
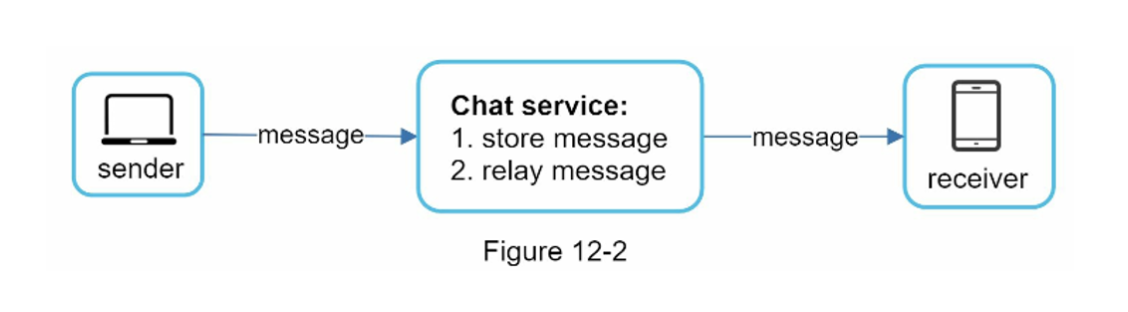
기본 기능
- 클라이언트들로부터 메시지 수신
- 메시지 수신자(recipient) 결정 및 전달
- 수신자가 접속이 아닐 경우 접속 전까지 메시지 보관
통신 프로토콜
-
HTTP
대부분의 채팅 시스템은 초기에 HTTP를 이용함. TCP handshake 등의 비용을 줄이기 위해 keep-alive 옵션을 사용하여 연결을 지속할 수 있음. 클라이언트 → 서버로의 메시지는 보낼 수 있지만 서버 → 클라이언트 방향으로는 메시지를 보낼 수 없음.
-
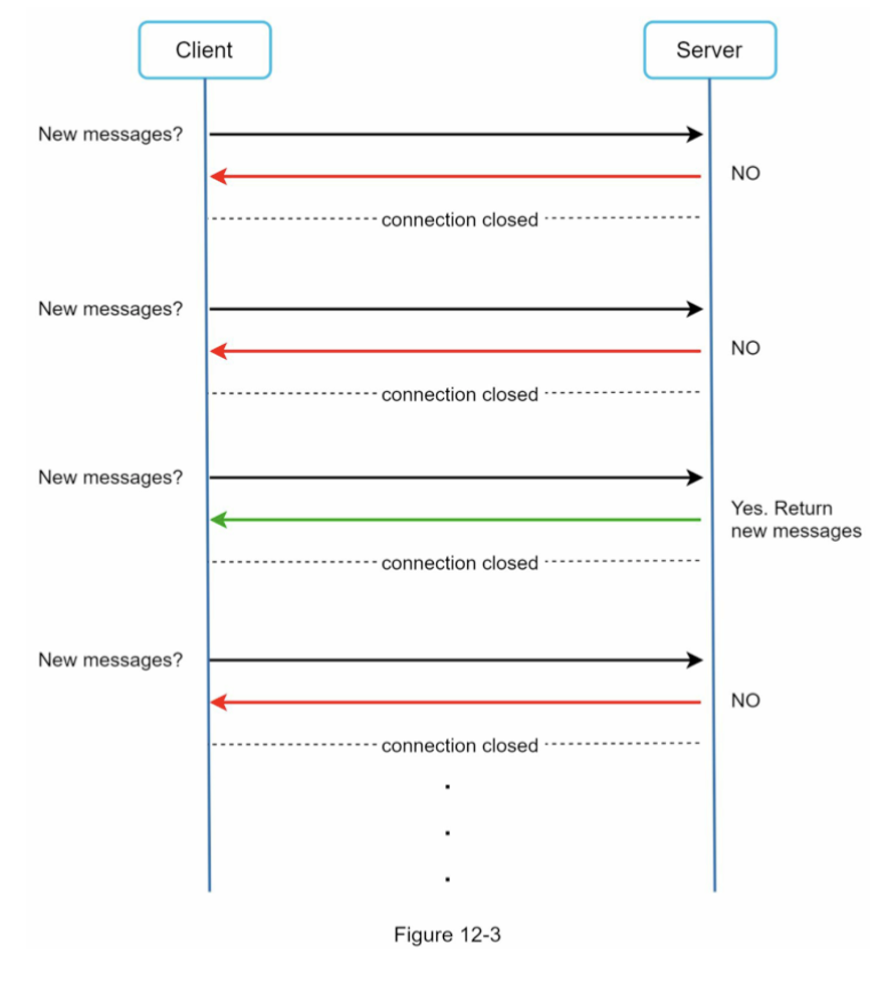
Polling
주기적으로 서버에게 메시지가 있는지 물어보는 방법. 자주하면 비용이 커지고 주기가 커지면 실시간성이 떨어지는 문제가 있음.
-
Long Polling
클라이언트는 새 메시지가 반환되거나 타임아웃 될 때까지 연결을 유지함. 새 메시지를 받으면 연결을 종료하고 서버에 새로운 요청을 보내어 새로운 연결을 맺음.
약점
- 송신 클라이언트와 수신 클라이언트가 같은 서버에 접속하지 못하는 문제가 발생할 수 있다.
- 서버가 클라이언트가 연결되어 있는지 확인할 방법이 없고 메시지를 받지 않는 클라이언트들도 타임아웃이 발생할 때마다 서버에 재접속을 하므로 비효율적이다.
