
SEO(Search Engine Optimisation)
https://www.notion.so/SEO-Search-Engine-Optimisation-122b7b1c5e924ef2ad5e43a67ce18248
✔️SEO
웹사이트가 검색 결과에 더 잘 보이도록 최적화하는 과정 (검색 엔진 웹 사이트 랭킹은 대부분 영업 비밀임).
구글은 PageRank라는 알고리즘 + 다양한 추가 알고리즘을 사용하는데 추가 정보는 여기.
하루 35억 건 이상의 검색을 처리. 글로벌 검색 엔진 시장의 92%를 점유
✔️검색
색인에서 일치하는 페이지를 검색 → 품질이 가장 높고 사용자와 가장 관련성이 크다고 판단되는 결과를 반환
✔️크롤링
웹을 크롤링 (en-US)하면서 페이지에서 페이지로 링크를 따라가서 찾은 콘텐츠의 색인을 생성함.
검색 결과에 보이는 것은 바로 그 콘텐츠 색인
✔️Google 검색
3 단계로 구분되지만 각 단계가 모든 페이지에 적용되는 것은 아님. 또한 모든 웹페이지가 등록되는 중앙 레지스트리가 있는 것도 아니므로 계속해서 업데이트된 페이지를 크롤링하여 추가함. 사이트 제작자가 사이트맵을 구글에 제출해서 색인에 추가하는 경우도 있음.작동 원리는 아래의 순서로 작동함.
- Crawling: 인터넷에서 찾은 페이지로부터 텍스트, 이미지, 동영상을 다운로드
- 웹에 존재하는 페이지 파악 → 새로운 페이지 목록에 추가 (URL 검색)
- 발견된 자바스크립트를 렌더링.
- Indexing: 페이지의 텍스트, 이미지, 동영상 파일을 분석
- title 및 alt tag, img, video 태그 등 텍스트 콘텐츠 및 핵심 콘텐츠 태그와 속성을 처리 및 분석
- 비슷한 페이지들을 찾고 이 그룹을 잘 대표하는 페이지를 선택(클러스터링이라고 함)
- 비슷한 페이지들 중
- 표준 페이지와 해당 클러스터에 관해 수집한 정보는 수천 대의 컴퓨터에서 호스팅되는 대규모 데이터베이스에 저장(여기서 데이터베이스기 구글 색인임.)
- Serving search results: 사용자가 검색을 하면 사용자의 검색어와 관련된 정보를 반환함
- 관련성에 따라서 정보를 리턴함. (관련성 예시: 유저 위치, 언어, 모바일-데스크탑 환경, … )
✔️네이버 검색
네이버 검색엔진은 SPA 사이트의 경우 네이버 검색로봇도 수집 및 콘텐츠 해석 과정에서 자바스크립트의 영향도를 측정하고 해석. 근데 몇 배 이상의 리소스가 필요한 작업이니까
→ SPA 사이트라도 HTML의 주요 영역 생성은 검색로봇이 잘 인식할 수 있도록 서버에서 렌더링 SSR 처리하는 것을 권장합니다.
-
검색로봇이 자바스크립트를 활용하여 동적으로 HTML을 처리하는 페이지를 발견하는 경우 페이지에 포함된 자바 스크립트 리소스가 수집되어 있는지를 체크합니다.
-
자바스크립트가 수집되어 있지 않으면 정적인 HTML의 내용을 먼저 수집하여 색인 처리합니다.
-
HTML에 포함되어 있는 자바스크립트 리소스는 별도의 수집 과정을 거쳐서 렌더링 서버에 일정 기간 저장됩니다. 간혹 자바스크립트 url에 timestamp 혹은 hash 값을 넣어서 리소스의 최신성을 강제로 처리하는 경우가 발견되고 있습니다. 이 경우 수집 과정에서 페이지의 콘텐츠 해석에 문제가 발생할 수 있으므로 권장하지 않습니다.
-
검색로봇이 해당 페이지를 재 방문할 때 확보된 자바 스크립트가 있다면 해당 스크립트를 포함하여 렌더링을 진행합니다.
