
올해 고2 3모 36번
올해 영어 지문에서 내가 원하는 알고리즘에 대한 설명이 담겨있었다.

무작위적인 변이의 반복적 생성이 비무작위적인 선택과 결합될 때 가능해지는 구조적 풍부함을 통해 인체가 발달한다
신체 형성은 무작위 활동에 의해 만들어진 새로운 가능성과 더불어, 이전에 확립된 기준을 만족시키는 결과물의 선택에 달려 있다
무작위적 선택
무작위적 선택이란 새로운 유전자를 무작위적으로 생성하는 과정을 의미한다. 이 과정에서 새로운 경우의 수를 얻어낼 수 있다.
비무작위적 선택
비무작위적 선택이란 무작위적이지 않은 이전에 확립된 기준에 부합하지 않는 유전자를 제거하는 경향을 보인다는 것이다.
교차 & 변이

교차는 기존의 두 유전자를 바탕으로 새로운 후대 유전자를 만들어내는 과정을 의미한다. 또한 기존의 유전자에서 확률적으로 유전 정보가 변하는데, 이걸 변이라고 부른다.
유전자 알고리즘
유전자 알고리즘은 위에서 설명한 유전자가 변화하는 과정을 이용한 존 홀랜드(John Holland)가 1975년에 저서 "Adaptation on Natural and Artificial Systems" 에서 처음 소개한 최적화 기법이다.
초기화 선택 교차 변이 대치 과정을 거쳐서 실제 생물 진화를 모방해서 문제를 해결하는 진화 연산의 대표적인 방법이라고 한다.
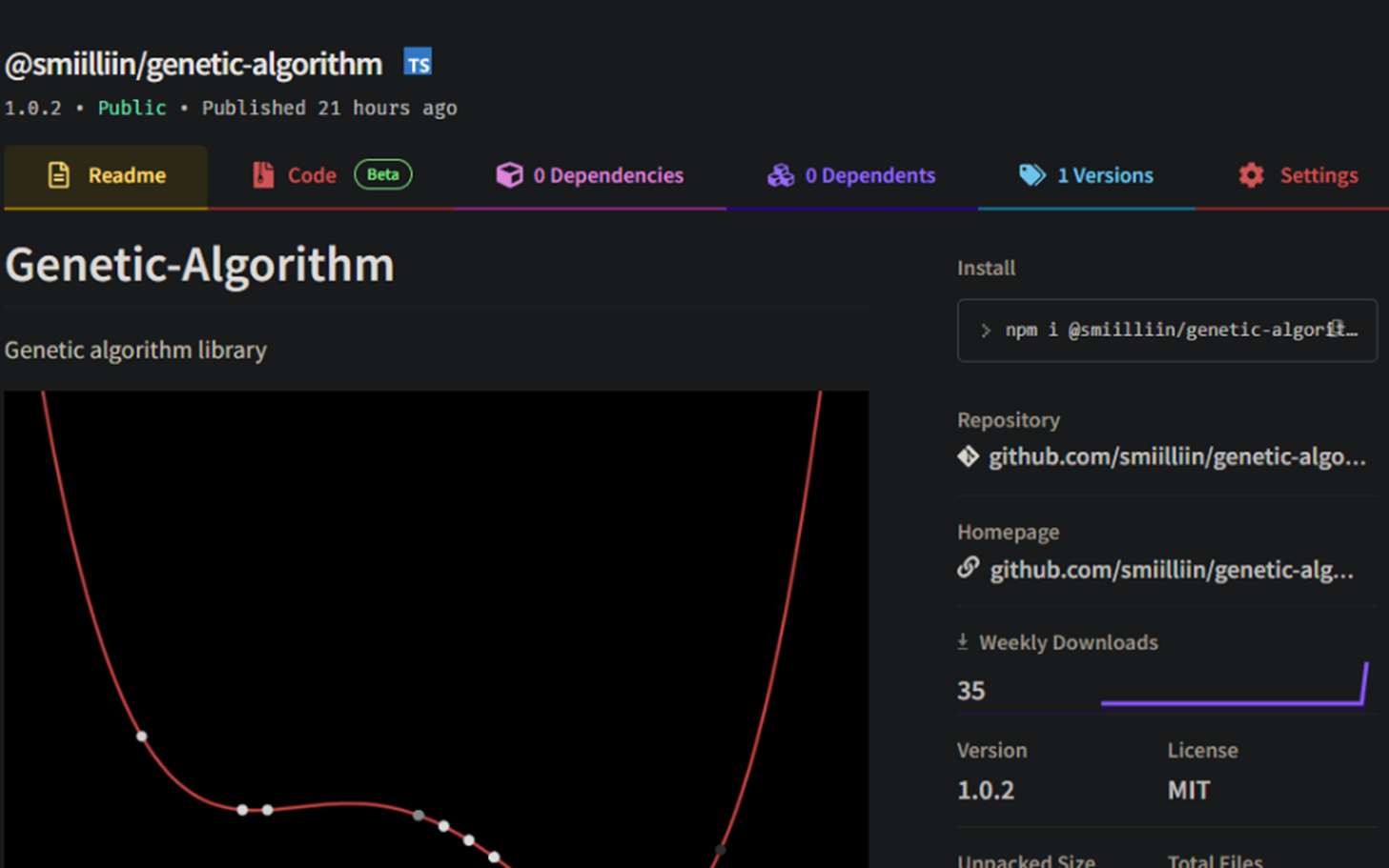
https://www.npmjs.com/package/@smiilliin/genetic-algorithm
직접 구현한 유전자 알고리즘 라이브러리로, 이걸 이용해서 뒤의 알고리즘을 구현할 것이다.

