1. Introduction
Data Augmentation은 Classification의 성능을 높이는 데 있어서 매우 중요하다. 다양한 데이터를 학습함으로써 모델의 학습량을 늘리고, inductive bias를 줄일 수 있기 때문이다. 이번에 소개할 AutoAugment는 2018년 Google에서 나온 Data Augmentation 방법이다.
💡 Contribution
1. 강화학습(PPO)를 사용하여 최적의 augmentation 기법을 찾아낸다.
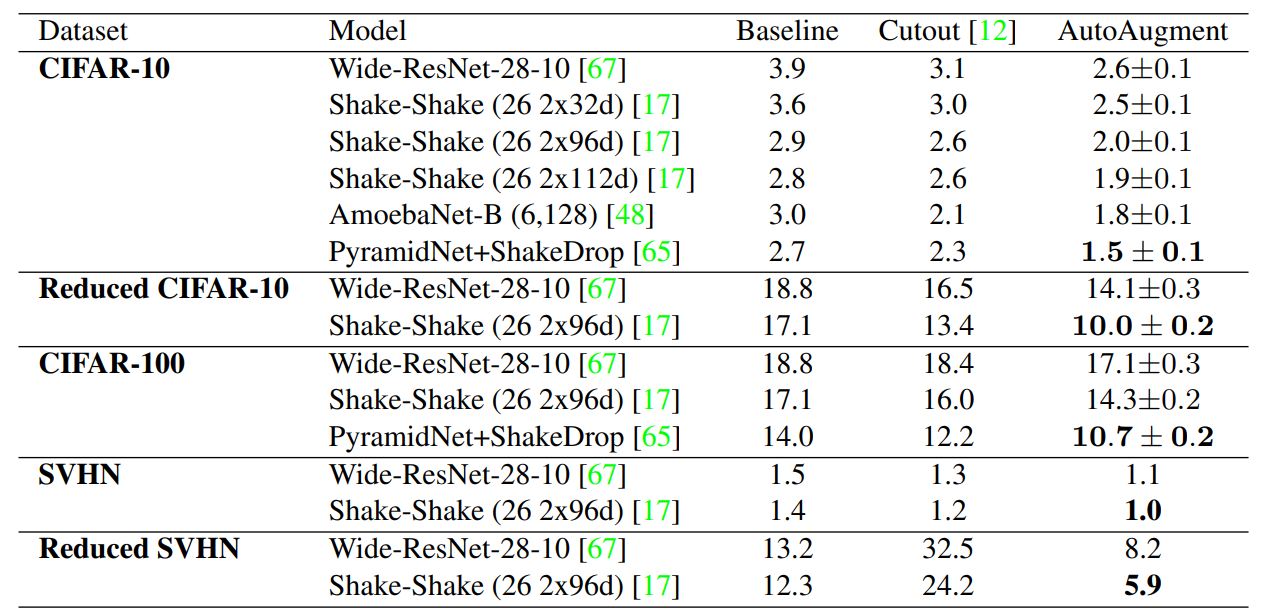
2. CIFAR-10, CIFAR-100, SVHN, ImageNet에서 SOTA의 성능을 0.6%p~1.5%p 향상시켰다.
3. 한 데이터 셋에서 얻어낸 최적의 augmentation 방법을 다른 데이터 셋에 전이하여 사용해도 좋은 성능을 기대할 수 있다.
2. Related works
2.1. Learned Augmentation
- Smart Augmentation : 같은 class인 여러 개의 sample을 결합하여 자동으로 augmented data를 생성해내는 network를 제안.
- Bayesian approach : 학습 데이터로부터 학습한 분포를 바탕으로 데이터를 생성해내는 방법.
- Feature space : 학습한 feature space에서 간단한 transformation을 통해 데이터를 증강하는 방법.
2.2 생성 모델
GAN과 같은 생성 모델은 implicit/explicit하게 학습한 데이터의 분포를 바탕으로 데이터를 직접 생성하지만, AutoAugment는 Rotation, Shear 등 symbolic transformation operations의 최적 조합을 통해 데이터 증강을 한다는 차이가 있다.
나는 현재 진행 중인 과제의 데이터가 GAN이나 DPM을 학습하여 사용하기에 현저히 부족하기 때문에 AutoAugment를 사용하려고 한다.
3. Method
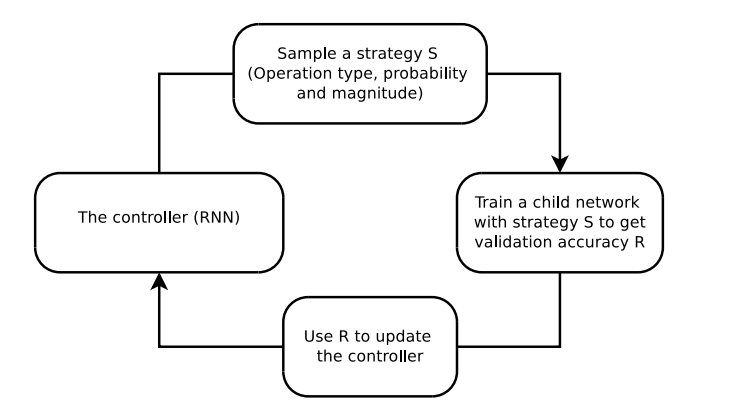
3.1. Search space detail
Augmentation을 위한 5개의 strategy를 찾는 과정을 나타낸 그림이다.
AutoAugment는 1) ShearX/Y, 3) TranslateX/Y, 5) Rotate, 6) AutoContrast, 7) Invert, 8) Equalize, 9) Solarize, 10) Posterize, 11) Contrast, 12) Color, 13) Brightness, 14) Sharpness, 15) Cutout, 16) Sample Pairing 까지 총 16개의 operation 후보군과 각각의 적용 정도로 10개의 이산 범위(uniform spacing), 사용 확률로 11개의 이산 범위(uniform spacing)를 가진다.
한 policy는 5개의 sub-policy를 가지며, 한 sub-policy는 2개의 operation을 연속으로 적용한다.

이렇게 sub-policy를 사용한 5가지의 증강 데이터를 사용하여 child network를 학습하고, 그 valid accuracy를 reward로 활용하여 이 policy를 평가한다. 때문에, 최적의 policy 탐색을 위한 Search Space는 가 된다.
3.2. Controller RNN
Controller RNN은 매 번 30개의 softmax prediction을 배출한다.
1 policy = 5 sub-polices = 10 operations = 10*(종류, 적용 정도, 사용 확률) = 30 predictions
Controlloer RNN은 1-layer LSTM이다. Child network의 validation accuracy를 reward로써 사용하는데, 방법은 이렇다. (보통 B=5)의 softmax prediction을 확률로써 사용한다. 이 들의 곱이 child network의 Joint Probability이며,이를 reward로 나눈 값을 controller의 weight을 update하는 데 사용한다. 따라서 좋은 reward가 나올 때에는 그 값이 클 것이므로 update가 덜 되고, 나쁜 reward가 나올 떄에는 그 값이 작을 것이므로 update가 더 많이 될 것이다.
4. Result
5. Code