-
렌더링 결과 페이지의 주요 콘텐츠 내용이 변경되어 있는지를 파악한 후 색인을 업데이트 여부를 결정합니다.
✔️SEO를 향상하기 위한 방법
출처: 구글 SEO 향상
일반 가이드라인
콘텐츠 가이드라인
품질 가이드라인
✔️Canonical URL(= 선호 URL)
동일 콘텐츠를 여러 개의 URL로 표현이 가능할 경우 가장 선호되는 대표 URL을 지정해야 함.
동일 콘텐츠가 여러 개의 URL로 표현이 가능한 예시
http://www.mysite.com/article/article1.html
http://www.mysite.com/article/article1.html?type=1&code=a
http://www.mysite.com/article/article1.html?type=2&code=bCanonicalization(선호 URL을 만드는 과정)이 필요한 이유:
- 어떤 URL이 검색 결과에 나오는지 알게 하기 위해서
- 비슷하거나 복제된 페이지들에 대한 링크 시그널을 통합하기 위해서
- 같은 제품이나 주제에 대해서 트래킹할 항목을 단순화함
- Content Syndication 관리를 위하여(자신이 만든 콘텐츠를 검색 순위 상위에 올림)
- 복제된 페이지를 다시 크롤링하는 데 에너지 낭비하는 걸 방지하기 위함
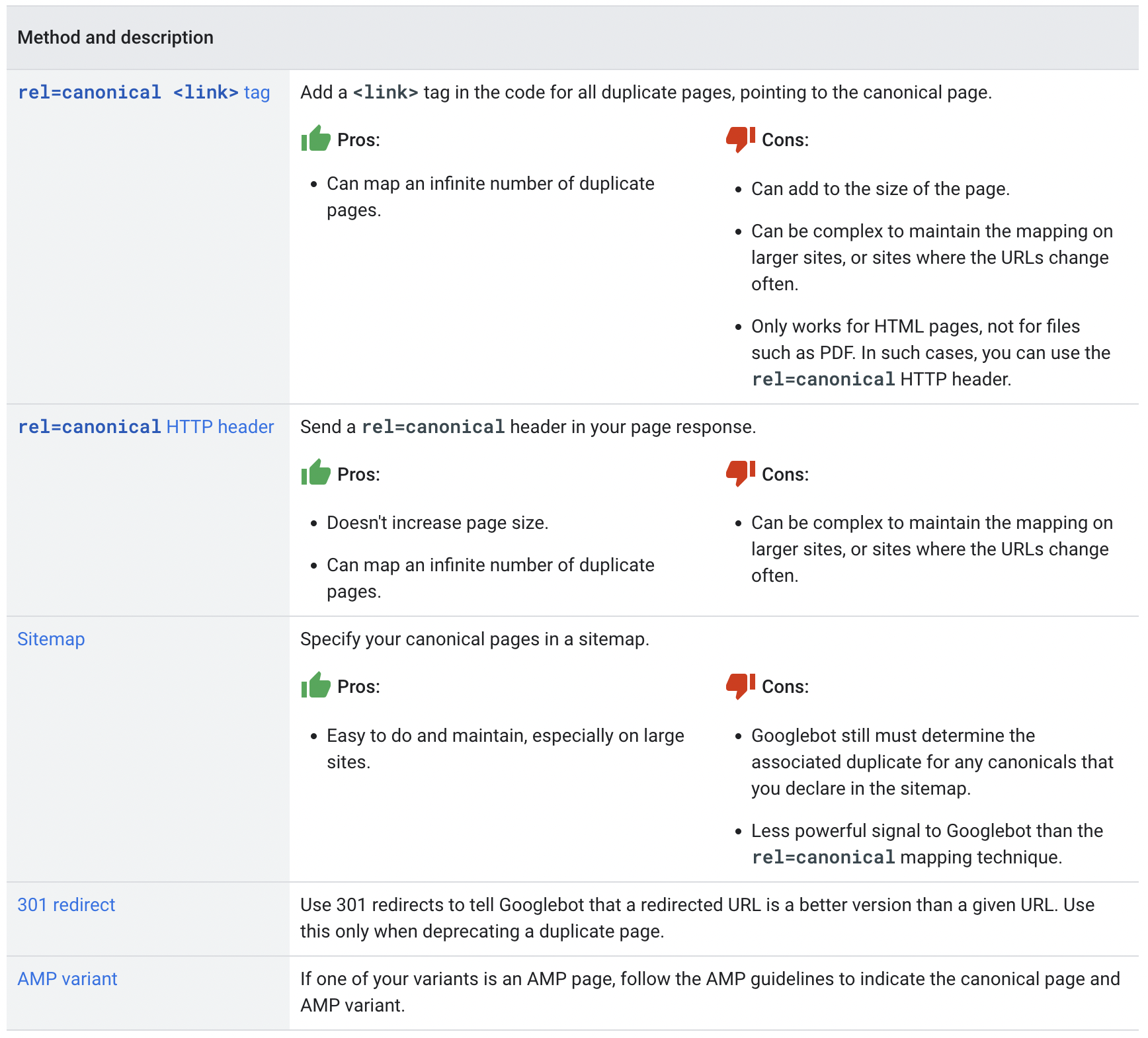
✔️Canonical URL을 만드는 방법
[rel=canonical <link>tag](https://developers.google.com/search/docs/advanced/crawling/consolidate-duplicate-urls#rel-canonical-link-method)<link rel="canonical" href="https://example.com/dresses/green-dresses" />[rel=canonicalHTTP header](https://developers.google.com/search/docs/advanced/crawling/consolidate-duplicate-urls#rel-canonical-header-method)- Sitemap
- 301 redirect
- AMP variant
✔️Robots.txt
Robots.txt 예시
User-agent: Googlebot
Disallow: /nogooglebot/
Disallow: /*.xls$
Disallow: /books/fiction/contemporary/
User-agent: *
Allow: /