이런 식으로 함수의 최솟값의 점을 찾는 문제에 활용될 수 있다. 보여주고 싶은데 벨로그에 영상 업로드가 되지 않는다...
열품타 분석

"공부⊂일"의 관계로 가정해서 공부의 특징은 곧 일의 특징과 연관될 것이라고 생각했다.
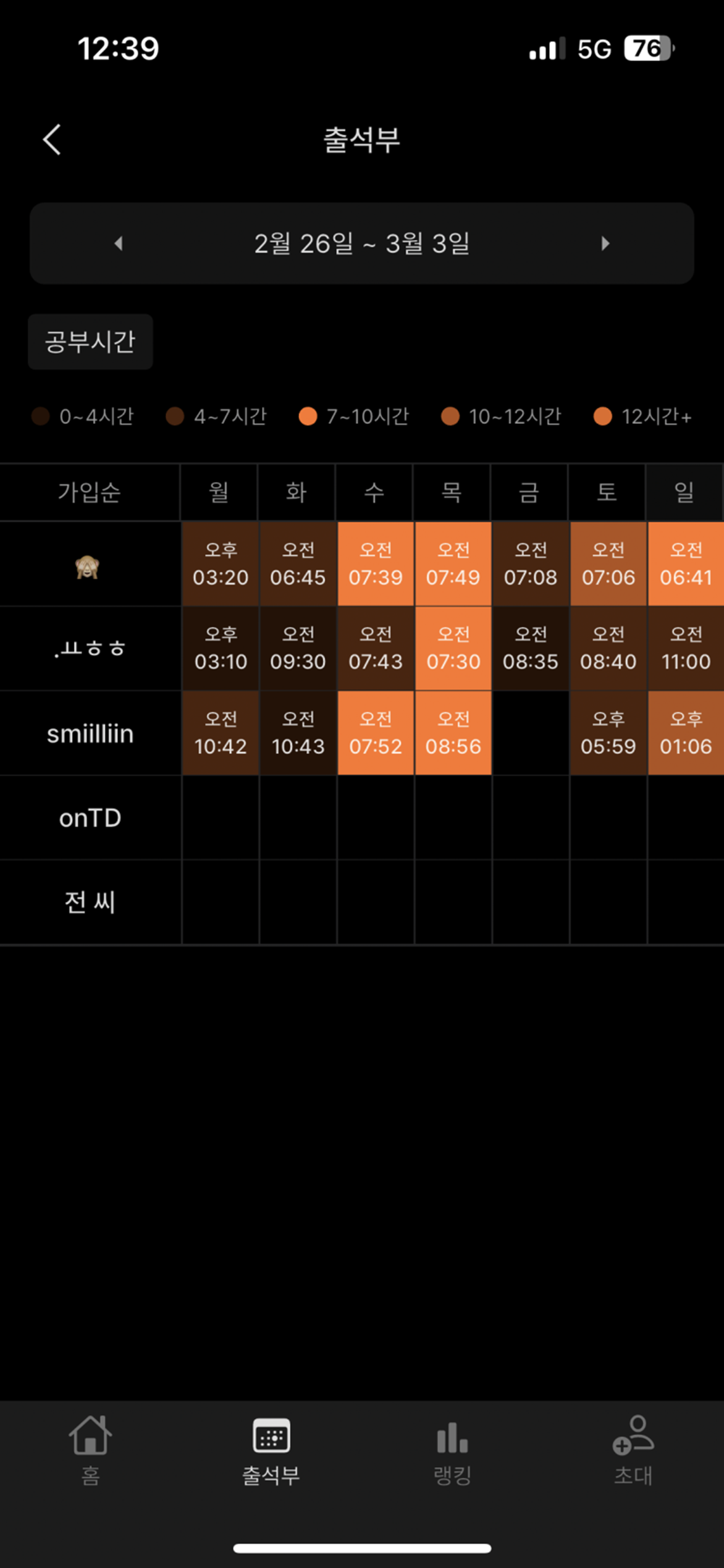
그래서 열정품은타이머 NIT 그룹의 학습량, 주기 2~3월달의 모든 데이터를 수집했다.