-
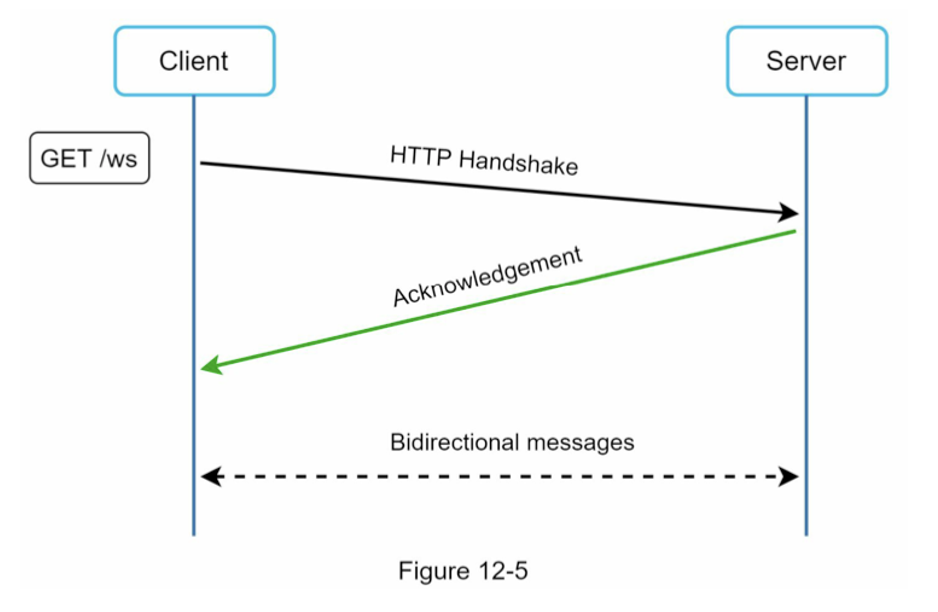
WebSocket서버가 클라이언트에게 비동기 메시지를 보낼 때 사용하는 기술.
특징
- 연결은 지속되고 양방향으로 통신이 가능하다.
- HTTP 연결을 맺고 이후 웹소켓으로 업그레이드된다.
- 하지만 연결이 지속되므로 연결 풀 관리를 잘 해야 한다. (stackoverflow에서 max 값이 어느정도인지 알아내려고 했는데 시스템마다 다른 것 같다. 1400~1800인 사람도 있었고 어떤 사람은 8000정도인 벤치마크 값을 보였다고 합니다)
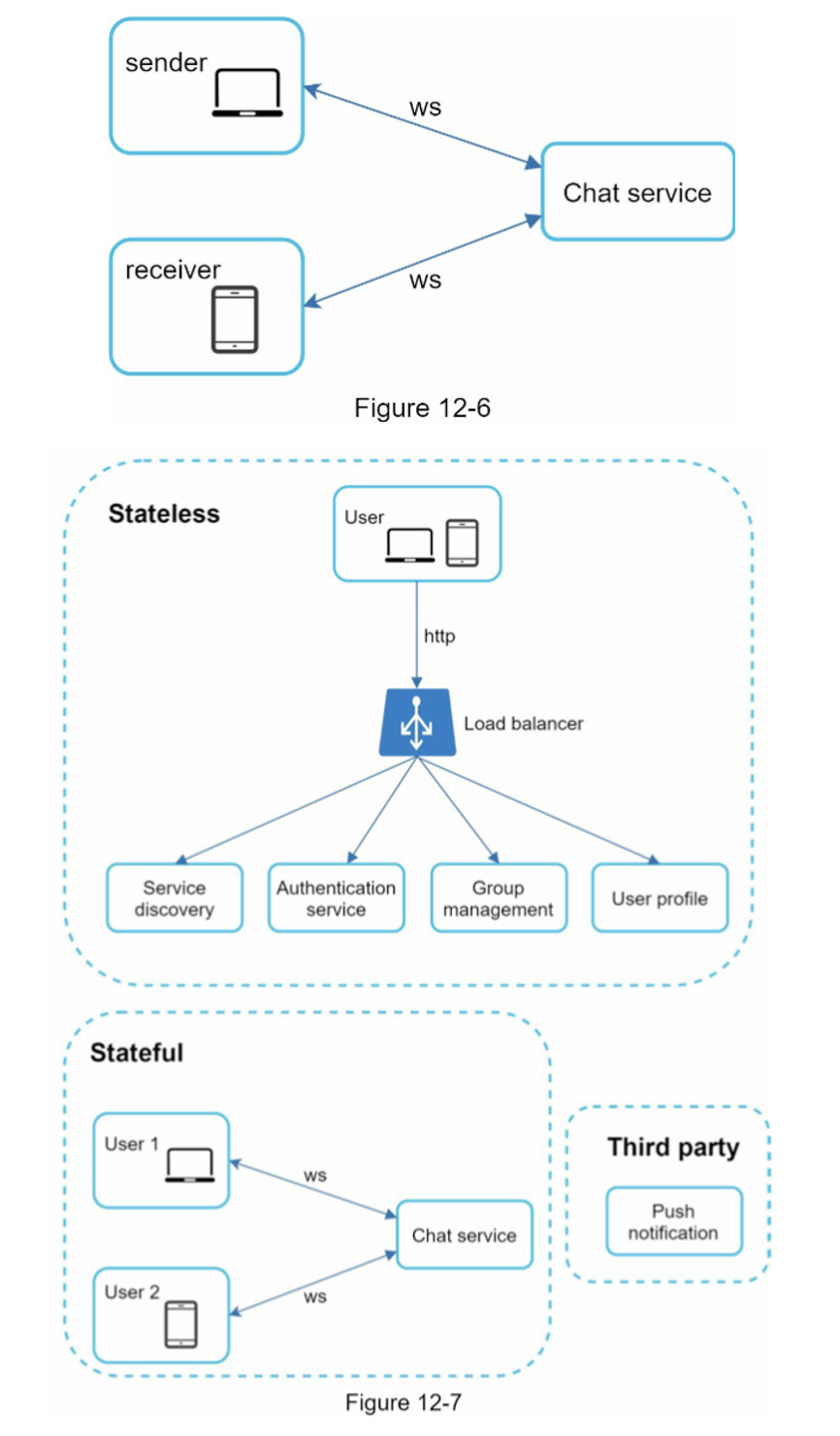
당연히, 채팅을 제외한 다른 서비스 (인증, 프로필 등)들은 웹소켓이 아니라 일반 HTTP 서비스로 구현해도 된다.
