Is this all there is?';
const regexp = new RegExp(/is/i); // ES6
// const regexp = new RegExp(/is/, 'i');
// const regexp = new RegExp('is', 'i');
regexp.test(target); // -> trueRegExp 생성자 함수를 사용하면 변수를 상요해 동적으로 RegExp 객체를 생성할 수 있다.
const count = (str, char) => (str.match(new RegExp(char, 'gi')) ?? []).length;
count('Is this all there is?', 'is'); // -> 3
count('Is this all there is?', 'xx'); // -> 0
// ?? 는 nullish 병합 연산자이다.
// 예를 들어 a ?? b 는 a 가 null 또는 undefined 인 경우 b 를 반환한다는 뜻이다.31.3 RegExp 메서드
- 정규 표현식을 사용하는 메서드
- RegExp.prototype.exec
- RegExp.prototype.test
- String.prototype.match
- String.prototype.replace
- String.prototype.search
- String.prototype.split
이번 장에서는 RegExp.prototype.exec, RegExp.prototype.test, RegExp.prototype.match 메서드에 대해 알아보자.
31.3.1 RegExp.prototype.exec
exec 메서드는 인수로 전달받은 문자열에 대해 정규 표현식의 패턴을 검색하여 매칭 결과를 배열로 반환한다. 매칭 결과가 없는 경우 null을 반환한다.
const target = 'Is this all there is?';
const regExp = /is/;
regExp.exec(target);
// -> ["is", index: 5, input: "Is this all there is?", groups: undefined]exec 메서드는 문자열 내의 모든 패턴을 검색하는 g 플래그를 지정해도 첫 번째 매칭 결과만 반환하므로 주의하기 바란다.
31.3.2 RegExp.prototype.test
test 메서드는 인수로 전달받은 문자열에 대해 정규 표현식의 패턴을 검색하여 매칭 결과를 불리언 값으로 반환한다.
const target = 'Is this all there is?';
const regExp = /is/;
regExp.test(target); // -> true31.3.3 String.prototype.match
String 표준 빌트인 객체가 제공하는 match 메서드는 대상 문자열과 인수로 전달받은 정규 표현식과의 매칭 결과를 배열로 반환한다.
const target = 'Is this all there is?';
const regExp = /is/;
target.match(regExp);
// -> ["is", index: 5, input: "Is this all there is?", groups: undefined]exec 메서드는 문자열 내의 모든 패턴을 검색하는 g 플래그를 지정해도 첫 번째 매칭 결과만 반환한다. 하지만 String.prototype.matct 메서드는 g 플래그가 지정되면 모든 매칭 결과를 배열로 반환한다.
const target = 'Is this all there is?';
const regExp = /is/g;
target.match(regExp); // -> ["is", "is"]| 메서드 | 구현 | 반환값 |
|---|---|---|
| RegExp.prototype.exec | 문자열과 정규 표현식의 패턴을 검색하여 매칭 결과를 반환 | 배열 |
| RegExp.prototype.test | 문자열과 정규 표현식의 패턴을 검색하여 매칭 결과를 반환 | 불리언 값 |
| String.prototype.match | 문자열과 정규 표현식의 패턴을 검색하여 매칭 결과를 반환 | 배열 |
31.4 플래그
패턴과 함께 정규 포현식을 구성하는 플래그는 정규 표현식의 검색 방식을 설정하기 위해 사용
플래그는 총 6개가 있고 그 중 중요한 3개의 플래그를 살펴보자.
| 플래그 | 의미 | 설명 |
|---|---|---|
| i | Ignore case | 대소문자를 구별하지 않고 패턴을 검색 |
| g | Global | 대상 문자열 내에서 패턴과 일치하는 모든 문자열을 전역 검색 |
| m | Multi line | 문자열의 행이 바뀌더라도 패턴 검색을 지속 |
플래그는 옵션이므로 선택적으로 사용할 수 있으며, 순서와 상관없이 하나 이상의 플래그를 동시에 설정할 수도 있다. 어떠한 플래그를 사용하지 않은 경우 대소문자를 구별해서 패턴을 검색한다. 그리고 문자열에 패턴 검색 매칭 대상이 1개 이상 존재해도 첫 번째 매칭한 대상만 검색하고 종료한다.