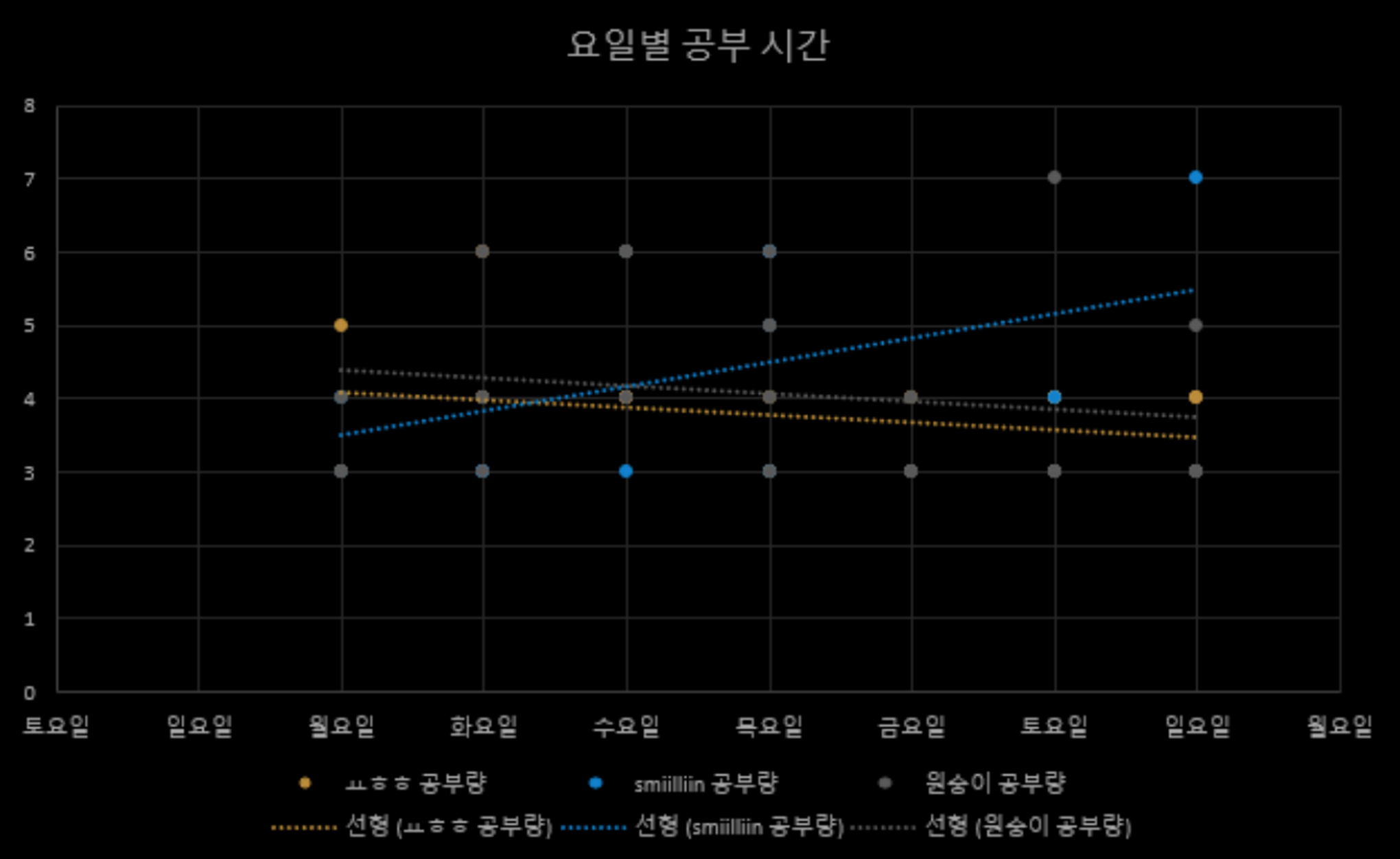
공부시간은 요일과는 상관관계가 없는 것으로 나타났다.
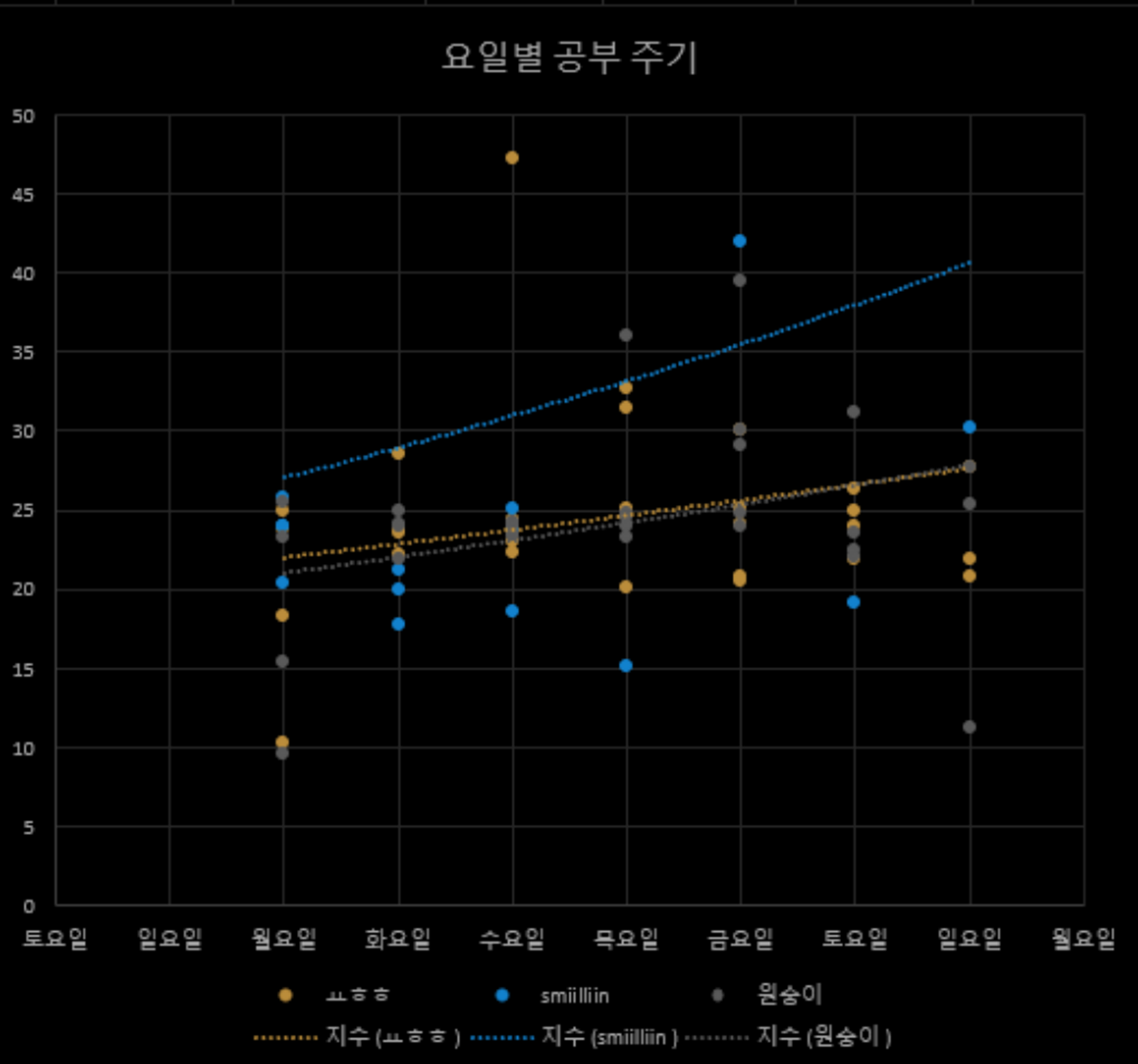
반대로 공부주기는 요일별로 대체로 상관관계가 있다는 것을 알아냈다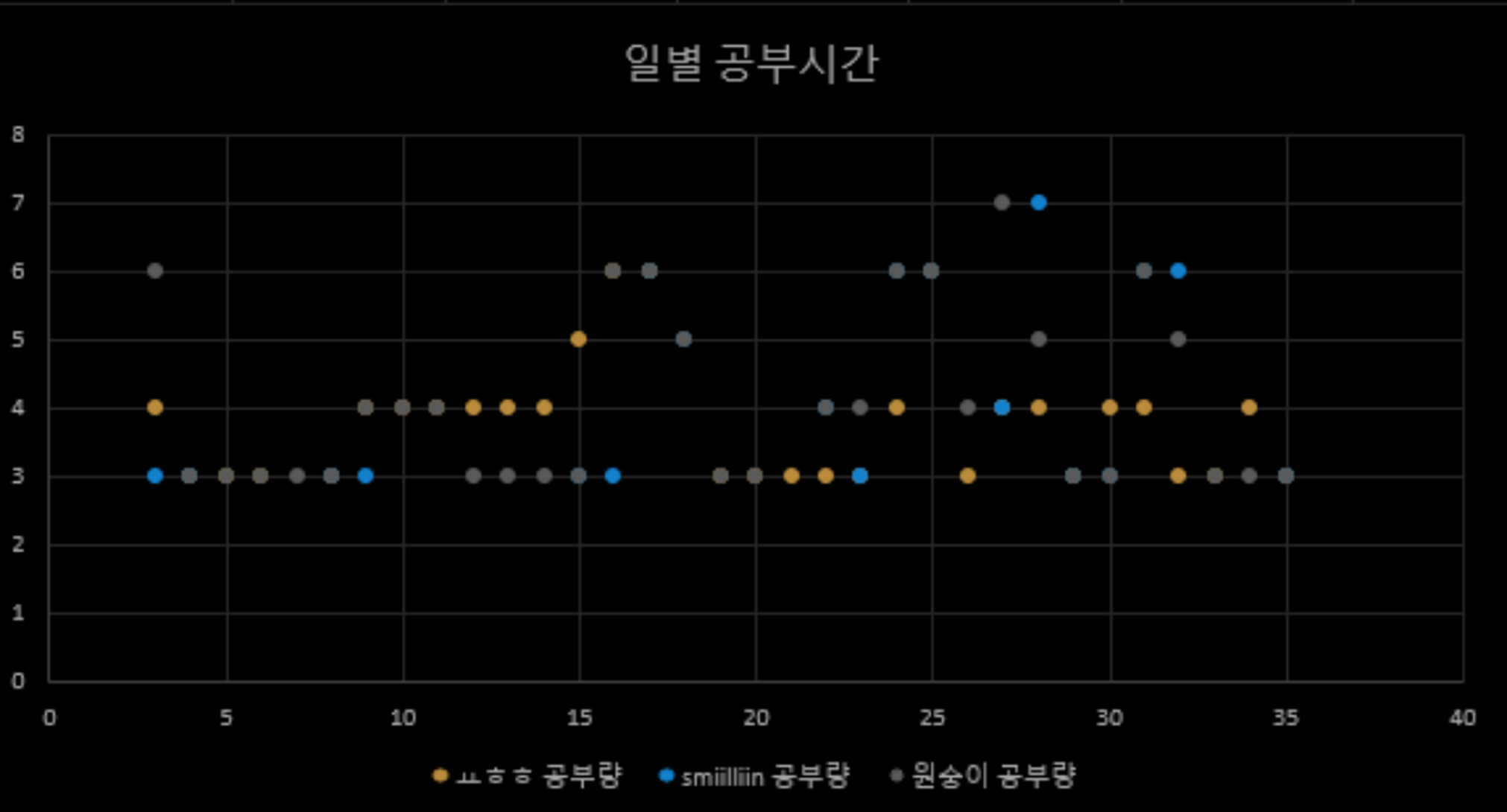
공부시간은 가까운 날짜끼리 비슷한 경향이 있으며 최근의 날짜에 영향을 받는다는 사실도 알아냈다.
얻을 점
- 공부주기는 요일별로 대체로 상관관계가 있으므로 요일 + 날짜에 의한 공부주기 패턴이 존재함
- 공부시간은 요일과 상관관계가 없음
- 하지만 공부시간은 가까운 날짜끼리 비슷한 경향이 있으며 최근의 날짜에 영향을 받음
얻을점2
- 요일 + 날짜를 입력으로 하는 신경망을 통해 공부주기를 예측 할 수 있음
- 가까운 날짜에 더 큰 가중치를 부여해 새로운 공부시간, 공부주기를 얻어낼 수 있음
예측 알고리즘
"딥러닝을 통해 기존 주기를 학습시킴"
여기서는 TypeScript의 Tensorflow 라이브러리를 사용할 것이다.
