➡️ 공모전 프로젝트의 목표
이번 글에서는 한이음 공모전에서 진행하고있는 수강신청 시스템 개발 시작 과정을 정리하려고 한다.
수강신청 서버는 특히 대용량 트래픽에 취약하기 때문에 '터지지 않는 시스템'을 만들자는 목표로 공모전 프로젝트를 시작하게되었다.

➡️ 기본 MVP
이 프로젝트는 처음부터 복잡한 기술 스택을 도입하기보다는,
기본 기능을 먼저 구현하고 부하 테스트를 통해 문제를 확인하여 점진적으로 개선해나가는 방식으로 진행하고자 한다.
우선, 아래는 이번 프로젝트에서 설정한 기본 MVP 기능이다.
| 구분 | 기능 요약 | 설명 |
|---|---|---|
| 1 | 회원가입 / 로그인 | 사용자는 회원가입을 통해 계정을 생성하고, 로그인/로그아웃할 수 있음 |
| 2 | 사용자 정보 조회 | 사용자는 본인의 이름, 학번, 학점 등 기본 정보를 조회할 수 있음 |
| 3 | 강의 목록 조회 | 개설된 강의 목록을 조회하고, 각 강의의 수강 가능 인원을 확인할 수 있음 |
| 4 | 수강 신청 / 취소 | 원하는 강의를 신청하고, 이미 신청한 강의를 취소할 수 있음 |
➡️ 협업과 진행방식
- Slack
- 실시간 커뮤니케이션 및 데일리 스탠드업 공유
- 긴급 이슈나 장애 발생 시 신속한 대응
- 논의된 사항 빠르게 기록 및 알림
- Confluence
- 기술 설계와 구조 도식화 문서 작성
(아키텍처, API 명세, 회고 등) - 테스트 결과 및 병목 지점 정리
- 스프린트 리뷰 및 피드백 기록
- 기술 설계와 구조 도식화 문서 작성
- Jira
- 기능을 작은 단위 업무로 나눠 관리
- 마일스톤 기반 작업 계획 수립 및 진행률 시각화
- To Do → In Progress → Done 상태로 진행 상황 추적
아래는 실제 Jira 보드에서 수강신청 기본 기능을 Task 단위로 나누어 정리한 모습입니다.
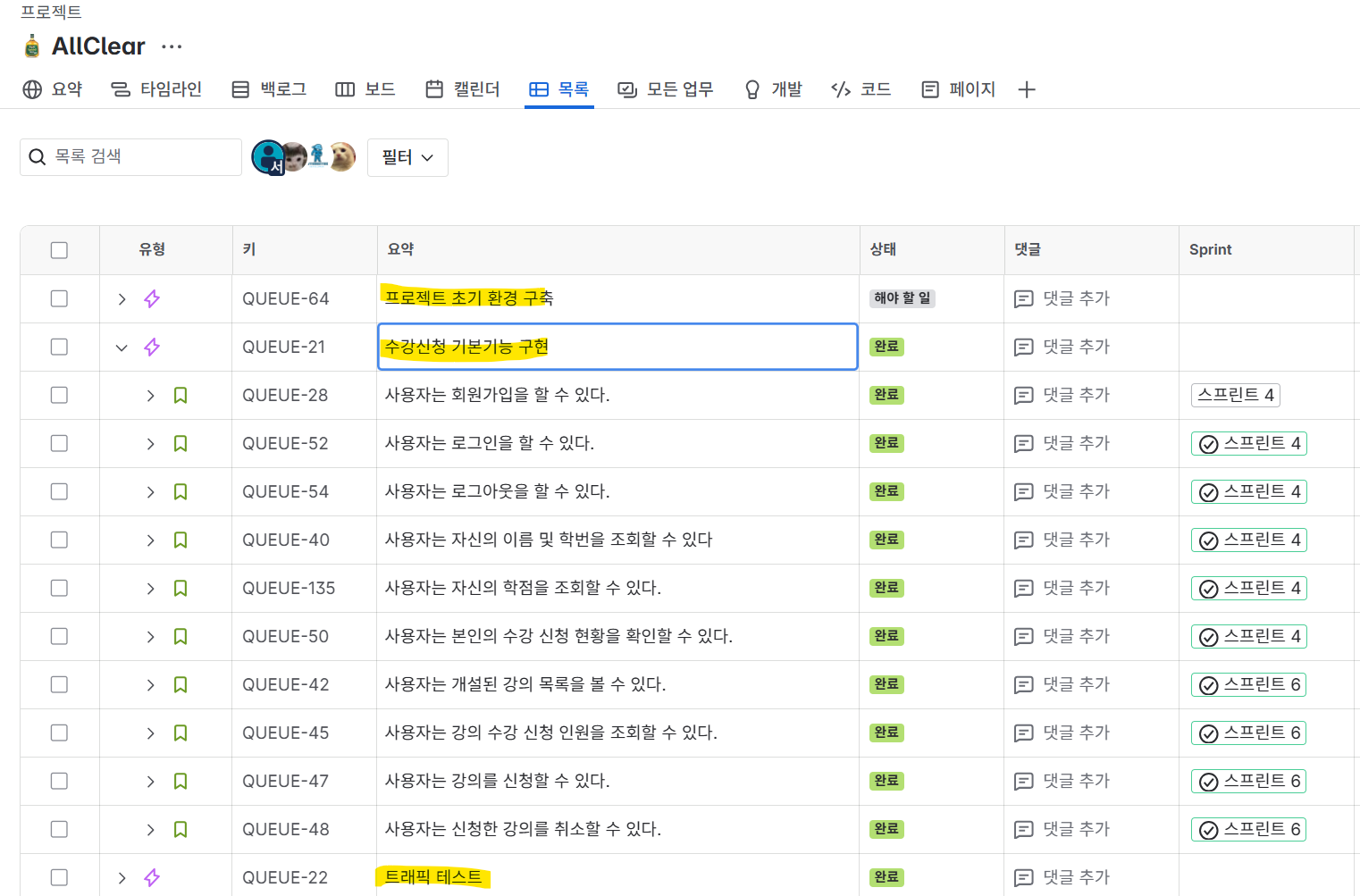