여기서 채팅 서비스가 stateful 서비스이고 로그인, 회원가입, 프로필 등의 서비스들은 stateless(무상태) 서비스들이다.
왜 그럼 채팅 서비스는 stateful이라고 할까?
각 클라이언트와 채팅 서버가 독립적인 네트워크 연결을 유지해야 하기 때문이다. 클라이언트는 보통 서비스를 제공하는 서버를 변경하지 않는데 채팅 서버 같은 경우에는 부하가 몰리지 않도록 여러 서버로 분산될 수 있는 것이다.
Scalability(규모 확장성)
- 동시 접속자가 몇인지?
- SPOF(Single Point-Of Failure), 단일 지점 실패
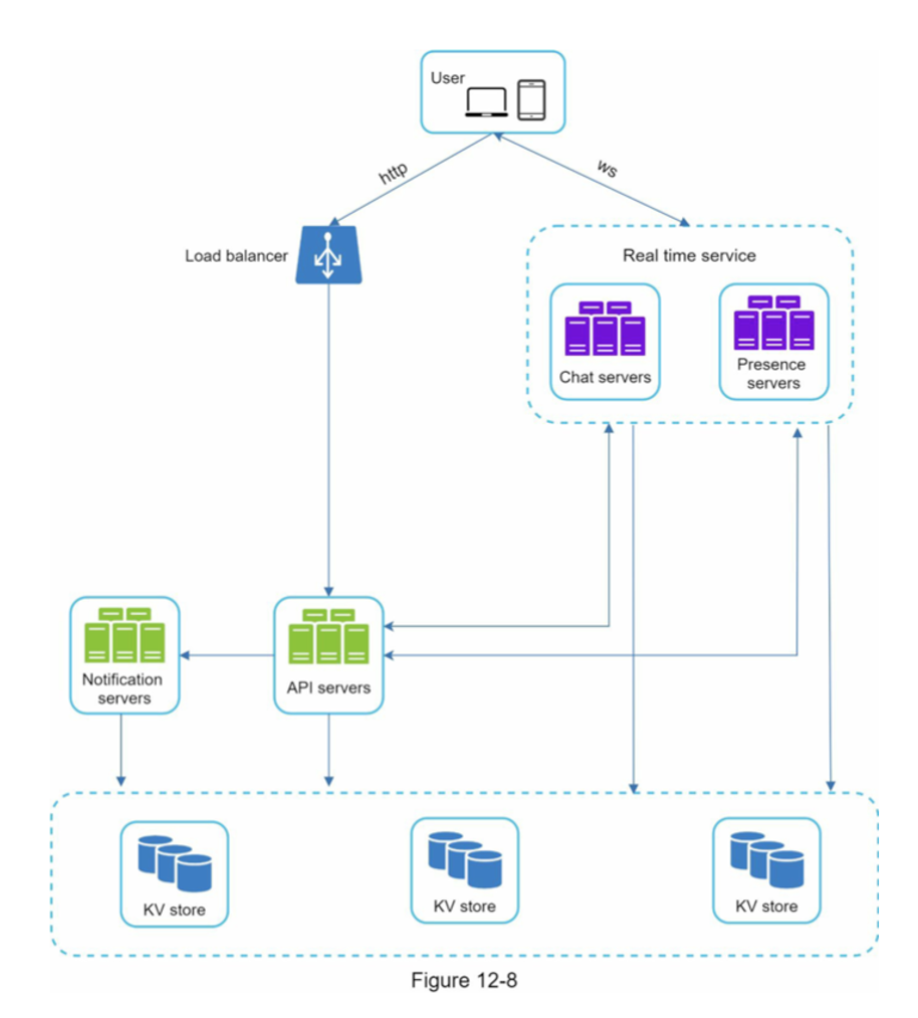
저장소
어떤 저장소를 사용할 것인지?
- 중요한 부분은 데이터의 유형과 읽기/쓰기 연산의 패턴이다.
데이터의 유형은 어떤 것이 존재할까?
-
사용자 프로필, 설정, 친구 목록과 같은 일반적인 데이터 → 안정성을 위해 RDB에 저장
- 다중화(Replication), 샤딩(Sharding)
-
채팅 이력 데이터
- 데이터의 양이 많다.
- 접근 빈도는 최근의 주고 받은 메시지가 더 높다.
- 하지만 검색 기능을 통해 과거에 주고 받은 채팅 데이터를 검색하는 일도 있다.
- 1:1 채팅 읽기, 쓰기 비율은 1:1 정도이다.
→ 책에서는 key-value 저장소를 추천하는데 그 이유는 수평적 규모확장이 쉽다.
Key-Value 저장소의 특징
- latency가 낮음
- (롱테일, 파레토) 법칙에 근거한 데이터를 잘 처리하지 못하는 경향이 있다. 인덱스가 커지면 검색 시간이 증가한다.

왼쪽은 1:1 채팅을 지원하는 테이블이고 오른쪽은 그룹 채팅방의 테이블 설계이다.
created_at으로 채팅의 순서를 정하지 못하고 message_id로 채팅의 순서를 정할 수 있다. (동시 생성 가능성)
Message ID
메시지가 전송된 순서에 따라 메시지 아이디가 부여되어야 한다. RDB는 auto_increment로 처리할 수 있지만 NoSQL에서는 해당 기능을 제공하지 않으므로 다른 방법을 찾아보아야 한다.
- 스노플레이크 : Global 64-bit sequence number generator
LINE 앱 ID Generator (snowflake)
- 지역적 순서 번호 생성기
서비스 탐색
클라이언트에게 가장 적합한 채팅 서버를 추천해주는 것.
사용자의 위치와 서버의 용량 등을 기준으로 추천을 해주게 된다.