"기존의 데이터에서 가중치를 이용해 새로운 시간을 예측함"
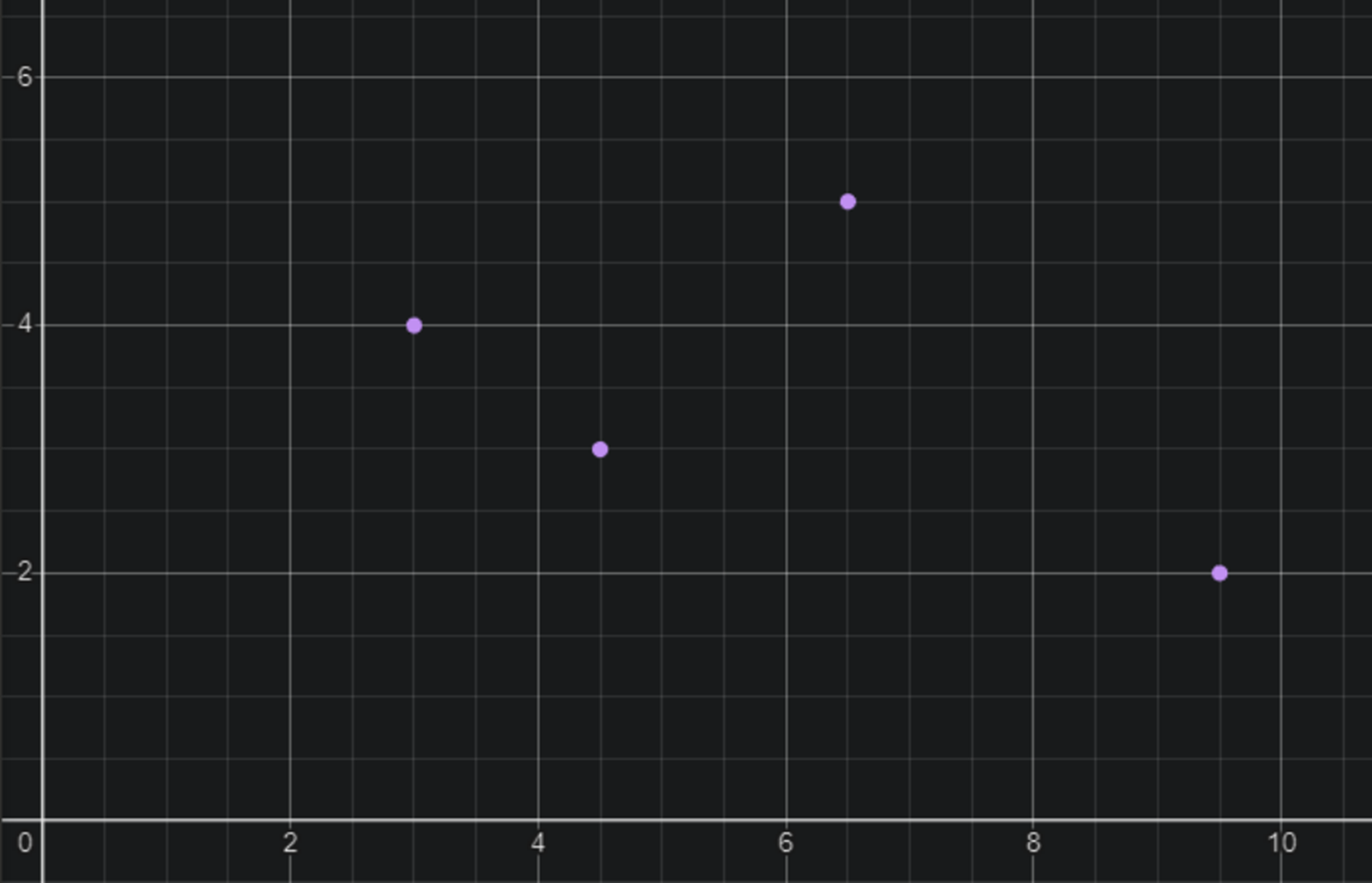
x는 누적 주기, y는 시간

가중치는 현재보다 멀어질수록 작아져야 하고, 1~0사이의 값을 갖는 함수여야 한다.
딥러닝을 통해 얻은 주기를 , 우리가 조정할 상수를 라고 정의하자
지수함수를 통해 정의한 가중치 함수

로그함수를 통해 정의한 가중치 함수

수1 수학책에 나오는 망각곡선 수식 변형

각 데이터에 대해 주기를 , 누적 주기를 , 시간을 배열로 두자!
각 점의 주기인 X[i]와 T의 차이에 가중치를 곱한 값의 합의 최솟값을 찾아야 한다. 이는 T에 대한 이차함수 꼴이므로 미분했을 때 0인 지점을 찾으면 최솟값이 되는 것이다.
다음과 같이 T에 대한 식이 나오게 된다.
시간도 같은 방법으로 두면 이차함수 꼴로 나타나므로 미분했을 때 0인 지점을 찾는다.