const target = 'Is this all there is?';
// target 문자열에서 is 문자열을 대소문자를 구별하여 한 번만 검색한다.
target.match(/is/);
// -> ["is", index: 5, input: "Is this all there is?", groups: undefined]
// target 문자열에서 is 문자열을 대소문자를 구별하지 않고 한 번만 검색한다.
target.match(/is/i);
// -> ["Is", index: 0, input: "Is this all there is?", groups: undefined]
// target 문자열에서 is 문자열을 대소문자를 구별하여 전역 검색한다.
target.match(/is/g);
// -> ["is", "is"]
// target 문자열에서 is 문자열을 대소문자를 구별하지 않고 전역 검색한다.
target.match(/is/ig);
// -> ["Is", "is", "is"]31.5 패턴
정규 표현식은 패턴과 플래그로 구성된다.
- 정규 표현식의 패턴과 플래그
- 패턴 : 문자열의 일정한 규칙을 표현
- 플래그 : 정규 표현식의 검색 방식을 설정
31.5.1 문자열 검색
검색 대상 문자열과 플래그를 생략한 정규 표현식의 매칭 결과를 구하면 대소문자를 구별하여 정규 표현식과 매칠한 첫 번째 결과만 반환한다.
const target = 'Is this all there is?';
// 'is' 문자열과 매치하는 패턴. 플래그가 생략되었으므로 대소문자를 구별한다.
const regExp = /is/;
// target과 정규 표현식이 매치하는지 테스트한다.
regExp.test(target); // -> true
// target과 정규 표현식의 매칭 결과를 구한다.
target.match(regExp);
// -> ["is", index: 5, input: "Is this all there is?", groups: undefined]대소문자를 구별하지 않고 검색하려면 플래그 i를 사용한다.
const target = 'Is this all there is?';
// 'is' 문자열과 매치하는 패턴. 플래그 i를 추가하면 대소문자를 구별하지 않는다.
const regExp = /is/i;
target.match(regExp);
// -> ["Is", index: 0, input: "Is this all there is?", groups: undefined]검색 대상 문자열 내에서 패턴과 매치하는 모든 문자열을 전역 검색하려면 플래그 g를 사용한다.
const target = 'Is this all there is?';
// 'is' 문자열과 매치하는 패턴.
// 플래그 g를 추가하면 대상 문자열 내에서 패턴과 일치하는 모든 문자열을 전역 검색한다.
const regExp = /is/ig;
target.match(regExp); // -> ["Is", "is", "is"]31.5.2 임의의 문자열 검색
. 은 임의의 문자 한개를 의미한다. 문자의 내용은 무엇이든 상관없다. 다음 예제의 경우 . 을 3개 연속하여 패턴을 생성했으므로 문자의 내용과 상관없이 3자리 문자열과 매치한다.
const target = 'Is this all there is?';
// 임의의 3자리 문자열을 대소문자를 구별하여 전역 검색한다.
const regExp = /.../g;
target.match(regExp); // -> ["Is ", "thi", "s a", "ll ", "the", "re ", "is?"]31.5.3 반복 검색
{m,n}은 앞선 패턴(다음 예제의 경우 A)이 최소 m번, 최대 n번 반복되는 문자열을 의미한다.
const target = 'A AA B BB Aa Bb AAA';
// 'A'가 최소 1번, 최대 2번 반복되는 문자열을 전역 검색한다.
const regExp = /A{1,2}/g;
target.match(regExp); // -> ["A", "AA", "A", "AA", "A"]{n}은 앞선 패턴이 n번 반복되는 문자열을 의미한다. 즉, {n}은 {n,n}과 같다.
const target = 'A AA B BB Aa Bb AAA';
// 'A'가 2번 반복되는 문자열을 전역 검색한다.