Sitemap: http://www.example.com/sitemap.xml- 구글봇은 http://example.com/nogooglebot/ 를 크롤링하지 못함.
- .xls파일도 크롤링하지 못함.
- /books/fiction/contemporary/ 디렉토리 안도 크롤링하지 못함.
- 유저는 모든 사이트를 방문 가능함.
- 사이트맵은 http://www.example.com/sitemap.xml 에 명시됨.
User-agent: *
Disallow: /
User-agent: Mediapartners-Google
Allow: /- 모든 크롤러를 허용하지 않지만 Mediapartners-Google만 허용함.
✔️Rich results
Rich results는 Carousel, 이미지, non-textual elements들을 잘 수집해서 띄워줌.
→ 이거 구글이 수집해서 검색하면 예쁘게 띄워줌.
구글 검색은 페이지의 콘텐츠를 이해하기 위해서 노력함. 이 과정을 도와주기 위해서 Structured data를 표준화된 방법으로 페이지에 작성해 놓으면 페이지를 콘텐츠를 분류하는 데 도움을 줌.
- Structured data는 Microdata, RDFa, JSON-LD 타입을 지원하는데 그 중 JSON-LD를 보겠음
JSON-LD 타입
{
"@context": "https://json-ld.org/contexts/person.jsonld",
"@id": "http://dbpedia.org/resource/John_Lennon",
"name": "John Lennon",
"born": "1940-10-09",
"spouse": "http://dbpedia.org/resource/Cynthia_Lennon"
}Structured data를 사용한 웹 페이지 예시
<html>
<head>
<title>Party Coffee Cake</title>
<script type="application/ld+json">
{
"@context": "https://schema.org/",
"@type": "Recipe",
"name": "Party Coffee Cake",
"author": {
"@type": "Person",
"name": "Mary Stone"
},
"datePublished": "2018-03-10",
"description": "This coffee cake is awesome and perfect for parties.",
"prepTime": "PT20M"
}
</script>
</head>
<body>
...
