1. 도입 배경
기존 수강신청 시스템은 Polling 방식으로 동작하고 있었다.
사용자는 일정 간격으로 자신의 대기 상태를 확인하며,
ALLOWED 상태가 되었는지를 계속 서버에 요청해야 했다.
Polling 방식은 단순하고 안정적이라는 장점이 있었지만
대기 인원이 많아질수록 불필요한 요청이 반복적으로 발생했고,
서버는 매 요청마다 사용자 상태를 계산하고 응답해야 했다.
"사용자가 굳이 물어보지 않아도 되게 할 수 없을까❓"
그렇게 도입하게 된 구조가 바로 SSE(Server-Sent Events)이다.

2. SSE란?
SSE(Server-Sent Events)는 서버가 클라이언트에 단방향으로 실시간 데이터를 푸시하는 기술이다.
HTTP 기반으로 동작하며 브라우저가 서버와 연결을 유지하고 있다가
서버에서 이벤트가 발생할 때마다 event-stream을 통해 바로 데이터를 받을 수 있다.
📌 특징
- 연결 방식: 단방향 (서버 → 클라이언트)
- 전송 프로토콜: HTTP + text/event-stream
- 장점: WebSocket보다 가볍고 브라우저 호환성도 뛰어남
- 사용 시점: 실시간 알림, 상태 푸시, 실시간 대시보드 등
👉 우리는 이 구조를 활용해 “입장 가능” 과 “순번 상태 변경”을 실시간으로 알려주는 방식으로 전환했다.
➡️ 왜 Polling보다 효율적인가?
| 항목 | Polling 방식 | SSE 방식 |
|---|---|---|
| 연결 방식 | 요청마다 새로 연결 | 한 번 연결 후 지속 유지 |
| 응답 방식 | 정해진 주기로 서버 상태를 요청 | 서버가 이벤트 발생 시 실시간 푸시 |
| 네트워크 사용량 | 주기적으로 요청 → 트래픽 많음 | 연결 유지 상태 → 트래픽 적음 |
| 실시간성 | 일정 간격마다 확인 → 느림 | 이벤트 발생 즉시 전송 → 빠름 |
| 구현 난이도 | 간단함 (HTTP GET 반복) | 약간 복잡 (Emitter 관리 필요) |
➡️ Spring에서 SSE 구현 방식
Spring에서는 SseEmitter라는 클래스를 제공한다.
이를 통해 클라이언트에 메시지를 비동기적으로 푸시할 수 있다.
@GetMapping(value = "/sse/{uuid}", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public SseEmitter subscribe(@PathVariable String uuid) {
return sseQueueService.subscribe(uuid);
}MediaType.TEXT_EVENT_STREAM_VALUE→ SSE 프로토콜을 사용한다는 의미- 연결된 사용자 별로 SseEmitter 인스턴스를 발급해 연결 상태를 관리한다.
✅ 지속 연결 관리 – EmitterManager
EmitterManager는 사용자별로 연결된 SSE 통신 채널(SseEmitter)을 관리하는 역할을 한다.
private final Map<String, SseEmitter> emitters = new ConcurrentHashMap<>();token(UUID)를 키로 사용해 각 사용자의 SseEmitter를 저장ConcurrentHashMap을 사용해 멀티스레드 환경에서도 안전하게 동작
에러, 타임아웃, 종료 이벤트는 자동으로 감지되며
해당 시점에 emitter.complete() 및 removeEmitter(token)을 호출해 메모리 누수를 방지했다.
3. 구현 흐름
전체 흐름은 다음과 같이 변경되었다.
