GraphQL 개발 배경(REST API의 한계)
GraphQL은 페이스북이 개발한 Query Language 입니다. 여기서 Query란 데이터베이스에 정보를 요청하는 것으로, Query Language는 데이터베이스에 접근할 수 있는 언어라고 이해할 수 있습니다.
GraphQL은 REST API의 단점을 해결하기 위해 개발되었는데, 가장 큰 장점으로 Endpoint가 '하나' 라는 점입니다. REST API는 정의된 여러 Endpoint에 엑세스하여 데이터를 수집해야 합니다. 여기서 문제는 클라이언트에서 필요한 데이터는 언제든 변화할 수 있는데, REST API는 고정되어 있는 데이터를 수집하기 때문에 필요이상의 데이터를 받거나(Over-Fetching), 필요한 정보가 없는 경우가 발생할 수 있습니다.(Under-Fetching)
Endpoint를 하나로 설정하여 데이터베이스를 구축한다면, 여러 Endpoint에서 데이터를 구축하지 않아도 되기 때문에 유연하게 대처할 수 있습니다.
Over-Fetching
예를 들어, 사용자의 데이터를 조회하는 /user API가 있다고 가정하고, 사용자 번호: 1에 해당하는 데이터를 조회한다고 했을 때 아래와 같은 형태가 됩니다.
GET/user/1
reponse body
{
'user_no': 1,
'user_name': 'test',
'user_grede: 'VVIP',
'zip': '11053',
'last_login_timestamp': '2019-08-08:12:11:44'
...
}여기서 클라이언트 에서는 1번에 해당하는 유저의 이름만을 사용하고자 한다 해도 유저 이름만 반환하는 API가 없다면, 위와 같은 /user/1 API를 호출한 다음, user_name을 가져와 사용해야 합니다. 이때, user_grade , zip 등등에 데이터는 사용하지 않아도 되지만 같이 반환 받습니다. 이는 곧 리소스의 낭비라고 볼 수 있고 이와 같은 낭비를 Over-Fetching 이라고 합니다.
Under-Fetching
쇼핑몰 서비스가 있다고 가정할 경우, 로그인한 사용자의 장바구니 정보를 보여준다고 가정하면 여러 API를 호출하게 됩니다.
/user/1
/cart
/notification
/wish요청에 맞게 유효한 데이터를 보여주기 위해 여러 API를 호출하게 되는 경우를 Under-Fetching이라고 합니다.
REST API 방법론으로 API를 만든다고 하면 Resource 별로 Endpoint를 갖기 때문에 비슷하지만 다른 API를 생성하게 됩니다.
/item
/item/detail
/item/image
/item/notice
/item/manage이는 서비스가 커져갈 때 관리 포인트가 늘어나게 되므로, 개발자나 클라이언트에게 부담이 됩니다.