</body>
</html><html>
<head>
<title>Apple Pie by Grandma</title>
<script type="application/ld+json">
{
"@context": "https://schema.org/",
"@type": "Recipe",
"name": "Apple Pie by Grandma",
"author": "Elaine Smith",
"image": "http://images.edge-generalmills.com/56459281-6fe6-4d9d-984f-385c9488d824.jpg",
"description": "A classic apple pie.",
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": "4.8",
"reviewCount": "7462",
"bestRating": "5",
"worstRating": "1"
},
"prepTime": "PT30M",
"totalTime": "PT1H30M",
"recipeYield": "8",
"nutrition": {
"@type": "NutritionInformation",
"calories": "512 calories"
},
"recipeIngredient": [
"1 box refrigerated pie crusts, softened as directed on box",
"6 cups thinly sliced, peeled apples (6 medium)"
]
}
</script>
</head>
<body>
</body>
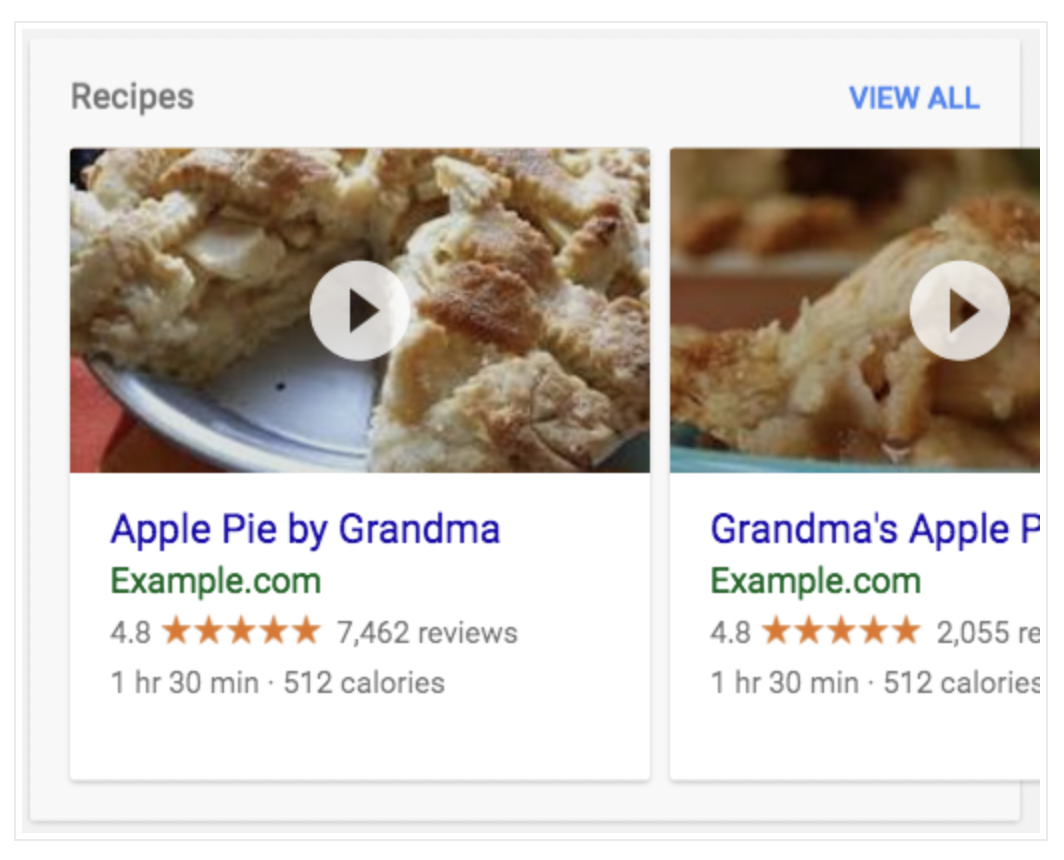
</html>Structured data가 잘 작성된 웹 페이지. Google은 이걸 잘 뽑아서 검색하면 아래와 같이 나옴.