예측한 주기와 시간을 실제 주기, 시간과 비교해 점수를 매김
c값에 의해 아까 구했던 주기와 시간을 얻으며, 실제값과의 차이를 지수함수적으로 점수를 매김
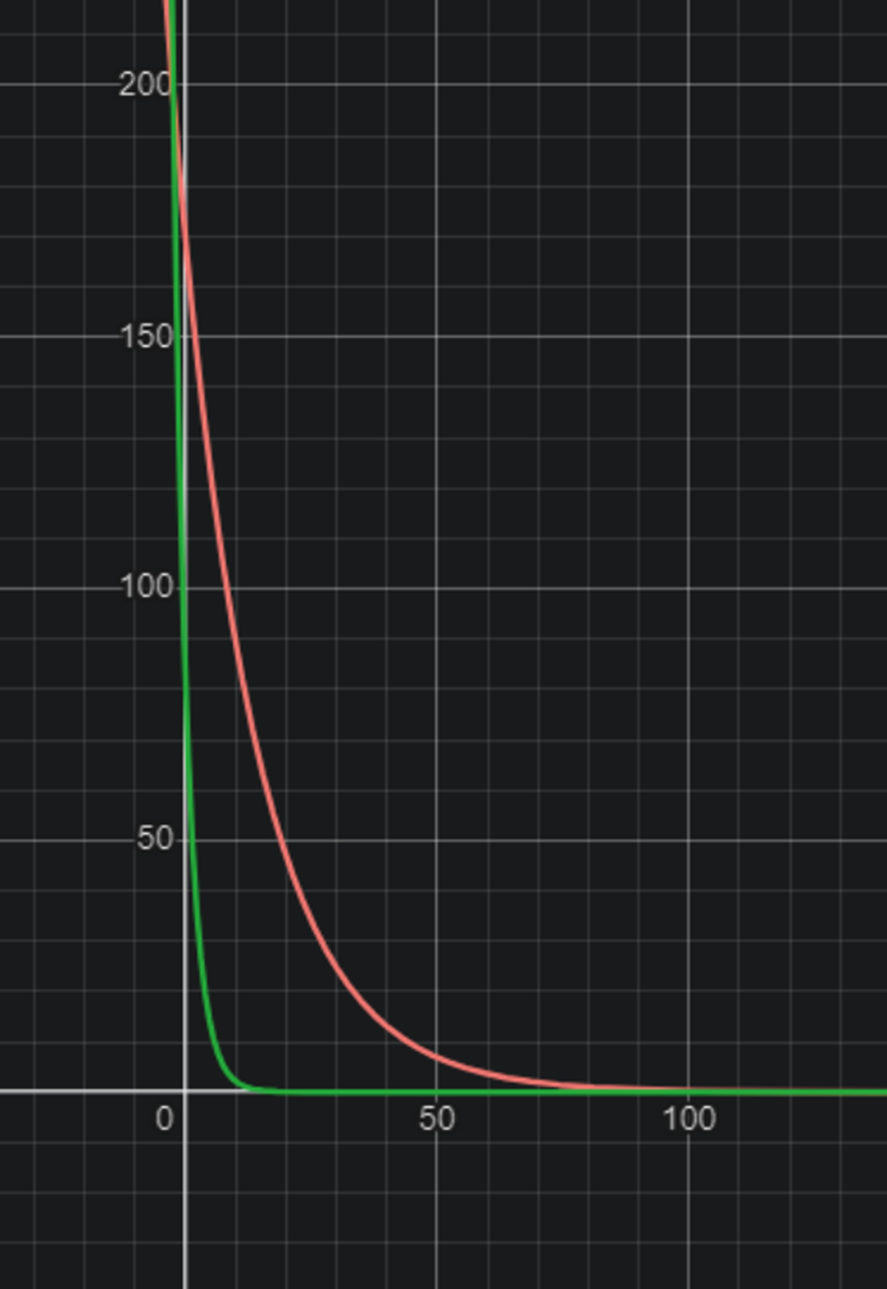
빨간색(주기 차이 점수), 초록색(시간 차이 점수)인데, 주기 차이를 좁혀나가는 것에 더 큰 점수를 부여하도록 설계했다.
부여된 점수를 유전자 알고리즘을 이용해서 더 높은 점수를 고르는 방향으로 c의 값을 찾아나감
유전자 알고리즘에서 각 유전자에 점수를 부여하면 이 과정에서 최적화된 의 값을 구해낼 수 있다.
기존의 데이터 기록과,(딥러닝을 통해 예측), 이전의 c의 값을 이용해 주기와 시간을 예측함
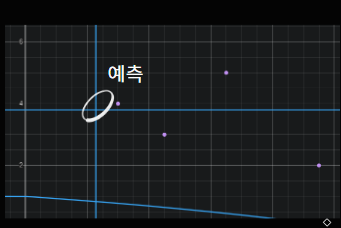
위의 모든 과정을 딥러닝과 유전자 알고리즘을 이용해서 구현한다는 의미이다