🌟 목표 단위 중심의 애자일 전략
프로젝트를 진행할 때 ‘전체 기능을 한 번에 구현’하는 방식보다,
작은 단위로 쪼개어 빠르게 실현하고 반복적으로 개선하는 방식을 선택했습니다.
프론트와 백엔드가 각자 담당할 Task를 나눈 뒤, 매 스프린트마다 우선순위를 정해 협업하고 테스트하며 점진적으로 기능을 완성합니다.
- Epic(에픽)
- 전체 목표 단위
- 위 MVP 기반으로 작성
- User Story(사용자 스토리)
- 사용자 중심 기능 정의
- 실제 사용자의 행동 기반으로 표현 (사용자는 ~할 수 있다)
- Ticket(티켓)
- 실제 개발 단위
- GitHub 브랜치 네이밍도 티켓 키 기준으로 통일
(exfeature/QUEUE-52-login-api)
즉, 작게 만들고, 빠르게 적용하고, 반복적으로 개선하는 애자일 개발 전략을 따릅니다.
➡️ ERD
기능 구현에 앞서, 핵심 데이터 흐름과 테이블 간 관계를 먼저 정의했고,
그에 따라 설계된 주요 테이블 구조는 아래와 같다.
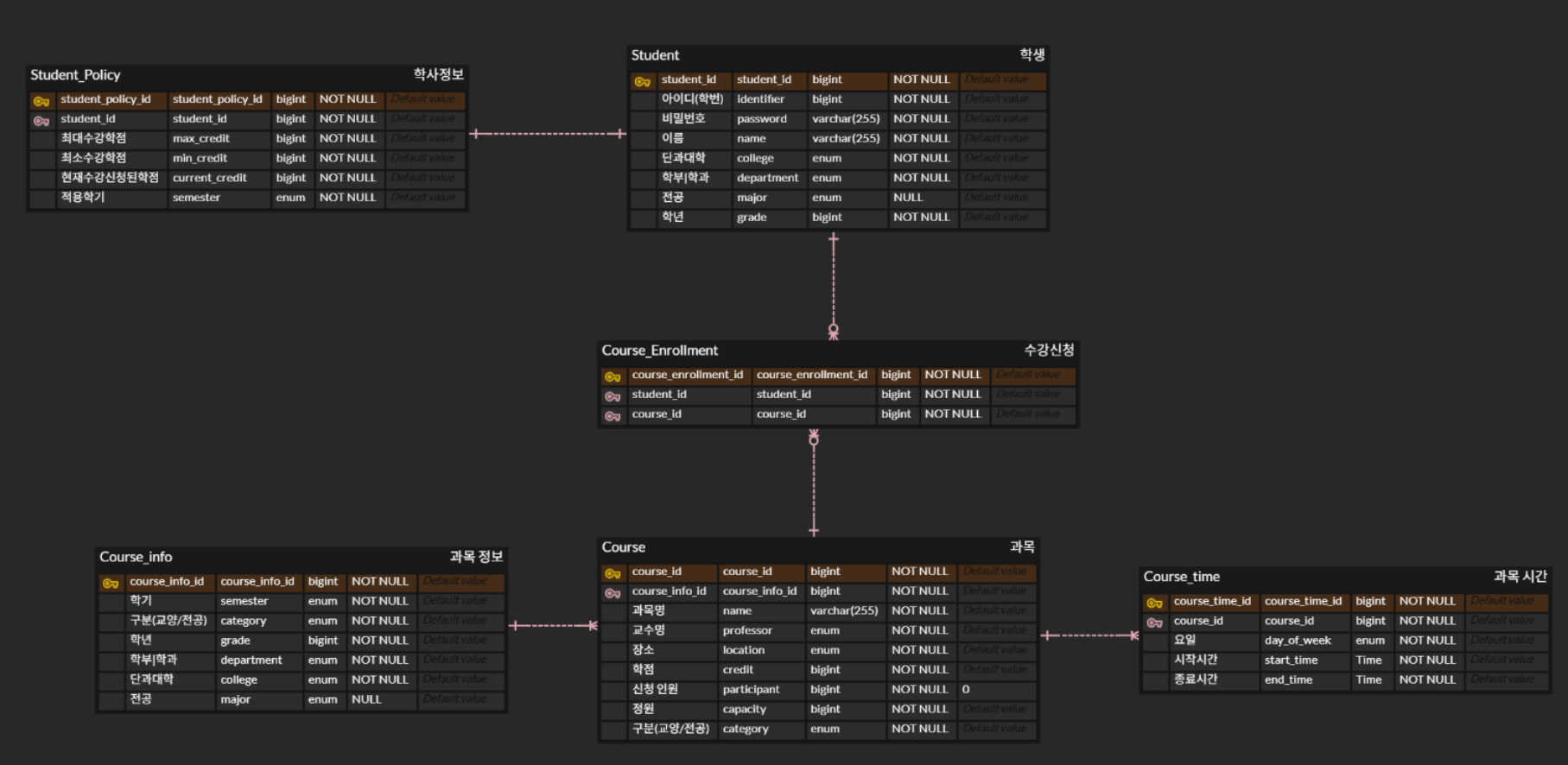
| 테이블명 | 설명 |
|---|---|
| student | 사용자 기본 정보 (학번, 이름, 단과대, 학과, 학년 등) |
| student_policy | 각 학생에게 적용되는 수강 정책 정보 (최대 수강 가능 학점, 전공/교양 조건 등) |
| course_info | 강의 개설 조건 (학기, 전공 여부 등 메타 정보 정의) |
| course | 실제 개설된 강의 정보 (과목명, 교수명, 수업시간, 정원 등) |
| course_time | 강의 시간 정보 (요일, 시작/종료 시간 등) |
| course_enrollment | 학생의 수강 신청 내역. student와 course 간의 중간 테이블 역할 |
👉 테이블 간 관계 및 설계 의도
student ↔ student_policy (1:1 관계)