Structured data 작성 방법:
아주 다양함. (Feature, book, breadcrumb, carousel, course, dataset … 등등)
https://developers.google.com/search/docs/advanced/structured-data/search-gallery
Structured data에 들어갈 수 있는 key와 value들
https://schema.org/docs/full.html
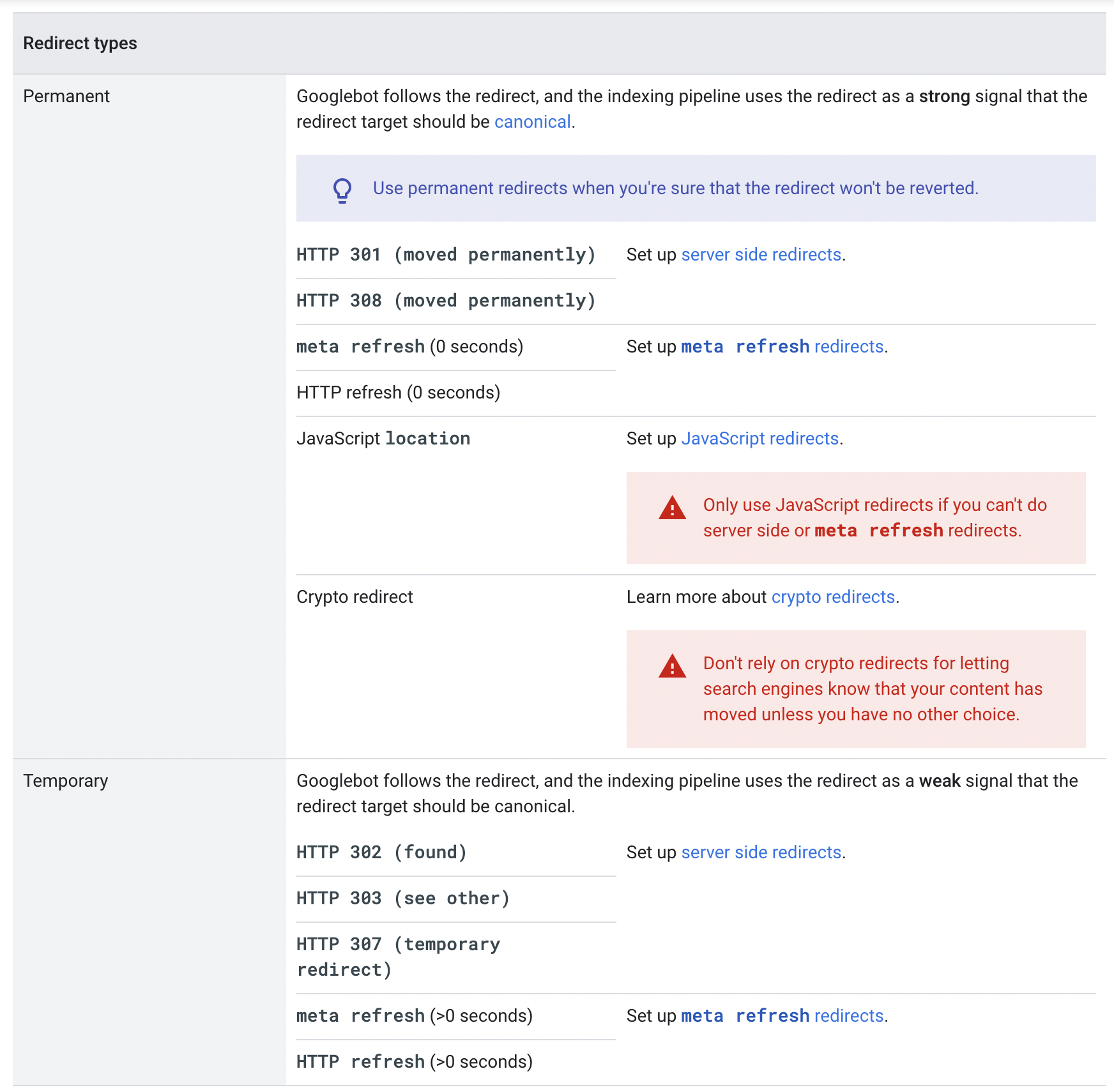
✔️Redirection
SEO
영구적인 리디렉션: 검색 결과에 새 리디렉션 대상 표시
임시 리디렉션: 검색 결과에 소스 페이지 표시