GraphQL
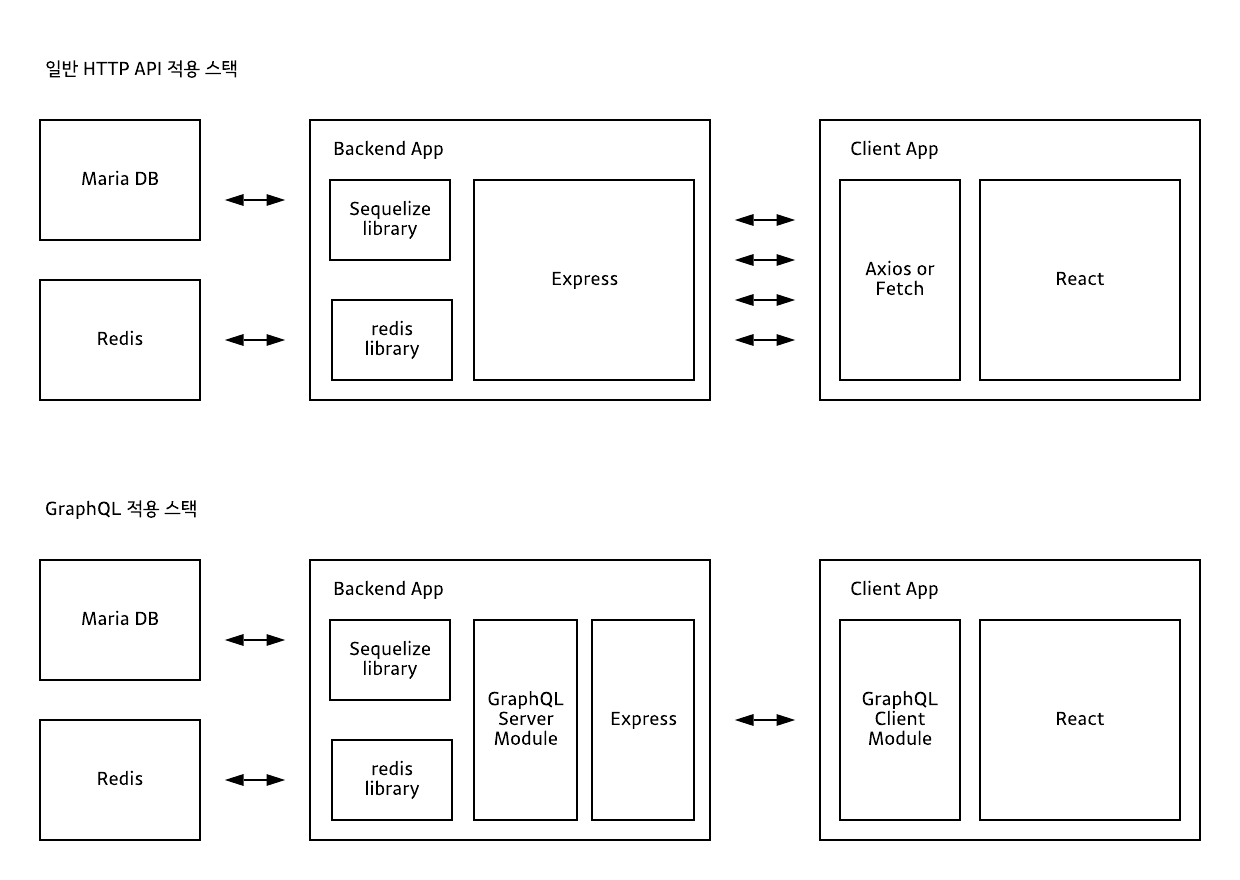
GraphQL은 위에서 설명한 것처럼 REST API의 한계를 극복하고자 나왔습니다. Endpoint는 통상 1개만 생성하고 클라이언트에게 필요한 데이터는 클라이언트가 직접 쿼리를 작성, 호출하여 반환 받습니다.
위의 Over-Fetching 문제를 GraphQL을 사용하면 손쉽게 해결할 수 있습니다.
Request Query
query {
cart {
product_name
price
}
notification {
is_read
}
user(user_id:1) {
user_name
user_grade
}
}
}Response Data
{
'cart': [{
'product_name': 'shoes',
'price' : 12000
}, ...],
'notification': [{
is_read: true
}],
'user': {
'user_name': 'jim',
'user_grade': 'VVIP'
}
}Under-Fetching 문제 또한 GraphQL을 이용하여 해결할 수 있습니다.
Request Query
query{
user(user_no:1) {
user_name
}
}Response Data
{
'data': {
'user': {
'user_name': 'jim'
}
}
}장점
- 클라이언트가 필요한 데이터만 반환할 수 있습니다.
- 1번의 호출로 원하는 데이터를 한번에 가져올 수 있습니다.
- REST API의 N+1 문제를 해결할 수 있습니다.
- 확장이 용이합니다.
단점
- 백엔드, 클라이언트 개발자 양쪽 다 러닝커브가 있습니다.
- 단순한 서비스에서는 사용하기가 복잡합니다.
- 캐싱 기능의 구현이 복잡합니다.
- 대부분의 언어에서 라이브러리로 제공합니다.
- 요청이 text로 전송되기 때문에 File 전송 등을 구현하기가 어렵습니다.
GraphQL 스키마는 어떤 역할을 하며 어떤 식으로 정의되나요?
- node.js 상에서 GraphQL 서버를 실행하고 스키마를 정의하려면 어떻게 해야 하나요?
Schema-First-Develoment
스키마 우선주의는 디자인 방법론의 일종입니다. 말 그대로 개발 시에 스키마를 우선적으로 개발하는 것입니다. 여기사 스키마(Schema)란 데이터 타입의 집합 입니다. 이를 미리 정의해 두면, 스키마 정의는 API 문서 같은 역할을 하며, 프론트엔드 개발자와 백엔드 개발자가 많은 의사소토에 대한 비용을 줄이고, 빠른 개발을 할 수 있다는 장점이 있습니다.
백엔드 개발자는 어떤 데이터를 전달해야 하는지, 프론트엔드 개발자는 인터페이스 작업을 할 때 필요한 데이터를 정의할 수 있는 것입니다.