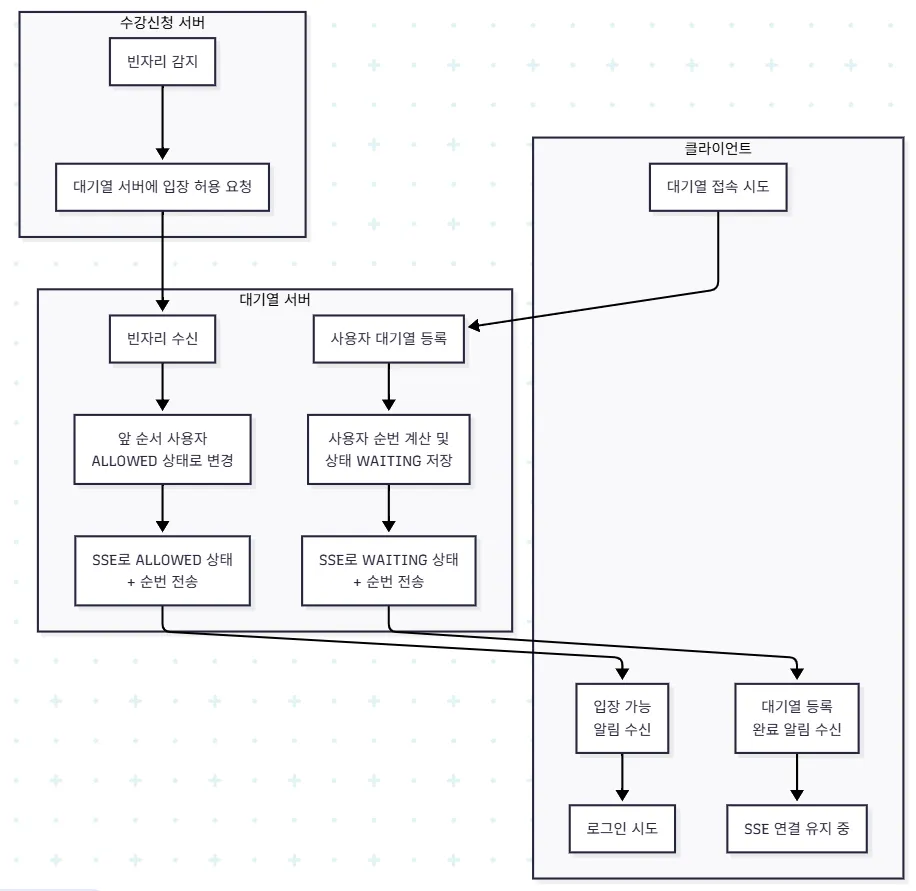
1️⃣ 사용자가 /join을 통해 대기열에 진입하면
서버는 사용자 정보를 큐에 등록하고 상태 WAITING과 순번을 반환한다.
2️⃣ 1번 과정에서 클라이언트는 SSE에 연결된다.
이제부터 클라이언트가 주기적으로 상태를 요청하지 않아도 서버는 상태가 변경되면 실시간으로 메시지를 보낸다.
3️⃣ 빈자리가 발생하면 수강신청 서버에게 /notify API로 알림을 받고, 큐의 앞쪽에 있는 기준으로 입장 대상자를 선정한다.
해당 사용자들에게 ALLOWED 상태의 메시지를 SSE로 push한다.
4️⃣ ALLOWED 사용자는 로그인 시도
입장 완료 후 SSE 연결 종료!
대기 중인 사용자들 순번을 다시 계산하여 WAITING 상태와 순번을 반환한다.
4. 비동기 전송 구조 도입
SSE는 서버가 클라이언트에게 실시간으로 데이터를 push하는 구조지만
이 전송은 내부적으로 I/O 작업이다.
즉, 데이터를 보내는 순간까지 해당 스레드는 블로킹 상태가 될 수 있다.
만약 여러 사용자에게 동시에 메시지를 보내야 하는 상황이라면❓
✔️ 각 사용자의 전송이 순차적으로 처리되면 전체 처리 시간이 늦어지고
✔️ 하나의 사용자 전송이 지연되면 나머지 사용자 알림도 지연되는 문제가 생긴다.
그래서 SSE 전송 로직을 별도 클래스로 분리하고 @Async를 통해 비동기 전송이 되도록 리팩토링했다.
