
Intro.
최근 서비스의 복잡도가 증가하면서 데이터베이스로부터 가져와야 하는 데이터가 많아지게 되었다. 클라이언트 및 서버에서 이런 복잡도가 증가함에 따라 추가로 수행해야 하는 작업들이 늘어나게 되었다. 기존 REST API 방식에서 복잡성이 증가할수록 호출 방식이 까다로워졌다. 이러한 배경으로 클라이언트-서버의 통신 방식의 대체자로 GraphQL이 제시되었다.
GraphQL이란?
GraphQL is a query language and a server-side runtime (typically served over HTTP)
*GraphQL is a language for querying data. Unlike most query languages (such as SQL), you don’t use GraphQL to query a particular type of data store. Instead, you use GraphQL to query data from any number of different sources.
GraphQL은 쿼리 언어이며 특정 스토리지 엔진에 종속되지 않고 데이터에 의해 지원된다.
하지만 GraphQL에서 말하는 쿼리는 기존 REST API 방식의 쿼리와는 조금 다르다.
REST API
/v1/user
/v1/post/{id}REST API는 REST(Representational State Transfer) 이라는 이름을 가지고 있듯, HTTP Method를 통해 동작을 정하고 URI를 통해 어떤 자원에 대한 동작을 할지를 표현한다.
하지만 GraphQL 방식은 단일 endpoint를 통해 데이터를 가지고 올 수 있는 특징이 있다.
REST의 문제점
- UnderFetching : 하나의 endpoint로 필요한 모든 데이터의 요청을 하지 못해 여러 번의 네트워크 비용을 타야 되는 단점이 존재한다.
- OverFetching : endpoint로 응답 받은 정보가 불필요하게 많을 경우 네트워크 낭비가 존재한다.
→ 즉 클라이언트가 필요한 만큼만 데이터를 fetch 할 수 있는 효율적인 방법으로 제시된 것이 GraphQL이라고 할 수 있다. 부하 완화용이라고 생각하면 될 것이다.
REST API vs GraphQL
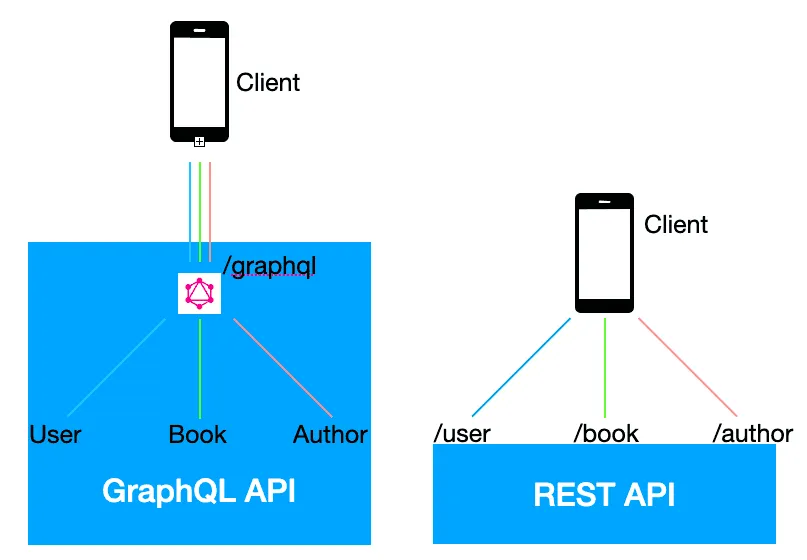
- 형태 정의 및 데이터 요청 방식 : 자원에 대한 접근을 할 때 REST API는 형태를 정의하고 요청방법이 연결되어 있지만 GraphQL 상에서는 분리되어 있다.
- 자원의 크기와 형태 결정 주체 : REST 상에서는 서버쪽에서 결정하지만, GraphQL은 자원에 대한 정보만 정의하고 필요한 요소들은 Client 요청 시 결정한다.
- 작업의 유형 : REST 상에서는 url과 method가 결정하지만 GraphQL은 Schema가 Resource를 나타내고 Query, Mutation 타입이 작업의 유형을 나타낸다.
- 요청 횟수 : REST는 여러 자원에 접근할 때 여러 번의 요청이 필요하지만 GraphQL에서는 한번의 요청에서 여러 Resource에 접근할 수 있다.
- 작업 처리 방식 : REST에서 각 요청은 해당 엔드포인트에 정의된 핸들링 함수를 호출하여 작업을 처리하지만, GraphQL에서는 요청 받은 각 필드에 대한 resolver를 호출하여 작업을 처리한다.
Operations
- Query
- Mutation
GraphQL에는 Query와 Mutation이라는 2가지 동작 타입이 존재한다.
Query는 REST 방식에서 GET과 같이 데이터를 가져오는 것이고, Mutation은 POST, DELETE와 같이 시스템의 변화를 유발하는 동작이다.