메시지 흐름
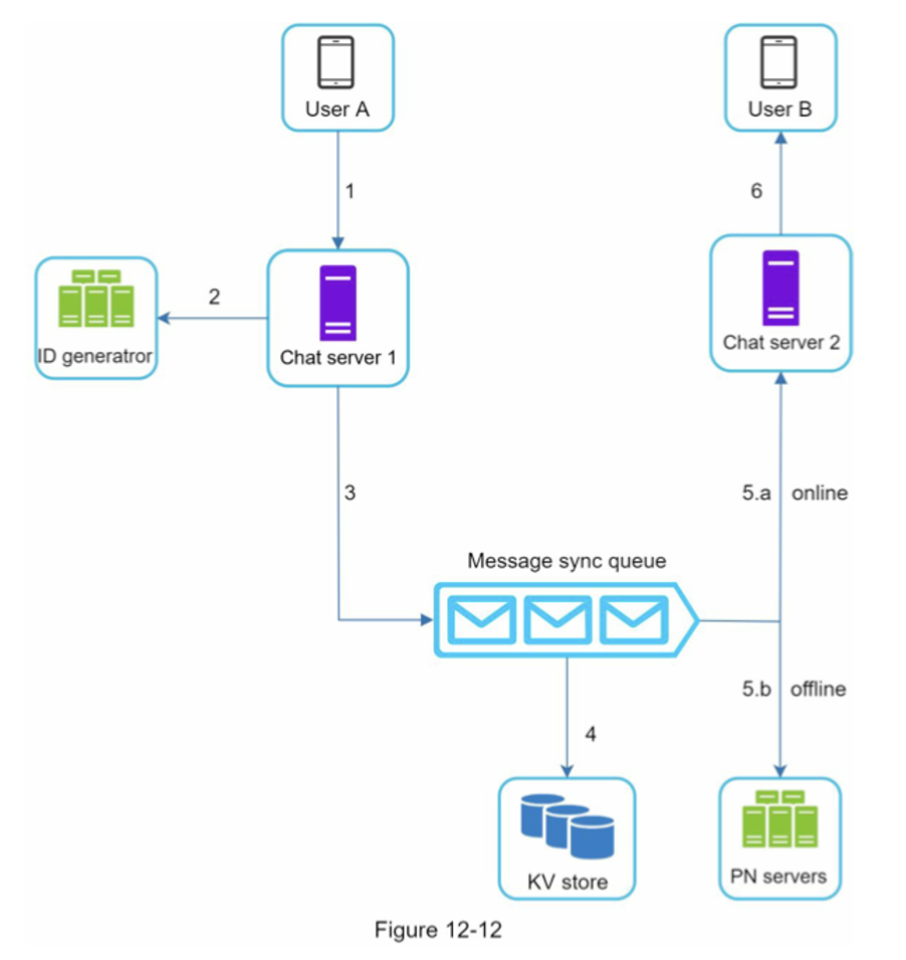
- 순서
-
사용자 A가 채팅 서버 1로 메시지 전송
-
채팅 서버 1은 ID 생성기를 사용해 해당 메시지의 ID 결정
-
채팅 서버 1은 해당 메시지를 메시지 동기화 큐(MQ)로 전송
-
메시지가 키-값 저장소에 보관됨
5-a. 사용자 B가 접속 중인 경우 메시지는 사용자 B가 접속 중인 채팅 서버로 전송됨
5-b. 사용자 B가 접속 중이 아니라면 푸시 알림 메시지를 푸시 서버로 보냄
-
채팅 서버 2는 유저 B에게 메시지를 전송. 웹소켓이 열려 있어서 그것을 이용.
-
메시지 동기화
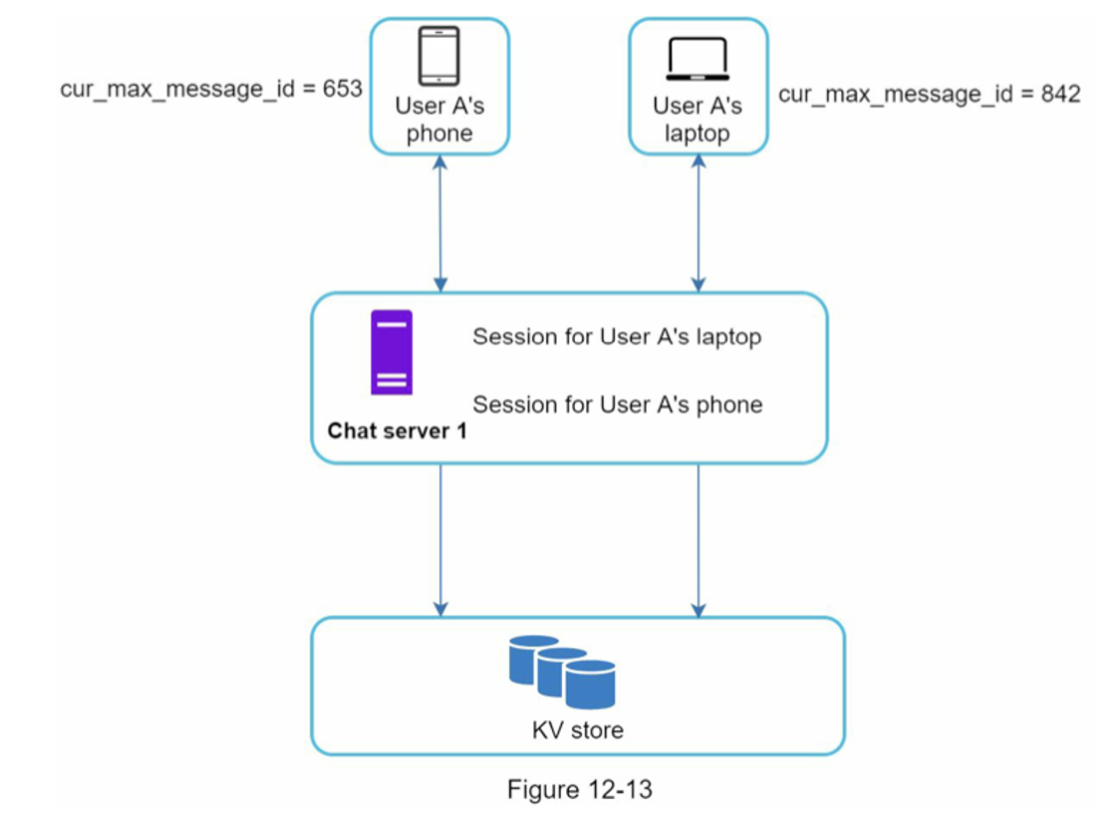
cur_max_message_id를 관리하여 가장 최신 메시지를 추적한다. 이는 단말마다 별도로 저장되면 된다.