const regExp = /A{2}/g;
target.match(regExp); // -> ["AA", "AA"]{n,}은 앞선 패턴이 최소 n번 이상 반복되는 문자열을 의미한다.
const target = 'A AA B BB Aa Bb AAA';
// 'A'가 최소 2번 이상 반복되는 문자열을 전역 검색한다.
const regExp = /A{2,}/g;
target.match(regExp); // -> ["AA", "AAA"]+ 는 앞선 패턴이 최소 한번 이상 반복되는 문자열을 의미한다. 즉, +는 {1,}과 같다. 다음 예제의 경우 A+는 앞선 패턴 'A'가 한번 이상 반복되는 문자열, 즉 'A'만으로 이루어진 문자열과 매치한다.
const target = 'A AA B BB Aa Bb AAA';
// 'A'가 최소 한 번 이상 반복되는 문자열('A, 'AA', 'AAA', ...)을 전역 검색한다.
const regExp = /A+/g;
target.match(regExp); // -> ["A", "AA", "A", "AAA"]? 는 앞선 패턴이 최대 한번(0번 포함) 이상 반복되는 문자열을 의미한다.(0~1번, 없거나 한번 반복되거나)
즉, ? 는 {0,1}과 같다. 다음 예제의 경우 /colou?r/는 'colo' 다음 'u'가 최대 한 번(0번 포함) 이상 반복되고 'r'이 이어지는 문자열 'color', 'colour'와 매치한다.
const target = 'color colour';
// 'colo' 다음 'u'가 최대 한 번(0번 포함) 이상 반복되고 'r'이 이어지는 문자열 'color', 'colour'를 전역 검색한다.
const regExp = /colou?r/g;
target.match(regExp); // -> ["color", "colour"]31.5.4 OR 검색
| 은 or의 의미를 갖는다. 다음 예제의 /A|B/는 'A'또는 'B' 를 의미한다.
const target = 'A AA B BB Aa Bb';
// 'A' 또는 'B'를 전역 검색한다.
const regExp = /A|B/g;
target.match(regExp); // -> ["A", "A", "A", "B", "B", "B", "A", "B"]분해되지 않은 단어 레벨로 검색하기 위해서는 +를 함께 사용한다.
const target = 'A AA B BB Aa Bb';
// 'A' 또는 'B'가 한 번 이상 반복되는 문자열을 전역 검색한다.
// 'A', 'AA', 'AAA', ... 또는 'B', 'BB', 'BBB', ...
const regExp = /A+|B+/g;
target.match(regExp); // -> ["A", "AA", "B", "BB", "A", "B"]위 예제는 패턴을 or로 한 번 이상 반복하는 것인데 이를 간단히 표현하면 다음과 같다. [ ]내의 문자는 or로 동작한다. 그 뒤에 +를 사용하면 앞선 패턴을 한 번 이상 반복한다.
const target = 'A AA B BB Aa Bb';
// 'A' 또는 'B'가 한 번 이상 반복되는 문자열을 전역 검색한다.
// 'A', 'AA', 'AAA', ... 또는 'B', 'BB', 'BBB', ...
const regExp = /[AB]+/g;
target.match(regExp); // -> ["A", "AA", "B", "BB", "A", "B"]범위를 지정하려면 [ ] 내에 -를 이요한다. 다음 예제의 경우 대문자 알파벳을 검색한다.
const target = 'A AA BB ZZ Aa Bb';
// 'A' ~ 'Z'가 한 번 이상 반복되는 문자열을 전역 검색한다.
// 'A', 'AA', 'AAA', ... 또는 'B', 'BB', 'BBB', ... ~ 또는 'Z', 'ZZ', 'ZZZ', ...
const regExp = /[A-Z]+/g;
target.match(regExp); // -> ["A", "AA", "BB", "ZZ", "A", "B"]대소문자를 구별하지 않고 알파벳을 검색하는 방법은 다음과 같다.
const target = 'AA BB Aa Bb 12';
// 'A' ~ 'Z' 또는 'a' ~ 'z'가 한 번 이상 반복되는 문자열을 전역 검색한다.
