
🐳 220926 월 TIL < EDA > 🐳
- 실습파일 05
- 실습파일 06
- 실습파일 07 조금
파이썬은 접착제 언어, 아나콘다 추천
ctrl(cmd)+/ => 주석 처리 실행과 취소
EDA란?
탐색적 데이터 분석 (데이터 타입, 유니크 값, 결측치…)
<오늘의 학습 목표>
-
추상화 도구(기본적으로 봐야하는 기술통계 값들 한번에 확인 가능하다는 엄청난 기능! 리포트로 저장)를 통해서 기술통계를 한번에 구해본다
-
하나하나 구해본다 (범주형, 수치형)
-
수치형, 범주형 데이터 각각 목적에 따라 그래프 선택할 줄 알아야 함
-
수치형 변수) 히스토그램
-
범주형 변수) 카운트 프로스 (빈도)
-
개별 변수값… 회귀선… 그래프 해석에 집중
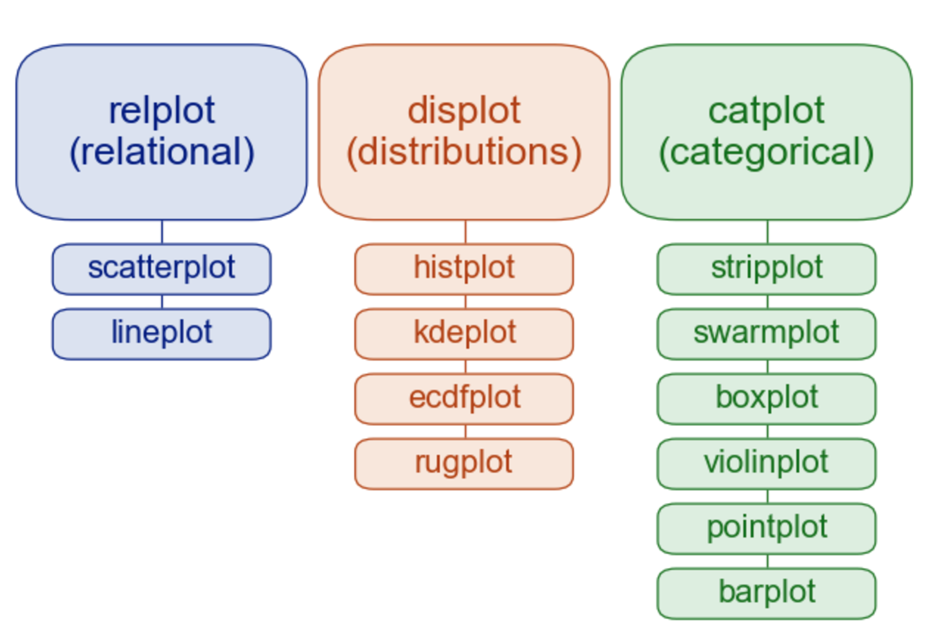
요것이 계속 안고 가야 하는 그림!
- 그러나 lmplot, regplot 빠져있음
# 오늘의 라이브러리
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns# 버전 업그레이드
!pip install seaborn –upgrade유의) 런타임 – 다시 시작 : 해주어야 업그레이드 된 것이 적용됨
(이전에 캐시에 남아있는 것이 불러와지기 때문)
# 버전 확인
.__version__
# 임의로 한 행 뽑기
.sample()# 버전 호환성 때문에 오류가 많이 발생하기 때문에, 유의해주어야 한다
!pip install pandas-profiling==3.1.0
# -> 특정 버전으로 지정해서 설치하는 법
# 추상화된 도구 디테일하게 외울 필요는 x, 문서를 보고 사용할 수 있도록
from pandas_profiling import ProfileReport
profile = ProfileReport(df, title="Pandas Profiling Report MPG")
# 프로파일 리포트 생성 후 파일로도 생성
profile.to_file("pandas_profile_report.html")Pandas Profiling Report MPG
판다스 프로파일링 깃허브
https://github.com/ydataai/pandas-profiling
mpg(수치형 데이터)의 기술통계 값들: 유일값, 결측치, 사분위수, 분산, 제로값, 평균…
cylinders(범주형 데이터)의 기술통계 값들: mpg과 다른 범주형 데이터
- extreme values? 최대/최소값
- acceleration/skewness/kurtosis
타이타닉 데이터셋
https://pandas-profiling.ydata.ai/examples/master/titanic/titanic_report.html
words: 많이 나오는 단어
characters: 많이 나오는 문자
interactions: 분포, 변수간의 상관관계 (짝을 지어서 선택해볼 수 있음)
- 범주형 데이터는 존재 x
correaltions: 스피어만의 상관계수, 피어슨의 상관계수, 켄달…
overview: 결측치, 중복값…
alerts
reproductive
variables: 변수마다 확인
toggle details
=> 리포트에 다양한 확인할 수 있는 사항들이 있다
SweetVIZ
예측해야 할 데이터셋(ex. 생존여부)에 따라 데이터가 어떻게 변하는지 보고 싶을 때
- association: 상관관계 히트맵 볼 수 있음
- 오픈 소스로 이런 리포트 만들기 플젝도 해볼 수 있음
AutoVIZ
오토비즈 깃허브
https://github.com/AutoViML/AutoViz
- bokeh 라이브러리 사용
- interactive한 시각화: x = 범주형 데이터 y = 수치형 데이터
ex. bar plot, violin plot, displot(분포), heatmap, scatter plot(개별 관측치 값)
- 수치형 – 수치형 비교는 바그래프보다 산점도가 더 적절
추상화된 도구의 단점이 있다면?