알고리즘 장점
- 패턴이 자주 바뀌지 않는 주기는 딥러닝으로 미리 학습된 가중치를 가지고 순전파만 진행하므로 속도가 빠름
- 유전 알고리즘은 딥러닝에 비해 연산량이 적으며 성능이 비교적 부족한 모바일 장치에서 좋은 퍼포먼스를 보여줄 수 있음
- 알고리즘 자체가 복잡하지 않아서 구현하기 어렵지 않음
가중치 함수 비교
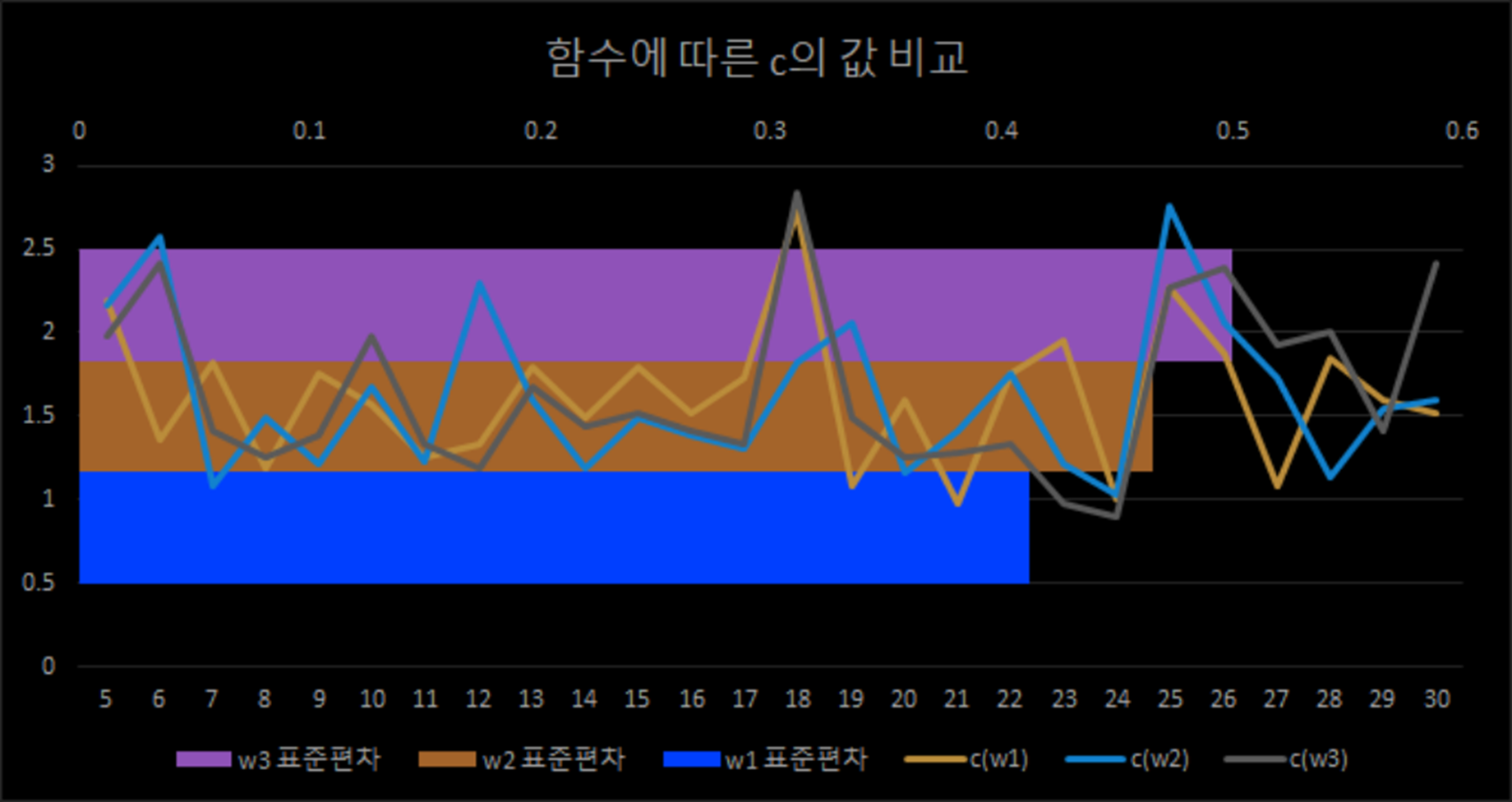
, , 순으로 의 값의 표준편차가 점점 커진다. 의 변동이 심하지 않아야 기존의 를 사용하는 예측에서 정확한 예측이 가능하므로 함수를 사용하기로 하자
구현
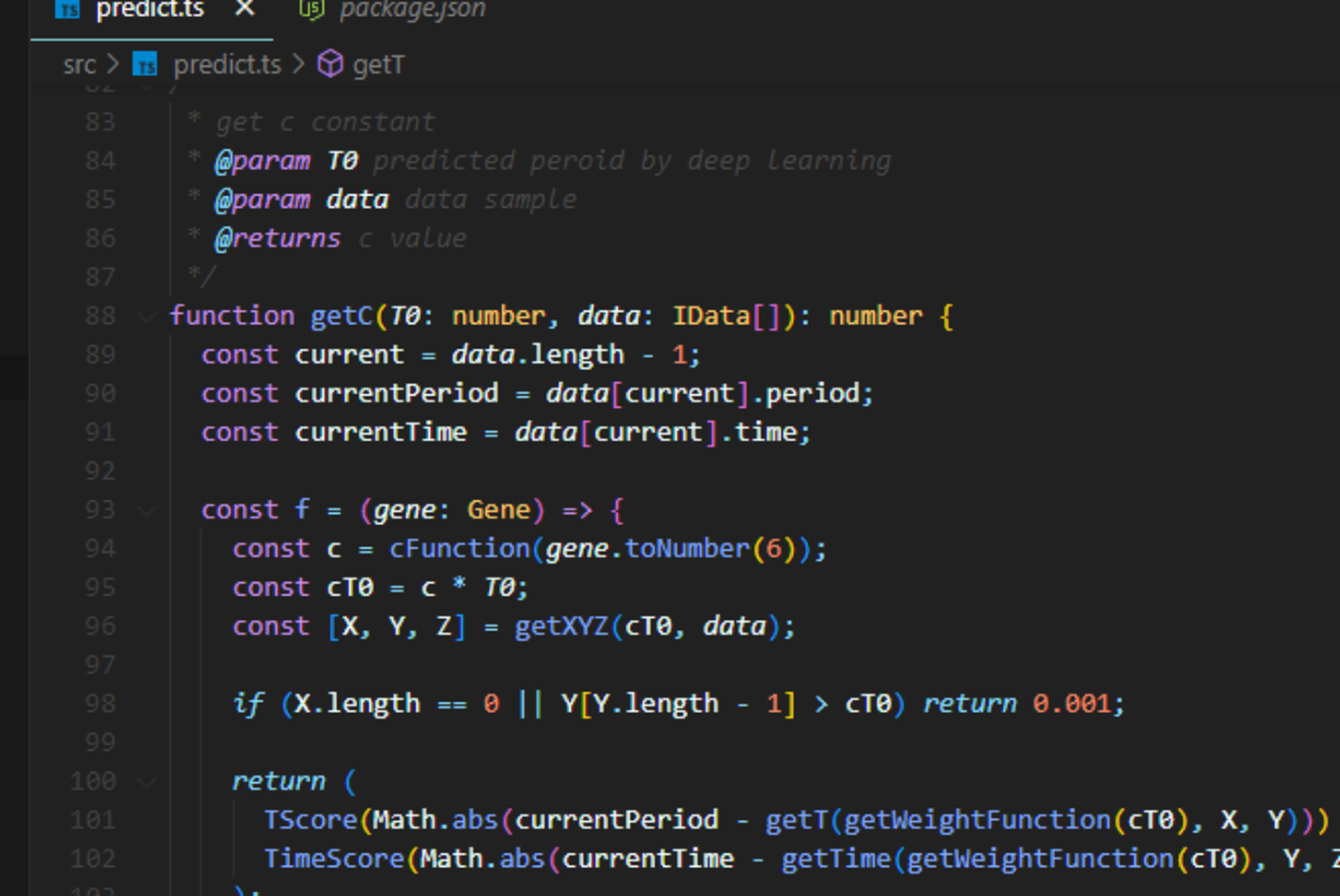
NodeJS, TypeScript, Tensorflow, genetic-algorithm(본인 개발)로 주기, 시간을 예측하는 프로그램을 구현하였다.