소규모 그룹 채팅에서는 채팅 서버가 각 단말마다의 메시지 큐를 할당하여 각 메시지 큐에 메시지를 보내면 된다. 하지만 이는 굉장히 바람직하지 않은데 메시지를 수신자별로 복사하여 각 메시지 큐에 넣어줘야 함은 물론이고 Scalability가 떨어진다.
접속 상태 표시
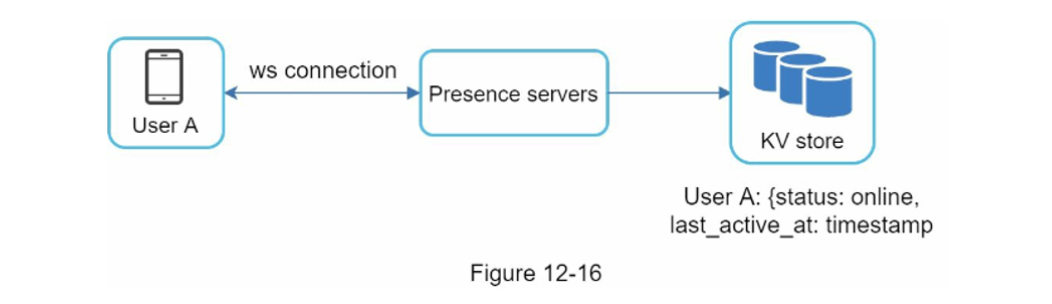
-
사용자 로그인
last_active_at이라는 타임스탬프를 Key-Value 저장소에 보관하며 이 절차 후에 접속 상태로 표시될 것이다.
-
로그아웃
Key-Value 저장소의 상태를 오프라인으로 변경하여 로그아웃 상태를 표시한다.
-
접속 장애
사용자의 인터넷이 잠시 끊겼을 때 사용자의 상태가 오프라인으로 표시되는 것이 바람직하지 않은데 이런 상황은 굉장히 빈번하게 발생하기 때문이다. 그렇기에 바로 오프라인으로 변경하는 방법이 아니라 헬스체크 방식을 통해 이 문제를 해결할 수 있을 것이다.
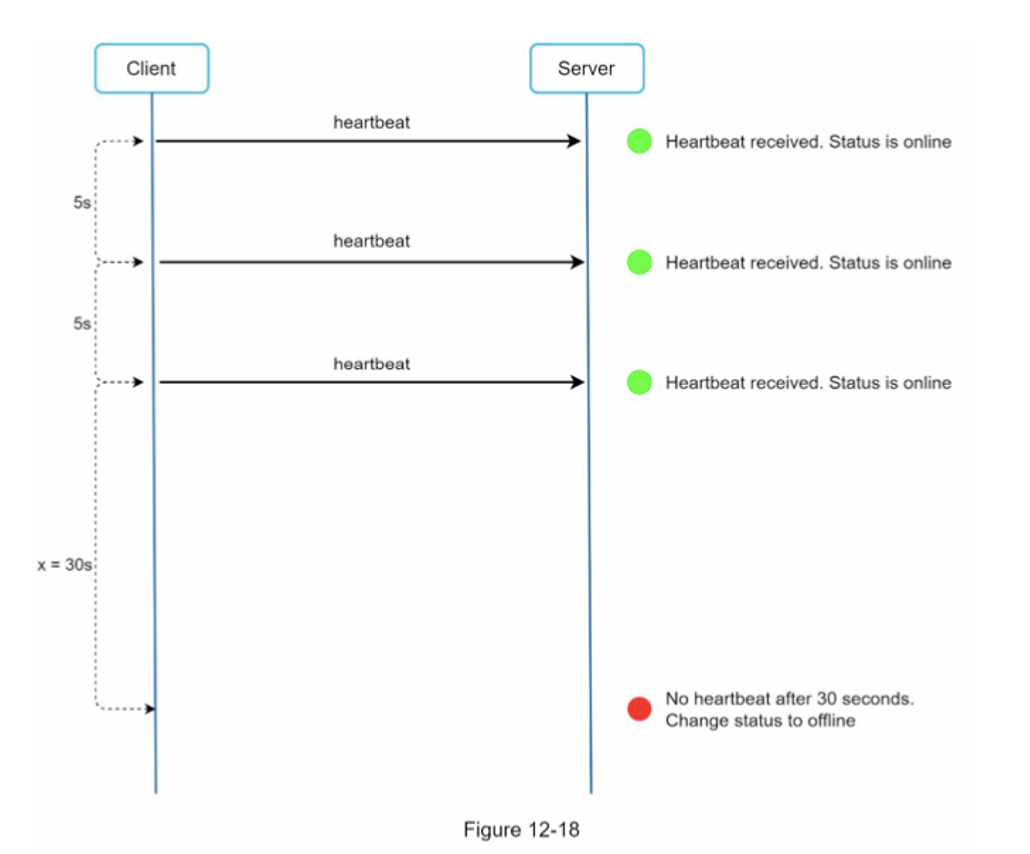
-
상태 정보의 전송
상태정보 서버는 발행-구독 모델을 사용하여 친구관계마다 채널을 하나씩 두는 것이다. 이렇게 하면 친구 관계에 있는 사용자가 상태정보 변화를 쉽게 감지할 수 있다. 여기서도 웹소켓을 사용한다.
하지만
그룹 크기가 커지게 되면예를 들어, 10만 사용자가 있는 그룹이라면 1개의 상태 변경에도 10만개의 이벤트 메시지를 생성해야 한다. 이에 대한 대처 방안으로는 갱신을 수동으로 한다던지의 방식이 존재한다.