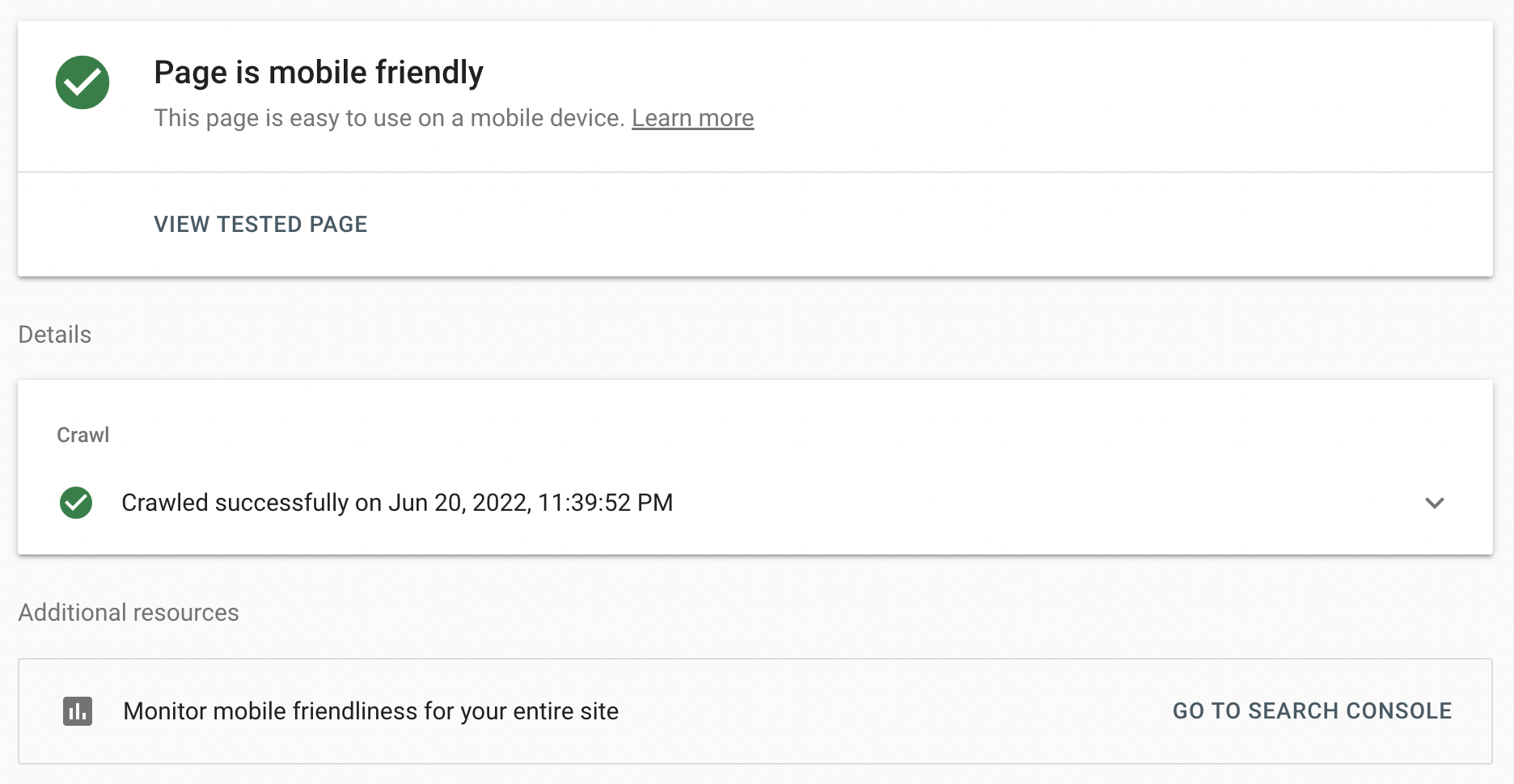
✔️SEO 테스팅 링크
구글 모바일 프렌들리 테스트
https://search.google.com/test/mobile-friendly
구글 리치 결과 테스트
https://search.google.com/test/rich-results?hl=en
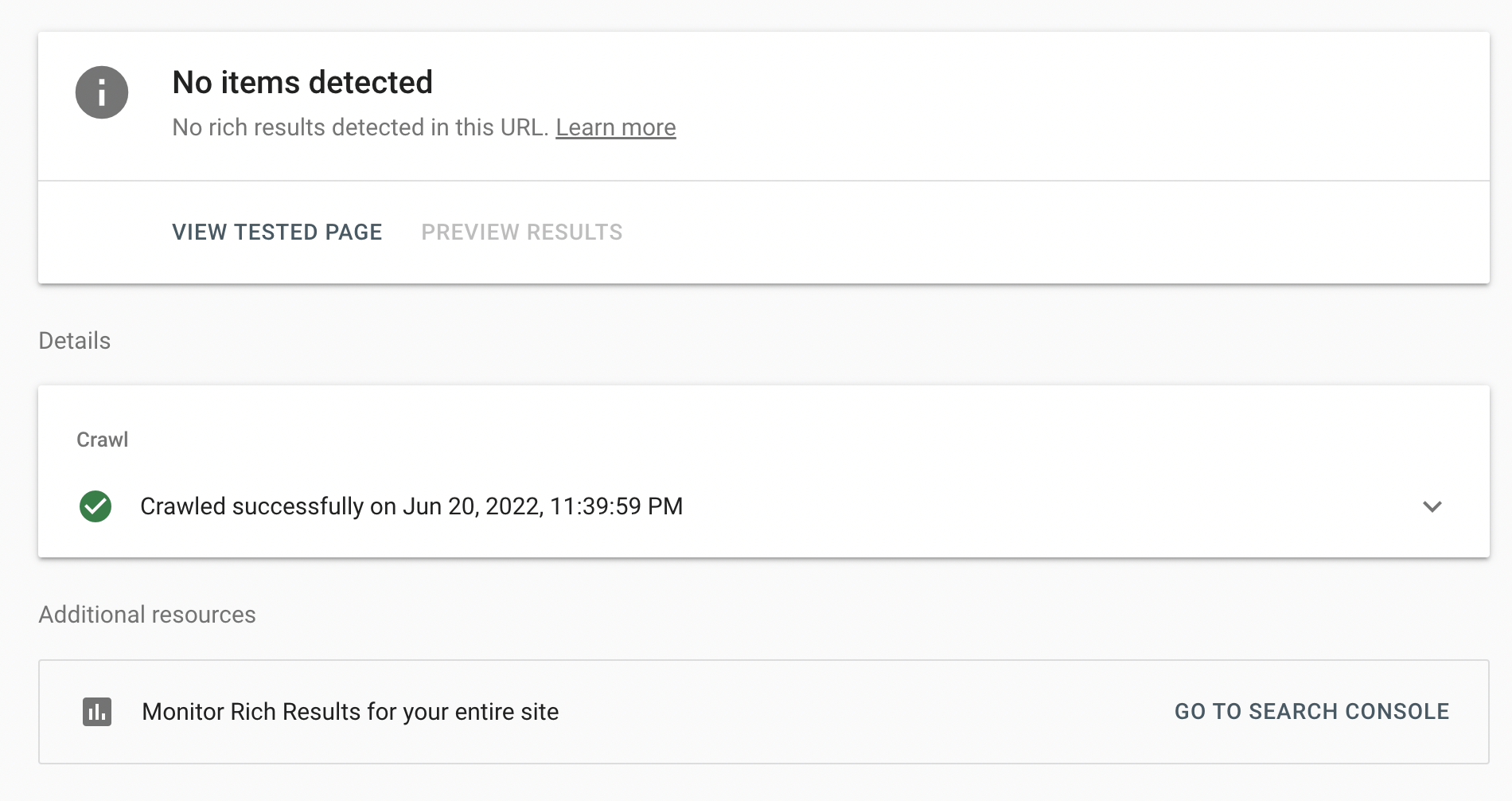