Query
Fields
query HeroName {
hero {
name
}
}
{
"data": {
"hero": {
"name": "R2-D2"
}
}
}Query의 모양과 JSON 반환 형태가 동일한 것을 확인할 수 있다.
Arguments
query HumanInfo {
human(id: "1000") {
name
height(unit: FOOT)
}
}
{
"data": {
"human": {
"name": "Luke Skywalker",
"height": 5.6430448
}
}
}위처럼 REST와 달리, 요청에 Query Param이나 URL 세그먼트를 통한 인자 값을 넘기는 것과는 다르게 GraphQL에서는 모든 필드가 인자를 가질 수 있다.
Aliases
query Heroes {
empireHero: hero(episode: EMPIRE) {
name
}
jediHero: hero(episode: JEDI) {
name
}
}
{
"data": {
"empireHero": {
"name": "Luke Skywalker"
},
"jediHero": {
"name": "R2-D2"
}
}
}별칭 없이 쿼리했을 때 hero 필드는 충돌한다. 이를 위해 별칭을 지정하여 한 요청에서 두 결과를 모두 얻는다.
Fragments
{
"data": {
"leftComparison": {
"name": "Luke Skywalker",
"appearsIn": [
"NEWHOPE",
"EMPIRE",
"JEDI"
],
"friends": [
{
"name": "Han Solo"
},
{
"name": "Leia Organa"
},
{
"name": "C-3PO"
},
{
"name": "R2-D2"
}
]
},
"rightComparison": {
"name": "R2-D2",
"appearsIn": [
"NEWHOPE",
"EMPIRE",
"JEDI"
],
"friends": [
{
"name": "Luke Skywalker"
},
{
"name": "Han Solo"
},
{
"name": "Leia Organa"
}
]
}
}
}다음과 같은 결과를 얻으려면 GraphQL의 쿼리를 다음과 같이 작성해야 한다.
query Heroes {
leftComparison: hero(episode: EMPIRE) {
name
appearsIn
friends {
name
}
}
rightComparison: hero(episode: JEDI) {
name
appearsIn
friends {
name
}
}
}이렇게 쿼리 내용이 반복되게 된다. 개발자는 반복을 싫어하는 동물이므로..
이를 위해 fragment라는 단위로 반복되는 부분을 줄일 수 있다. 다음과 같이 말이다.
query Heroes {
leftComparison: hero(episode: EMPIRE) {
...comparisonFields
}
rightComparison: hero(episode: JEDI) {
...comparisonFields
}
}
fragment comparisonFields on Character {
name
appearsIn
friends {
name
}
}쿼리가 짧아서 중복된 부분이 극단적으로 짧아지지는 않았지만 더욱 복잡한 쿼리일수록 이 부분은 명확히 차이가 날 것이다.
Variables
query HeroNameAndFriends($episode: Episode) {
hero(episode: $episode) {
name
friends {
name
}
}
}
{
"data": {
"hero": {
"name": "R2-D2",
"friends": [
{
"name": "Luke Skywalker"
},
{
"name": "Han Solo"
},
{
"name": "Leia Organa"
}
]
}
}
}- 쿼리 안의 정적 값을
$variableName으로 변경한다. $variableName을 쿼리에서 받는 변수로 선언한다.- JSON에는
variableName: value와 같이 전달한다.
Directives
비즈니스 특성 상 쿼리의 구조와 형태를 동적으로 바꿀 필요가 생길수도 있다.
이러한 요소를 위해 **Directive** 기능이 존재한다.
query Hero($episode: Episode, $withFriends: Boolean!) {
hero(episode: $episode) {
name
friends @include(if: $withFriends) {
name
}
}
}{
"episode": "JEDI",
"withFriends": true
}{
"data": {
"hero": {
"name": "R2-D2",
"friends": [
{
"name": "Luke Skywalker"
},
{
"name": "Han Solo"
},
{
"name": "Leia Organa"
}
]
}
}
}요청 JSON 필드에 withFriends를 true로 하게 되면 응답 JSON 필드에 friends 필드가 포함되게 된다. 여기에서 사용된 Directive는 @include 이고 내부 조건은 (if: $withFriends)를 통해 boolean 값을 넣어준 것이다.
추가적으로 @skip(if: Boolean) 이라는 지시어가 있는데 true면 필드를 건너뛴다고 한다.
Mutation
아까 말했듯, Mutation은 서버 자원의 변경을 유발하는 동작이다.
mutation CreateReviewForEpisode($ep: Episode!, $review: ReviewInput!) {
createReview(episode: $ep, review: $review) {
stars
commentary
}
}{
"ep": "JEDI",
"review": {
"stars": 5,
"commentary": "This is a great movie!"