논의해보면 좋은 사항
- 채팅을 통해 미디어를 제공하는 방법: 압축 방식, 클라우드 저장소, 썸네일 생성 등
- 종단 간 암호화: 메시지에 참여하는 사람 외에 메시지를 훔쳐볼 수 없는 것.
About end-to-end encryption | WhatsApp Help Center
- 카카오톡 비밀채팅방 공개 키는 비밀 메시지의 암호화에 사용되는 비밀 키를 교환할 때 사용하는 키 입니다. 비밀 채팅에서 사용하는 키는 공개 키(Public Key), 개인 키(Private Key) 그리고 비밀 키(Secret Key)의 총 3가지 입니다. 우선 비밀 키는 비밀 채팅방의 메시지를 암호화하는데 사용되는 키이며 비밀 채팅을 시작할 때 대화 쌍방이 서로 비밀 키를 교환해야 합니다. 이 때 비밀 키를 다시 암호화하여 교환하는데, 비밀 키를 암호화 할 때는 공개 키를 사용하고 이를 복호화 할 때는 개인 키를 사용합니다. 공개 키는 개인 키, 비밀 키와는 달리 말 그대로 외부에 공개되는 키 입니다. 이 공개 키를 이용하여 상대방을 신뢰할 수 있는지 확인할 수 있습니다. '채팅방 우측 메뉴 > 채팅방 설정 > 공개 키' 화면에 보이는 이미지는 대화 참여자들의 공개 키를 시각화하여 비교하기 쉽게 만든 그림입니다.
서로에게 보이는 이미지가 같다면 해당 채팅방을 신뢰할 수 있다는 의미입니다.
- 오류 처리: 장애 발생 시 서버를 전환하는 등의 처리. 메시지 재전송
메시지 큐 (MQ)
메시지 큐는 메시지 지향 미들웨어를 구현한 시스템이다.
메시지 지향 미들웨어(MOM)
응용 소프트웨어 간의 데이터(비동기 메시지) 통신을 위한 소프트웨어
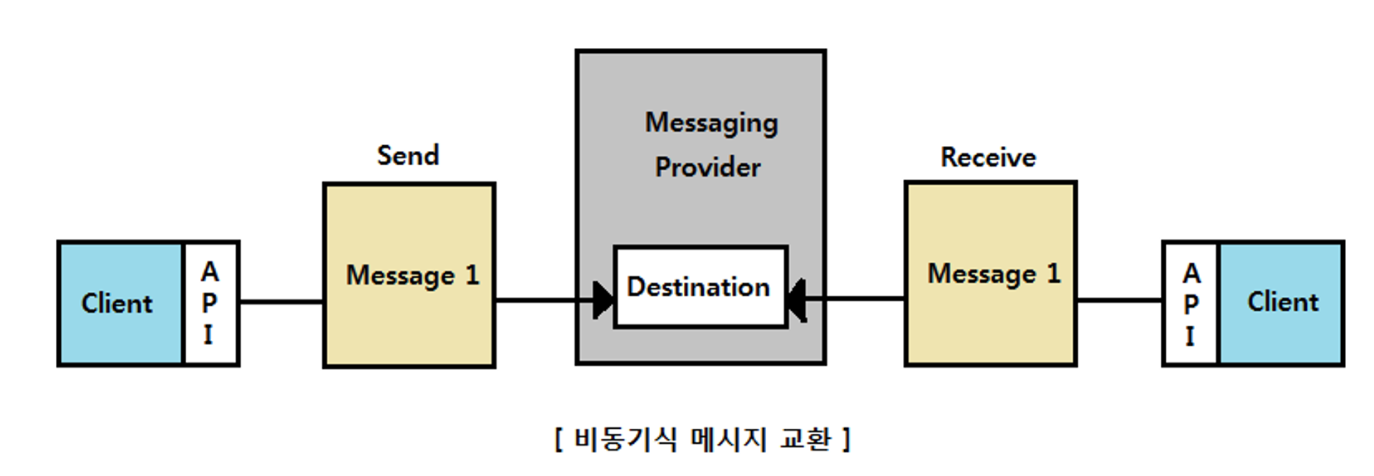
MOM은 메시지를 전달하는 과정에서 메시지를 보관하거나 라우팅 및 변환할 수 있다는 장점을 가진다.
- 보관 : 메시지의 백업을 유지함으로써 지속성을 제공, 송수신 측은 동시에 네트워크 연결을 유지할 필요가 없음
- 라우팅 : 미들웨어 계층에서 직접 메시지 라우팅이 가능하기 때문에 하나의 메시지를 여러 수신자에게 배포가 가능해짐. (멀티 캐스트)
- 변환 : 송수신 측의 요구에 따라 메시지를 변환할 수 있음.