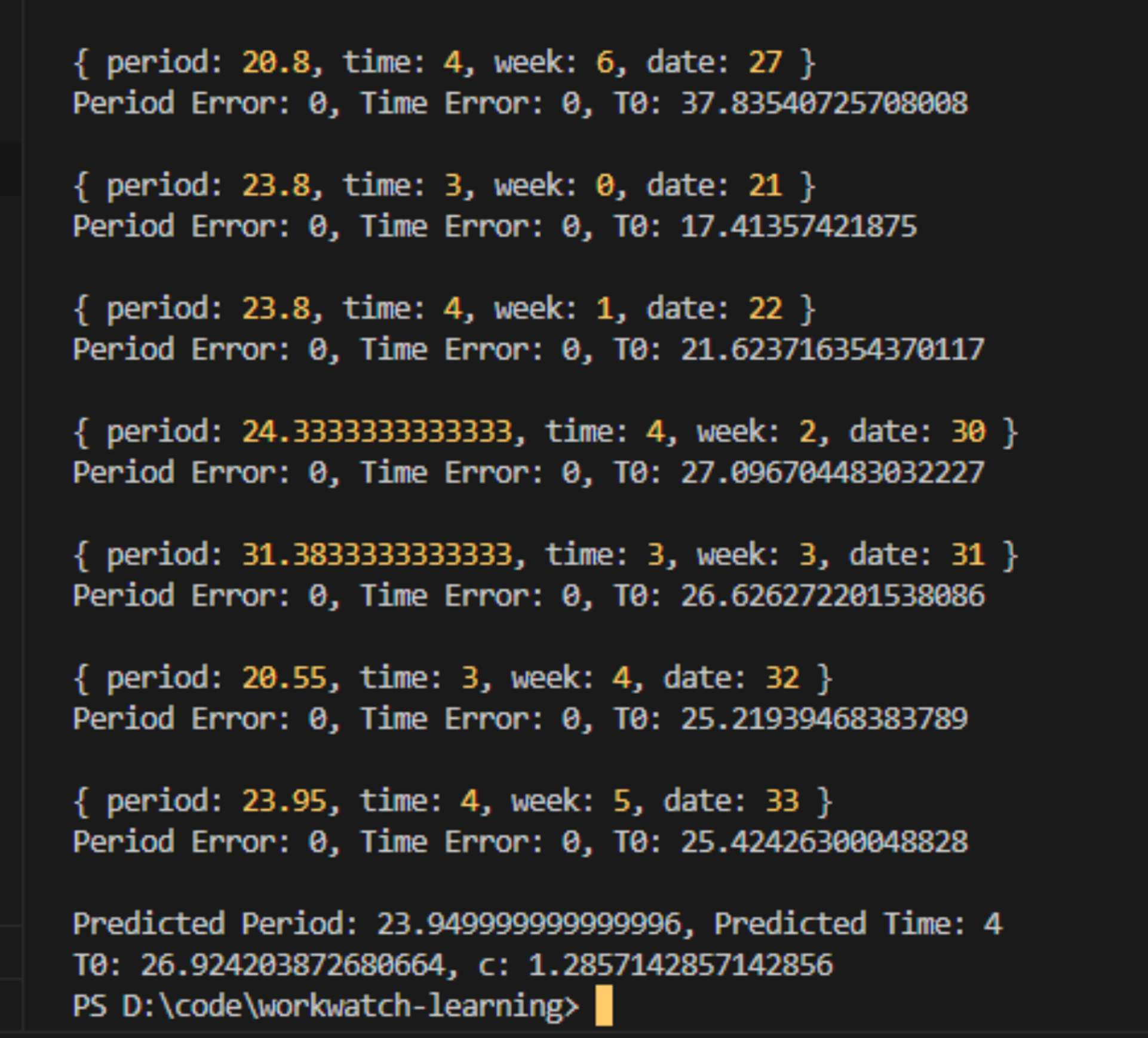
주기 오차, 시간 오차가 대부분 0에 가까웠고, 주기를 23.9시간, 시간은 4시간으로 예측한 모습을 볼 수 있다.
링크
@smiilliin/genetic-algirhtm: https://www.npmjs.com/package/@smiilliin/genetic-algorithm
github: https://github.com/smiilliin/workwatch-learning