}
}여기서는 동작을 mutation으로 설정해야 한다. 여기서 주목해야 할 점은 review 변수가 스칼라 값이 아닌 인자로 전달된 object type임을 명시해야 한다.
또한 중요한 점은 query는 병렬로 실행되지만 mutation은 순차적으로 실행된다는 것이다.
Inline Fragments
query HeroForEpisode($ep: Episode!) {
hero(episode: $ep) {
name
... on Droid {
primaryFunction
}
... on Human {
height
}
}
}… on Droid : hero에서 반환된 Character가 Droid 타입인 경우 내부 primaryFunction을 실행
… on Human : hero에서 반환된 Character가 Human 타입인 경우 height 필드도 함께 반환함.
Meta fields
{
search(text: "an") {
__typename
... on Human {
name
}
... on Droid {
name
}
... on Starship {
name
}
}
}
{
"data": {
"search": [
{
"__typename": "Human",
"name": "Han Solo"
},
{
"__typename": "Human",
"name": "Leia Organa"
},
{
"__typename": "Starship",
"name": "TIE Advanced x1"
}
]
}
}return 타입을 모르는 상황일 때 클라이언트에서 해당 데이터를 처리하기 위해 메타 필드인 __typename을 사용하여 객체 타입의 이름을 얻을 수 있다.
Security
이 부분은 클라이언트에게 쿼리에 대한 큰 권한이 부여되는만큼 여러 보안 상의 문제가 발생할 수 있는 여지가 크다고 느꼈다. 그래서 이 부분에 대해서 좀 더 파봤다.
query {
getUserList {
ok
user {
user_id
username
Project {
project_position_no {
PC {
candidate {
user_id
username
Project {
project_position_no {
PC {
candidate {
user_id
username
Project {
project_position_no {
PC {
candidate {
... 생략
}
}
}
}
}
}
}
}
}
}
}
}
}
}
}이러한 쿼리 공격이 지속적으로 가해진다면 서버가 다운될 것이 분명하다. GraphQL이 클라이언트에게 자유도가 높은 쿼리문을 허용하는만큼 공격자들에게도 자유로운 공격 권한이 생긴다고 해도 무방할 것이다.
그럼 이걸 어떻게 해결해야 할까? 찾아본 바로는 몇가지 존재한다.
1. Timeout
timeout을 통해 특정 쿼리문의 실행이 몇초 이내로 처리되어야 하는지를 설정하는 방법이다. 하지만 이 방법은 몇초를 설정해야 할지에 대한 문제가 있기에 지나치게 짧게 설정해서 쿼리가 모두 실패하는 문제가 생길 수 있다. 또한 Timeout이 이러한 악성 공격을 막을 수 있는지에 대한 것도 불분명하다.
2. Query의 길이를 제한하는 방법
이 방법은 위와 같은 예시의 긴 공격을 막을 수는 있을 것이다. 하지만 유효한 쿼리에 대한 길이가 명확한 것도 아니기 때문에 Timeout과 비슷한 방법이라고 생각한다.
3. Query Whitelist
GraphQL은 클라이언트에게 자유도 높은 쿼리를 제공하기 위해 사용하는 방식인데 이러한 화이트리스트 방식은 GraphQL과는 어울리지 않는다. 또한 자유도가 높은 만큼 어떤 쿼리가 존재하는지에 대한 예측도 힘들 것이다.
4. Depth Limiting
위의 예시에서 depth가 대략 20이 넘어간다. 깊이를 제한하는 방법으로 모든 악성 쿼리를 막을 수는 없겠지만 과도한 악성 쿼리를 어느정도 필터링할 수 있을 것이라고 생각한다.
5. Query Complexity
쿼리의 복잡성은 그냥 쿼리 필드의 개수라고 생각하면 된다. 이 방법도 완벽한 보안책은 아니고 특히 mutation은 쿼리 복잡성을 추론하기 힘들다는 단점이 존재하기도 한다.
그럼 어떤 방법을 사용해야 할까?
모든 방법이 silver bullet이지는 않지만 복잡도에 기반한 throttling 기법을 이용하는 것이 현재로서 최선의 방법이라고 하는 것 같다.
Throttling은 일정 기간동안 처리할 수 있는 쿼리의 수를 제한하는 것이다. 하지만 대부분 예제에서는 Depth Limit을 이용한 방식을 많이 채택되고 있는데 눈에 띄는 악성 쿼리를 막을 수 있기 때문이라고 본다. 이것도 충분히 방어 될 것이라고 생각된다.
Server Use Case
예시는 구글링하면 쉽게 찾을 수 있을 것 같아서 첨부하지는 않았습니다..! 그런데 Netflix에서 제시한 GraphQL용 프레임워크가 있어서 재밌어보여 공유드립니다.
Netflix GraphQL Framework
https://github.com/Netflix/dgs-framework
References
GraphQL | A query language for your API