단점
- 아키텍처에 외부 구성 요소인 메시지 전송 에이전트가 필요, 일반적으로 새로운 요소를 추가할 경우 시스템 성능이 저하되고, 신뢰성이 떨어짐
- 시스템이 복잡해지기 때문에 신뢰성이 떨어짐
- 애플리케이션 간의 통신은 본질적으로 동기지만, 메시지 기반 통신은 본질적으로 비동기이기 때문에 메커니즘 불일치가 발생
- 이를 위해 요청을 그룹화하여 하나의 의사 동기 트랜잭션으로 응답하는 기능을 가졌음
- 표준 규격이 존재하지 않기에 호환의 문제가 있을 수도 있음
메시지 큐(Message Queue)
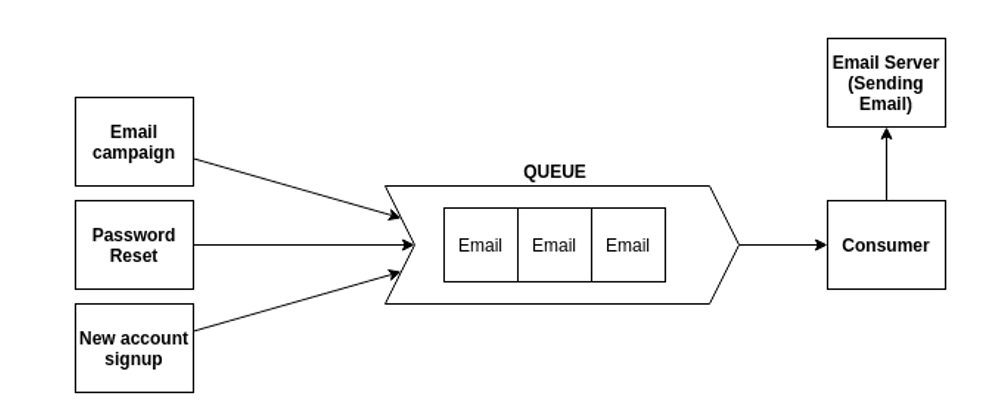
메시지 큐 사용의 장점
- 비동기(Asynchronous) : 데이터를 수신자에게 바로 보내지 않고 큐에 넣고 관리하기 때문에 처리 가능할 때 처리 가능
- 비동조(Decoupling) : 애플리케이션과 분리할 수 있기 때문에 확장이 용이해짐
- 탄력성(Resilience) : 일부가 실패하더라도 전체에 영향을 주지 않음
- 과잉(Redundancy) : 실패할 경우 재실행 가능
- 보증(Guarantees) : 작업이 처리된 걸 확인할 수 있음
- 확장성(Scalability) : N:1:M의 구조로 다수의 프로세스들이 큐에 메시지를 보낼 수 있음.
이런 장점들 덕분에 다양한 곳에서 사용이 된다.
- 다른 곳의 API로부터 데이터를 송수신 가능
- 다양한 애플리케이션에서 비동기 통신 가능
- 이메일 발송 및 문서 업로드 가능
- 많은 양의 프로세스들을 처리 가능
그럼 메시지 큐들의 특징을 알아보자.
RabbitMQ
- AMQP 프로토콜을 구현해 놓은 메시지 큐
- 여기서 AMQP 프로토콜이란? [AMQP] AMQP(Advanced Message Queuing Protocol)
- 여기서 AMQP 프로토콜이란? [AMQP] AMQP(Advanced Message Queuing Protocol)
- 유연한 라우팅 : 메시지 큐가 도착하기 전에 라우팅되며 플러그인을 통해 더 복잡한 라우팅도 가능
- 클러스터링 : 로컬 네트워크에 있는 여러 RabbitMQ 서버를 논리적으로 클러스터링할 수 있고 논리적인 브로커도 가능
- 관리 UI가 있어서 편하게 관리 가능
- 거의 모든 언어와 운영체제를 지원
Kafka
- 대용량의 실시간 로그 처리에 특화되어 설계된 메시징 시스템
- AMQP 프로토콜이나 JMS API를 사용하지 않고 단순한 메시지 헤더를 지닌 TCP 기반의 프로토콜을 사용하여 프로토콜에 의한 오버헤드를 감소시킴
- Producer가 Broker에게 다수의 메시지를 전송할 때 각 메시지를 개별적으로 전송해야 하는 기본 메시징 시스템과 달리, 다수의 메시지를 Batch 형태로 Broker에게 전달 가능하여 TCP/IP Trip 횟수를 줄일 수 있음.
- 메시지를 파일 시스템에 저장하기 때문에 영속성 보장 가능
- 기존 메시징 시스템은 큐에 적재된 양에 따라 성능이 크게 감소하는 문제가 있었지만 Kafka는 파일 시스템에 저장하므로 성능 감소가 크게 존재하지 않음
- Consumer에 의해 처리된 메시지를 곧바로 삭제하는 시스템과 달리 바로 삭제하지 않고 파일 시스템에서 수명이 지나면 삭제하도록 처리
- 기존의 메시징 시스템은 Broker가 Consumer에게 Push 해주는 방식인 반면 Kafka는 Consumer가 Broker로부터 직접 메시지를 가지고 가는 Pull 방식
- 즉, 대용량 처리를 위해 메시지 큐의 여러 특징을 뺀 느낌
Kafka 예제
build.gradle 의존성 추가
implementation 'org.springframework.kafka:spring-kafka'application.yml에 kafka 설정
spring:
kafka:
bootstrap-servers:
- 192.168.0.4:9092
consumer:
# consumer bootstrap servers가 따로 존재하면 설정
# bootstrap-servers: 192.168.0.4:9092
# 식별 가능한 Consumer Group Id
group-id: testgroup
# Kafka 서버에 초기 offset이 없거나, 서버에 현재 offset이 더 이상 존재하지 않을 경우 수행할 작업을 설정
# latest: 가장 최근에 생산된 메시지로 offeset reset
# earliest: 가장 오래된 메시지로 offeset reset
# none: offset 정보가 없으면 Exception 발생
auto-offset-reset: earliest
# 데이터를 받아올 때, key/value를 역직렬화
# JSON 데이터를 받아올 것이라면 JsonDeserializer
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
# producer bootstrap servers가 따로 존재하면 설정
# bootstrap-servers: 3.34.97.97:9092
# 데이터를 보낼 때, key/value를 직렬화
# JSON 데이터를 보낼 것이라면 JsonSerializer
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializerKafka Producer class
KafkaTemplate에 Topic명과 메시지를 전달한다. kafkaTemplate.send() 메소드가 실행되면 Kafka 서버로 메시지가 전송된다.
@Service
public class KafkaProducer {
@Value(value = "${message.topic.name}")
private String topicName;
private final KafkaTemplate<String, String> kafkaTemplate;
@Autowired
public KafkaProducer(KafkaTemplate kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
public void sendMessage(String message) {
System.out.println(String.format("Produce message : %s", message));
this.kafkaTemplate.send(topicName, message);
}
}Kafka Consumer class
Kafka로부터 메시지를 받으려면 @KafkaListener 어노테이션을 달아주면 된다.