🖥️ SseAsyncSender.java
@Slf4j
@Component
@RequiredArgsConstructor
public class SseAsyncSender {
private final SseEmitterManager emitterManager;
@Async("sseAsyncExecutor")
public void send(SseEmitter emitter, String event, Object data, String token) {
try {
emitter.send(SseEmitter.event()
.name(event)
.data(data));
log.info("✅ send 성공!!");
if ("allowed".equals(event)) {
emitter.complete();
emitterManager.removeEmitter(token);
log.info("✅ emitter 종료 및 제거 완료: token={}", token);
}
} catch (IOException e) {
log.warn("🚨 SSE 전송 실패: event={}, message={}", event, e.getMessage());
}
}
}@Async("sseAsyncExecutor")를 붙여 이 메서드는 별도 스레드풀에서 비동기로 실행- 동시에 수십 명에게도 병렬로 빠르게 전송 가능
"allowed"이벤트일 경우 emitter를 종료하고 등록된 emitter도 정리- 전송 성공/실패 로그를 통해 상태 추적 가능
이 구조가 없었다면… 수천명의 대기자가 동시에 입장이 허용되는 상황에서 사용자 1명의 전송이 지연될 때 나머지 모두가 기다려야 했을지도 모른다..
🤣 비동기화는 성능을 위한 선택이 아니라 필수였다!
5. 비동기 스레드풀 조정
기존에는 톰캣 기본 스레드풀을 조정해 요청 처리를 분산하고 있었지만
이번에는 SSE 전송 전용 비동기 스레드풀을 별도로 도입하고 튜닝을 진행했다.
왜냐하면 SSE 메시지 전송은 I/O 작업이기 때문에 수많은 사용자에게 메시지를 한꺼번에 보내야 하는 순간 서버의 처리 병목이 생길 수 있기 때문이다.
✅ 비동기 스레드풀이란?
Spring에서는 @Async를 통해 특정 메서드를 별도 스레드풀에서 병렬 실행할 수 있다.
우리는 SseEmitter.send() 전송을 비동기로 처리하기 위해 다음처럼 스레드풀을 정의했다.
private static final int CORE_POOL_SIZE = 16;
private static final int MAX_POOL_SIZE = 64;
private static final int QUEUE_CAPACITY = 800;그리고 이 풀을 sseAsyncExecutor로 지정하여 SSE 전송 전용 비동기 처리 스레드풀로 사용했다.
- CORE_POOL_SIZE : 요청이 없어도 유지되는 기본 스레드 수
- MAX_POOL_SIZE : 큐가 가득 찼을 때 생성 가능한 최대 스레드 수
- QUEUE_CAPACITY : 대기 큐 크기. Core를 초과한 요청이 일시적으로 저장되는 공간
➡️ 1차 설정 (과대 설정)
CORE_POOL_SIZE = 64
MAX_POOL_SIZE = 256
QUEUE_CAPACITY = 2000 - 오히려 오류율이 높았음
- CPU 사용량만 높고 실제 전송은 제대로 병렬처리되지 않음
- 📌
t3.large인스턴스의 성능 한계로 과도한 스레드는 컨텍스트 스위칭만 유발함
➡️ 2차 → 3차 → 4차... 테스트
스레드풀의 크기를 단계적으로 줄여가며 오류율을 비교한 결과
오류율이 다시 높아지는 시점을 기준으로 최적점을 찾아낼 수 있었다.
그 결과 실제 배포 환경인 t3.large 인스턴스(vCPU 2, RAM 8GB)에 가장 적합한 설정은 다음과 같았다:
CORE_POOL_SIZE = 16
MAX_POOL_SIZE = 64
QUEUE_CAPACITY = 800이 설정은 테스트 과정에서 충분한 병렬 처리 성능을 제공하면서도
불필요한 컨텍스트 스위칭이나 CPU 과소비 없이 안정적인 전송 처리가 가능했다.
🌟중요🌟
단순히 스레드를 많이 할당한다고 성능이 오르지 않는다는 점을 실험을 통해 직접 확인할 수 있었다.
서버 리소스와 작업 특성을 고려한 실험적 튜닝이 가장 중요하다!!