// 그냥 필요할 때 검색할까..?
const regExp = /[A-Za-z]+/g;
target.match(regExp); // -> ["AA", "BB", "Aa", "Bb"]숫자를 검색하는 방법은 다음과 같다.
const target = 'AA BB 12,345';
// '0' ~ '9'가 한 번 이상 반복되는 문자열을 전역 검색한다.
const regExp = /[0-9]+/g;
target.match(regExp); // -> ["12", "345"]위 예제의 경우 쉼표 때문에 매칭 결과가 분리되므로 쉼표를 패턴에 포함시킨다.
const target = 'AA BB 12,345';
// '0' ~ '9' 또는 ','가 한 번 이상 반복되는 문자열을 전역 검색한다.
const regExp = /[0-9,]+/g;
target.match(regExp); // -> ["12,345"]위 예제를 간단히 표현하면 다음과 같다.
\d 는 숫자를 의미한다. 즉, \d 는 [0-9]와 같다. \D 는 \d 와 반대로 동작한다. 즉, \D는 숫자가 아닌 문자를 의미한다.
const target = 'AA BB 12,345';
// '0' ~ '9' 또는 ','가 한 번 이상 반복되는 문자열을 전역 검색한다.
let regExp = /[\d,]+/g;
target.match(regExp); // -> ["12,345"]
// '0' ~ '9'가 아닌 문자(숫자가 아닌 문자) 또는 ','가 한 번 이상 반복되는 문자열을 전역 검색한다.
regExp = /[\D,]+/g;
target.match(regExp); // -> ["AA BB ", ","]\w는 알파벳, 숫자, 언더스코어를 의미한다. 즉, \w는 [A-Za-z0-9]와 같다. \W 는 \w 와 반대로 동작한다. 즉, \W 는 알파벳, 숫자, 언더스코어가 아닌 문자를 의미한다.
const target = 'Aa Bb 12,345 _$%&';
// 알파벳, 숫자, 언더스코어, ','가 한 번 이상 반복되는 문자열을 전역 검색한다.
let regExp = /[\w,]+/g;
target.match(regExp); // -> ["Aa", "Bb", "12,345", "_"]
// 알파벳, 숫자, 언더스코어가 아닌 문자 또는 ','가 한 번 이상 반복되는 문자열을 전역 검색한다.
regExp = /[\W,]+/g;
target.match(regExp); // -> [" ", " ", ",", " ", "$%&"]31.5.5 NOT 검색
[...] 내 ^ 는 not 의 의미를 가진다. 예를 들어, [^0-9]는 숫자를 제외한 문자를 의미한다.
\d 는 [0-9] 와 같고, \D 는 [^0-9] 와 같다.
\w 는 [A-Za-z0-9] 와 같고, \W 는 [^A-Za-z0-9] 와 같다.
const target = 'AA BB 12 Aa Bb';
// 숫자를 제외한 문자열을 전역 검색한다.
const regExp = /[^0-9]+/g;
target.match(regExp); // -> ["AA BB ", " Aa Bb"]31.5.6 시작 위치로 검색
[...] 밖의 ^ 는 문자열의 시작을 의미한다.
const target = 'https://poiemaweb.com';
// 'https'로 시작하는지 검사한다.
const regExp = /^https/;
regExp.test(target); // -> true31.5.7 마지막 위치로 검색
$ 는 문자열의 마지막을 의미한다.
const target = 'https://poiemaweb.com';
// 'com'으로 끝나는지 검사한다.
const regExp = /com$/;
regExp.test(target); // -> true31.6 자주 사용하는 정규 표현식
31.6.1 특정 단어로 시작하는 검사
[...] 바깥의 ^ 은 문자열의 시작을 의미하고, ? 은 앞선 패턴이 최대 한 번이상 반복되는지를 의미한다. 다시 말해, 검색 대상 문자열에 앞선 패턴이 있어도 없어도 매치된다.
const url = 'https://example.com';
// 'http://' 또는 'https://'로 시작하는지 검사한다.