- 대용량 데이터에 사용할 수 없음: 오래 걸린다
- 세부 컨트롤이 불가 (다른 옵션)
- 어떤 데이터가 missing되었는지 알 수 없음
다양한 데이터프레임 함수
df.info() : 요약하기
df.isnull() : 결측치 찾기
df.isnull().sum : 결측치 합
df.isnull().mean : 결측치 비율
@ 유의사항!
df.count() : 결측치 제외하고 계산
len(df), df.shape[0] : 결측치 포함하여 계산
figsize=( , )
# 히트맵 그리기 plt.figure(figsize=(12, 8)) sns.heatmap(df.isnull(), cmap="gray")
- 출력되는 그래프의 사이즈를 지정하는 코드 옵션
시각화 그래프의 기본 크기 : (6.4, 4.8)
- 값들을 변경하면서 크기가 얼마나 변경하는지 확인해보면, 특정 상황에서는 이 정도 값을 사용하는게 좋겠다! 라는 직관이 생기는데 도움이 됨
tip: 외우겠다는 부담 보다는 다른 예제에 최대한 많이 적용해보면서 늘게 됨
cmap == colormap
컬러맵 사이트
https://matplotlib.org/stable/tutorials/colors/colormaps.html
plt.colormaps? : .colormaps()의 도움말 확인 가능 ; 컬러명칭 또한 알 수 있음sns.heatmap(df.isnull(), cmap="Greys_r")
다양한 함수
# 수치형 변수의 기술통계값 구하기 df.describe() # describe의 기본인 수치형이 아닌 범주형 변수 기술통계값 구하기 df.describe(include=”object”) # 유일값 개수 구하기 df.nuniqie
kde = False, kde = True : kde 온오프의 개념
kde : 관측치에 대한 분포를 시각화 ; 히스토그램의 밀도 시각화
A kernel density estimate (KDE) plot is a method for visualizing the
distribution of observations in a dataset, analagous to a histogram. KDE
represents the data using a continuous probability density curve in one or
more dimensions.
The approach is explained further in the :ref:user guide <tutorial_kde>.
Relative to a histogram, KDE can produce a plot that is less cluttered and
more interpretable, especially when drawing multiple distributions. But it
has the potential to introduce distortions if the underlying distribution is
bounded or not smooth. Like a histogram, the quality of the representation
also depends on the selection of good smoothing parameters.
hue : 범주형 변수에 대해 다른 그룹/차원으로
plot 안에 ex. hue="origin" 옵션으로 추가origin(usa, japan, europe)의 값에 따라 다른 색상으로 그리기
다시 한번 등장! 외워두자
Q. plot마다 y축 값 다른가?
hist => 빈도, kde=> 밀도 == 적분했을 때 1이 되는 값
기본적으로는, 보통 그래프를 그려보는 건 분포 정도 보려고 하는 것!