→ 한 학생마다 고유의 수강 정책이 존재하기 때문에 명확히 분리
student ↔ course_enrollment ↔ course (N:M 관계)
→ 수강 신청 로직에는 단순 연결 외에도
✔ 중복 신청 방지
✔ 시간 중복 체크
✔ 신청 마감 여부 검증 등 복잡한 로직이 존재
→ 이를 모두 처리하기 위해 중간 테이블을 중심으로 구조 설계
course ↔ course_time (1:N 관계)
→ 하나의 강의가 여러 요일/시간대에 개설될 수 있는 구조
→ ex) 월/수, 화/목 각각 다른 시간대 강의
course ↔ course_info (N:1 관계)
→ 과목 자체에 대한 분류 정보(전공/교양, 학기 등)를 course_info에 따로 분리하여 필터링 성능을 높이고, 재사용 가능한 메타 정보로 활용
➡️ 서버 아키텍처
① 사용자 (Client)
사용자가 수강신청 버튼을 클릭하면 요청은 Spring REST API 서버로 전송
② Spring 서버 (Docker 컨테이너)
서버는 EC2 인스턴스 내 Docker 컨테이너에 배포되어 있음
수신된 요청을 처리하고 필요한 비즈니스 로직(중복 검사, 정원 제한 등)을 수행
이때 @Transactional 기반 트랜잭션 처리와 DB 레벨의 Lock을 통해 동시성 제어
③ RDS (MySQL)
검증을 통과한 신청 정보는 AWS RDS에 위치한 MySQL DB에 저장
➡️ 다음 단계
지금까지 수강신청 시스템의 기본 기능을 어떻게 설계하고 구현했는지 살펴보았습니다. 하지만 실제로 이 시스템이 수백 명, 수천 명의 동시 요청을 견딜 수 있을지는 아직 확인되지 않았습니다.
다음 단계에서는 JMeter를 활용해 부하 테스트를 진행하고,
어떤 시점에 병목이 발생하는지, 그 병목을 어떻게 개선할 수 있을지 구체적으로 분석해보려고 합니다.
단순히 잘 작동하는 것이 아니라 많은 사용자를 견디는 시스템으로 확장해나가는 과정을 기록할 예정입니다.
