우선 파이참을 다운로드하고 들어갑니다!! gogo
# 변수, 자료형, 조건문, 반복문, 기타 라이브러리
a=2
b=3
print(a+b)
------------------------------------------------------------------------------
first_name ='hello'
last_name= ' sparta'
print(first_name+last_name)
print(str(a)+last_name)
------------------------------------------------------------------------------
a_list=['사과','감', '배']
b_list=['영희', '철수',['사과','감']]
a_list.append('수박')
print(b_list[2][1])
------------------------------------------------------------------------------
a_dict = {'name':'bob', 'age':24}
a_dict['fruit']=a_list
print(a_dict)
------------------------------------------------------------------------------
age=33
if age>20:
print('성인입니다.')
else:
print('청소년입니다.')
------------------------------------------------------------------------------
fruits = ['사과','배','배','감','수박','귤','딸기','사과','배','수박']
for fff in fruits:
if fff=='사과':
print(fff)
------------------------------------------------------------------------------
people = [{'name': 'bob', 'age': 20},
{'name': 'carry', 'age': 38},
{'name': 'john', 'age': 7},
{'name': 'smith', 'age': 17},
{'name': 'ben', 'age': 27}]
for person in people:
if person['age']>20:
print(person['name'])
------------------------------------------------------------------------------
txt = 'sparta@gmail.com'
result = txt.split('@')[1].split('.')[0]
print(result)
------------------------------------------------------------------------------
result = txt.replace('gmail','naver')
print(result)
------------------------------------------------------------------------------
import dload
dload.save("https://spartacodingclub.kr/static/css/images/ogimage.png", 'sparta.png')
from selenium import webdriver
driver = webdriver.Chrome('chromedriver')
#driver.get("http://www.naver.com")
from bs4 import BeautifulSoup
from selenium import webdriver
import time
driver = webdriver.Chrome('chromedriver') # 웹드라이버 파일의 경로
driver.get("https://search.daum.net/search?w=img&nil_search=btn&DA=NTB&enc=utf8&q=%EC%95%84%EC%9D%B4%EC%9C%A0")
time.sleep(5) # 5초 동안 페이지 로딩 기다리기
req = driver.page_source
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
# soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됨
# 이제 코딩을 통해 필요한 부분을 추출하면 된다.
soup = BeautifulSoup(req, 'html.parser')
thumnails = soup.select('#imgList > div > a> img')
i=1
for thumnail in thumnails:
img = thumnail['src']
dload.save(img, f'image/{i}.jpg')
i+=1
driver.quit() # 끝나면 닫아주기변수, 자료형, 조건문, 반복문, 기타 라이브러리를 숨차게 배우는 1주차 수업!
끝나고 나면 호롤롤롤로 뭘배웠지..하지만 재밌어!
1주차 수업이 끝나면 다음이나 네이버 같은 포털 사이트에 검색해서 나오는 이미지들을 내 컴퓨터에 저장할 수 있게 됩니다.
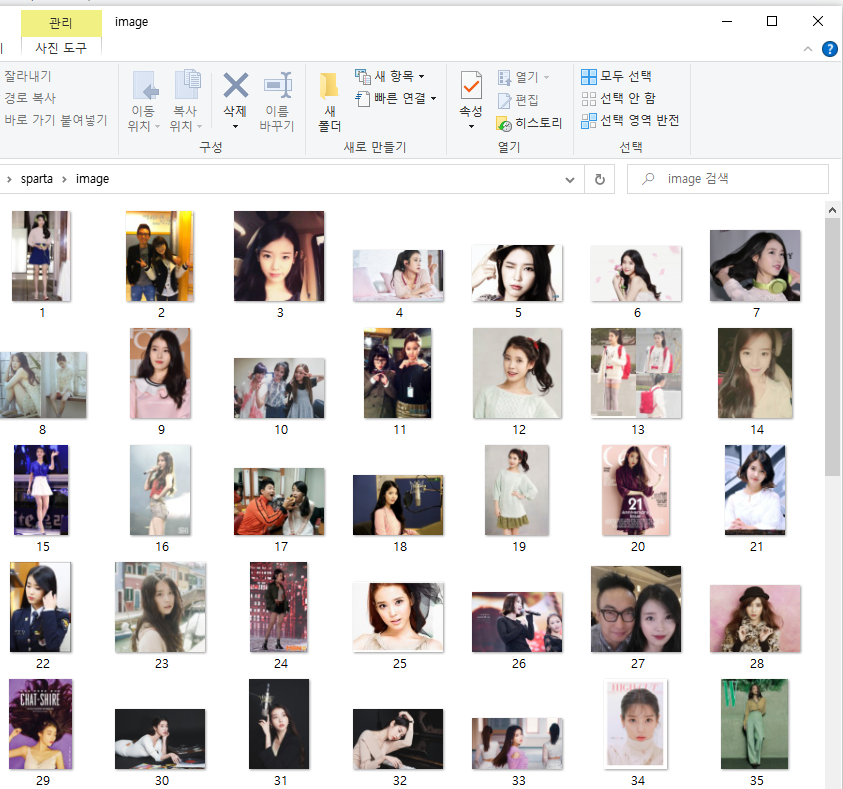
(아이유님이 잔뜩..! 좋아하는 연예인의 사진을 다운받는 것도 가능합니다.)
2주차 수업을 들으면서 정리 및 새로운 기능을 차차 배우게 될 것 같습니다.

soomni's velog