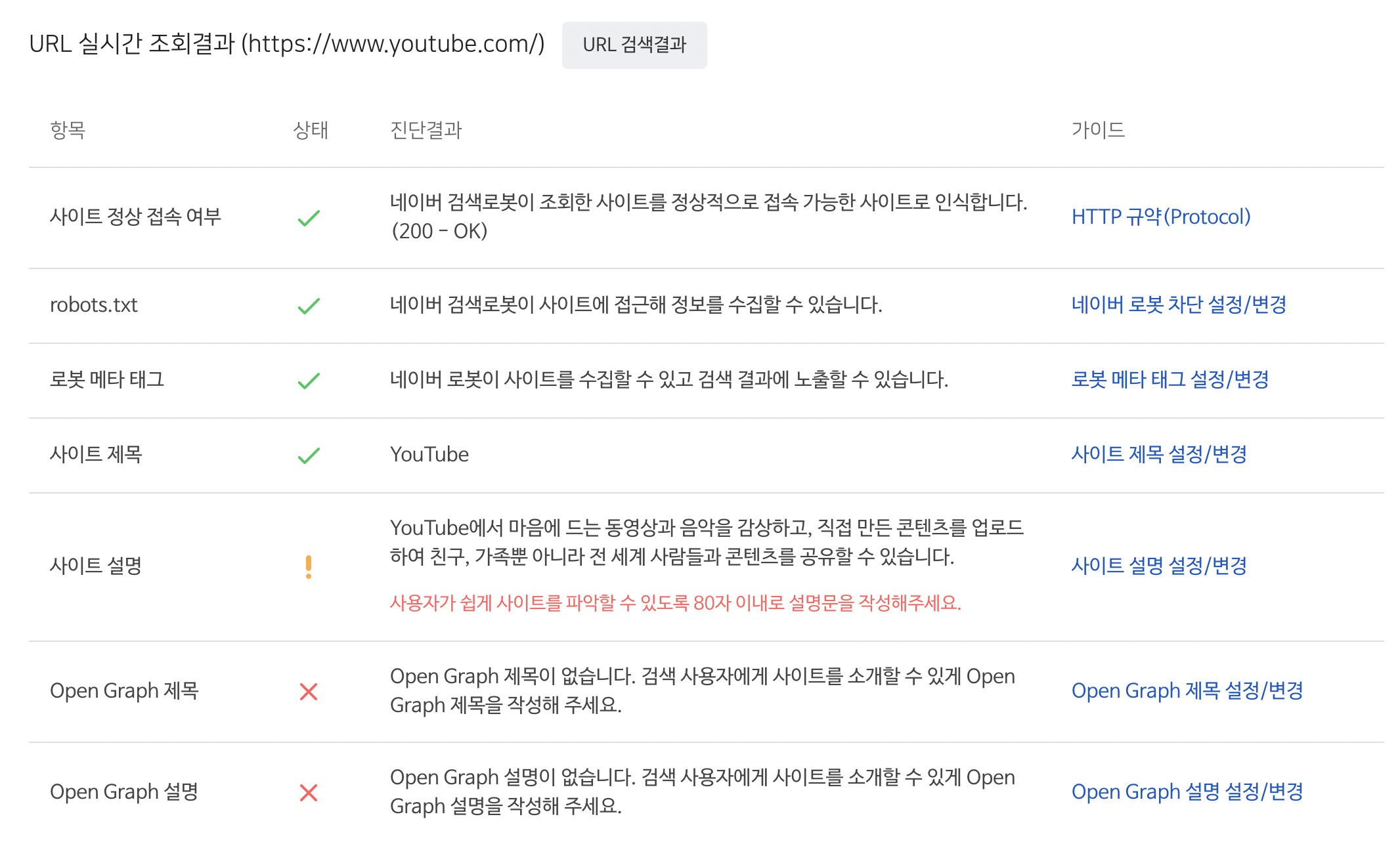
네이버 사이트 간단 체크
Structured data validator
출처
https://developers.google.com/search/docs
https://search.google.com/test/rich-results?hl=en