@Service
public class KafkaConsumer {
@KafkaListener(topics = "${message.topic.name}", groupId = ConsumerConfig.GROUP_ID_CONFIG)
public void consume(String message) throws IOException {
System.out.println(String.format("Consumed message : %s", message));
}
}Controller
@Slf4j
@RestController
@RequestMapping(value = "/kafka/test")
public class SampleController {
private final KafkaProducer producer;
@Autowired
SampleController(KafkaProducer producer) {
this.producer = producer;
}
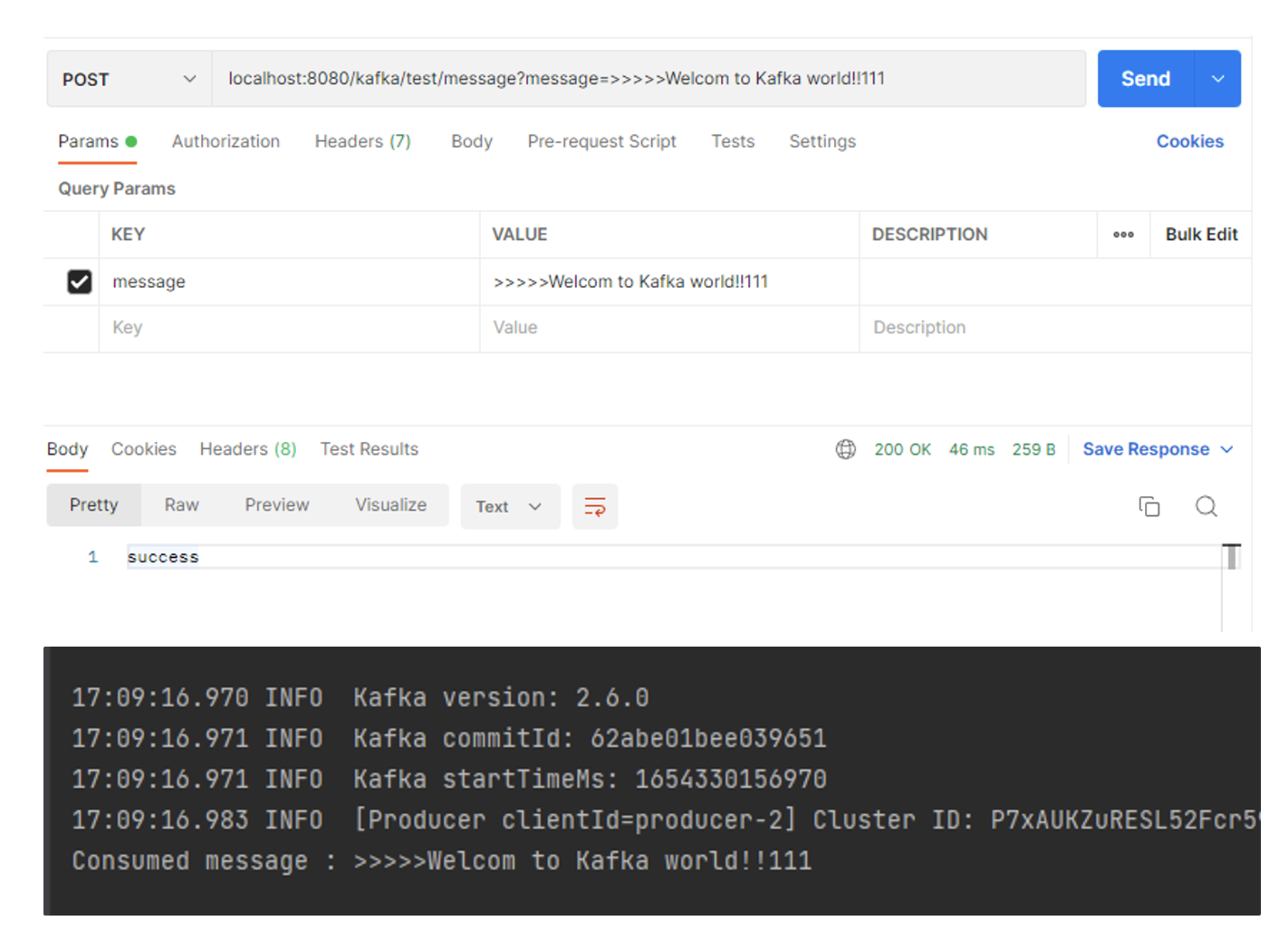
@PostMapping(value = "/message")
public String sendMessage(@RequestParam("message") String message) {
this.producer.sendMessage(message);
return "success";
}
}그럼 MQ를 동기적 모놀리식 시스템에서 사용하면 어떻게 될까?
물론 장점이 있다.
- 분산 시스템 통합: 대규모 시스템이 여러 컴포넌트로 구성되어 있을 때, MQ를 사용하면 컴포넌트 간 통신을 표준화하고 단순화할 수 있습니다. 이로써 시스템의 복잡성을 관리하고, 장애 복구 및 확장성을 향상시킬 수 있다.
- 메시지 버퍼링: 메시지를 받는 컴포넌트는 메시지를 처리하지 않고 큐에 넣을 수 있으며, 이후 메시지를 처리할 때 컴포넌트의 부하가 너무 많이 증가하지 않도록 할 수 있다.
- 통신 품질 향상: MQ를 사용하면 메시지의 안정성과 신뢰성을 향상시킬 수 있다. 메시지는 대부분의 MQ 시스템에서 지속적으로 저장되며, 이로써 데이터 손실을 방지하고 메시지 전달을 보장할 수 있다.
- 비즈니스 프로세스 흐름 제어: 비동기 시스템과 비즈니스 프로세스 간 상호 작용을 제어하기 위해 MQ를 사용할 수 있다. 특정 이벤트 발생 시 MQ를 통해 관련 데이터를 전달하고, 이를 처리하면서 비즈니스 프로세스를 효과적으로 제어할 수 있다.
하지만 MQ를 동기적 모놀리식 시스템에서 사용할 때 주의할 점은 성능 및 복잡성을 고려해야 한다는 점이다. 비동기 통신은 대규모 분산 시스템에서 효과적으로 사용될 수 있지만 작은 규모의 단일 서비스에서 MQ를 사용하게 되면 오버헤드를 초래할 수 있다.