스케일링
- standard scaling = 평균 0 , 편차 1
: 값의 수치와 범위가 다른 값을 비슷한 값을 갖도록 만들어주는 것, 즉 평균이 0이고 편차가 1이 되게 만들어주는 것- min-max scaling = 최솟값을 0, 최댓값을 1
어떤 변수는 10의 자리대 어떤 변수는 100의 자리대, 1000의 자리대 변수로 절대적인 수치의 차이가 난다. 따라서 스케일링으로 이 절대적인 수치의 차이를 통일시켜주는 것이다.
std: 스탠다드 데비에이션 = 표준편차
정규화 공식 중 하나: ( 관측치 – 평균 ) / 표준편차
회귀선 자료
히스토그램 그리기
df.hist(figsize=(12, 10), bins=50) plt.show
비대칭도(왜도)
https://ko.wikipedia.org/wiki/%EB%B9%84%EB%8C%80%EC%B9%AD%EB%8F%84
분포의 비대칭성을 나타내는 지표
음수) 왼쪽 부분에 긴 꼬리 == 중앙값을 포함한 자료가 오른쪽에 더 많이 분포
양수) 오른쪽 부분에 긴 꼬리 == 중앙값을 포함한 자료가 왼쪽에 더 많이 분포
# 왜도 구하기
df.skew()첨도
확률분포의 뾰족한 정도를 나타내는 척도
관측치들이 어느 정도 집중적으로 중심에 몰려있는가
3을 기준으로 3보다 작으면 뾰족, 3보다 크면 완만, 3에 가까우면 정규분포에 가까워짐
# 첨도 구하기
df.kurt()시각화 그래프 종류 정리
# displot : 히스토그램 + kdeplot sns.displot(data=df, kde=True) sns.displot(data=df, x=”mpg”, kde=True) sns.displot(data=df, x="mpg", kde=True, hue="origin", col="origin", bins=50) # kedplot : 커널밀도함수 sns.kdeplot(data=df, x="mpg") # rugplot : 작은 선분 함수 sns.rugplot(data=df, x="mpg") # boxplot : 박스플롯 sns.boxplot(data=df, x=”mpg”) # violinplot : 바이올린플롯 sns.violinplot(data=df, x=”mpg”) # 두 개 이상의 수치변수 (x열, y열) sns.scatterplot(data=df, x="mpg", y="horsepower") # 회귀 시각화 # regplot: 산점도 + line plot sns.regplot(data=df, x="mpg", y="horsepower") # 잔차 시각화 sns.residplot(data=df, x="mpg", y="horsepower") # relplot : x, y 두 열을 지정해주고 데이터간 상관관계를 scatter 형식으로 출력 # lmplot : relplot에서 선형관계를 나타내는 선이 함께 출력 # (상관관계 모호한 경우, relplot보다 직관적) sns.lmplot(data=df, x="mpg", y="horsepower", hue="origin", col="origin") # jointplot : 두개의 수치변수의 scatter과 hist plot # (어떤 kind를 지정해주느냐에 따라 형태가 다양해짐) # pairplot : 모든 시리즈들 간의 상관관계를 한번에 보여주는 표 sns.pairplot(data=df.sample(100)) # ㄴ origin 값에 따라 다른 색상으로 그리기 sns.pairplot(data=df.sample(100), hue="origin") # lineplot : x, y 두 열을 지정해주고, 관계를 확인하는 선그래프 # 수치형 지표들 간의 경향 파악 sns.relplot(data=df, x="model_year", y="mpg", hue="origin", col="origin", kind="line", ci=None)
상관분석
두 변수 간 어떤 선형적/비선형적 관계를 갖고 있는지에 대한 분석
!= 인과관계
피어슨 상관계수: (-1<r<1)
# 상관계수 구하기
df.corr()
# 변수 할당
corr = df.corr()
corr
# 히트맵을 통한 상관계수 시각화
mask = np.triu(np.ones_like(corr))
mask
# heatmap 을 통해 상관계수를 시각화 합니다.
sns.heatmap(corr, cmap="coolwarm", annot=True, mask=mask)
기타
- shape: 메소드가 아니라 어트리뷰트라서 괄호를 안 붙임
- lmplot은 scatterplot과 regplot을 함께 표현해볼 수 있는 그래프로 범주형 변수에 따라 다른 색상과 서브플롯으로 그려볼 수 있는 시각화 기능을 제공
- seaborn 의 relplot은 수치 데이터의 관계를 표현하기 위한 그래프를 서브플롯으로 그려주는 역할을 함
- df[["cylinders", "model_year"]].astype(str).describe()
변수 여러개 보고 싶을 때 [[]] 요렇게 표현
회고
어렵다고 속상해 말자! 3주차인데 나약해빠진 놈!
큰 걸 보고 생각해라. 작은 것들에 매몰되다가는 큰 그림부터 놓치게 된다. 비효유우울. 큰 맥락을 잡아야 함.