/^https?:\/\//.test(url); // -> true
// \/\// 은 시작, 종료 기호랑 겹치니까 이렇게 사용하는 듯?다음 방법도 동일하게 동작한다.
/^(http|https):\/\//.test(url); // -> true31.6.2 특정 단어로 끝나는지 검사
다음 예제는 검색 대상 문자열이 'html'로 끝나는지 검사한다. '$' 는 문자열의 마지막을 의미한다.
const fileName = 'index.html';
// 'html'로 끝나는지 검사한다.
/html$/.test(fileName); // -> true31.6.3 숫자로만 이루어진 문자열인지 검사
[...] 바깥의 ^ 은 문자열의 시작을, $ 는 문자열의 마지막을 의미한다. \d 는 숫자를 의미하고 + 는 앞선 패턴이 최소 한 번 이상 반복되는 문자열을 의미한다. 즉, 처음과 끝이 숫자이고 최소 한 번 이상 반복되는 문자열과 매치한다.
const target = '12345';
// 숫자로만 이루어진 문자열인지 검사한다.
/^\d+$/.test(target); // -> true31.6.4 하나 이상의 공백으로 시작하는지 검사
\s 는 여러 가지 공백 문자(스페이스, 탭 등)를 의미한다. 즉, \s 는 [\t\r\n\v\f] 와 같은 의미다.
const target = ' Hi!';
// 하나 이상의 공백으로 시작하는지 검사한다.
/^[\s]+/.test(target); // -> true31.6.5 아이디로 사용 가능한지 검사
다음 예제는 검색 대상 문자열이 알파벳 대소문자 또는 숫자로 시작하고 끝나면 4~10자리인지 검사한다.
{4,10}은 앞선 패턴이 최소 4번, 최대 10번 반복되는 문자열을 의미한다. 즉, 4~10자리로 이루어진 알파벳 대소문자 또는 숫자를 의미한다.
const id = 'abc123';
// 알파벳 대소문자 또는 숫자로 시작하고 끝나며 4 ~ 10자리인지 검사한다.
/^[A-Za-z0-9]{4,10}$/.test(id); // -> true31.6.6 메일 주소 형식에 맞는지 검사
다음 예제는 검색 대상 문자열이 메일 주소 형식에 맞는지 검사한다.
const email = 'ungmo2@gmail.com';
/^[0-9a-zA-Z]([-_\.]?[0-9a-zA-Z])*@[0-9a-zA-Z]([-_\.]?[0-9a-zA-Z])*\.[a-zA-Z]{2,3}$/.test(email); // -> true
// 음...........참고로 인터넷 메세지 형식 규약인 RFC 5322에 맞는 정교한 패턴 매칭이 필요하다면 다음과 같이 무척이나 복잡한 패턴을 사용할 필요가 있다.
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])
// 음..................................31.6.7 핸드폰 번호 형식에 맞는지 검사
검색 대상 문자열이 핸드폰 번호 형식에 맞는지 검사한다.
const cellphone = '010-1234-5678';
/^\d{3}-\d{3,4}-\d{4}$/.test(cellphone); // -> true31.6.8 특수 문자 포함 여부 검사
검색 대상 문자열에 특수 문자가 포함되어 있는지 검사한다. 특수 문자는 A-Za-z0-9 이외의 문자다.
const target = 'abc#123';
// A-Za-z0-9 이외의 문자가 있는지 검사한다.
(/[^A-Za-z0-9]/gi).test(target); // -> true다음 방식으로 대체해 사용할 수도 있다. 이 방식은 특수 문자를 선택적으로 검사할 수 있다는 장점이 있다.
(/[\{\}\[\]\/?.,;:|\)*~`!^\-_+<>@\#$%&\\\=\(\'\"]/gi).test(target); // -> true특수 문자를 제거할 때는 String.prototype.replace 메서드를 사용한다.
target.replace(/[^A-Za-z0-9]/gi, ''); // -> abc123