GraphQL Schema Structure
GraphQL의 API를 설계하기 전에 항상 사용할 스키마(Schema)를 먼저 정의해야 합니다. 왜냐하면 GraphQL 쿼리의 형태는 Return 되는 값과 거의 일치하기 때문입니다. 어떤 필드를 선택할지, 어떤 종류의 객체를 반환할지, 하위 객체에서 필요하며, 사용할 수 있는 필드는 무엇인지 알기 위해선 스키마의 존재가 필연적입니다.
GraphQL Schema Language
GraphQL은 스키마 정의를 위해 SDL(Schema Definition Language, 스키마 정의 언어)를 지원합니다. SDL 역시 프로그래밍 언어나 프레임워크와 상관없이 사용법이 항상 동일합니다.
Schema Documentation
Schema 에는 타입 정의를 모아둡니다. 확장자는 .graphql 입니다. GraphQL 스키마를 작성할 때는 옵션으로 각 필드에 대한 설명을 적을 수 있습니다.
Type
GraphQL 스키마의 핵심 단위 입니다. GraphQL에서 타입은 커스텀 객체이며, 이를 보고 애플리케이션의 핵심 기능을 알 수 있습니다. 아래는 간단한 예시입니다.
type Charecter {
id: ID!
name: String!
appearsln: [Episode]!
}Charector는 GraphQL의 객체 타입입니다. 스키마는 대부분 객체 타입이라고 보면 됩니다. 이런 타입은 애플리케이션의 데이터를 상징합니다. 그리고 곧 팀에서 도메인 객체에 대해 이야기할 때 사용할 공통의 언어*(Ubiquitous Language)를 정의하는 것과 같습니다. 따라서 이를 보고 애플리케이션의 핵심 기능을 알 수 있도록 짓는 것이 중요합니다.ID!는 GraphQL의 스칼라 타입이며, 고유 식별자 값이 반환되어야 하는 곳입니다.name,appersln은Charector타입의 필드(field) 입니다. 필드는 각 객체의 데이터와 관련이 있으며, 각각의 필드는 특정 종류의 데이터를 반환합니다. 이때 문자열, 커스텀 객체 타입, 여러 타입을 리스트로 묶어 반환하기도 합니다.String은 GraphQL에 내장된 스칼라 타입(기본 타입) 중 하나입니다.String!은 필드가non-nullable임을 의미합니다. 다시 말해 필수값을 정의했다고 보며, 이 값은 쿼리 할 때 항상 값을 반환한다는 것을 의미합니다. Type Language 에서는!느낌표로 나타냅니다.[Episode]!는Episode객체의 배열(Array)을 나타냅니다. 또한!이기 때문에appearsln필드를 쿼리할 때 항상 0개 이상의 아이템을 가진 배열을 기대할 수 있습니다.
Custom Scalar Type
스칼라 타입은 기본적으로 Int , Float , String , Boolean , ID 이지만, GraphQL에서는 커스텀 스칼라 타입을 지정하는 것도 가능합니다.
scalar DateTime! # 스칼라 타입 정의
type Character{
id: ID!
name: String!
appearsln: [Episode]!
created: DateTime! # 사용
}Enumeration Type
열거 타입 또한 스칼라 타입에 속하며, 특별한 종류의 스칼라입니다. 위에서 말했듯이 개발 언어가 열거 타입을 지원하느냐는 중요하지 않습니다.
열겨형 타입은 항상 허용된 값 중 하나임을 검증합니다.그리고 enum 키워드를 이용해 타입을 만들 수 있습니다.
enum Episode { # 열거 타입 정의
NEWHOPE
EMPIRE
JEDI
}
type Character{
id: ID!
name: String!
appearsln: [Episode]! # 반환되는 Episode 타입은 반드시 NEWHOPE, EMPIRE, JEDI 중 하나
}Node.js - GraphQL Schema 정의
Node.js 에서도 GraphQL 스키마를 정의할 수 있습니다.
schema.js
type User {
id: ID
name: String!
}
type Query {
self: User
}
function Query_self(request) {
return request.auth.user;
}
function User_name(user) {
return user.getName();
}GraphQL이 쿼리 요청을 받게되면 이를 시행하는데, 먼저 받은 쿼리가 타입, 필드로 정의되어 있는지 확인하고, 제공된 함수에 따라 결과를 반환하게 됩니다.
{
self {
name
}
}{
"self": {
"name": "Neo"
}
}GraphQL은 query/mutation 두 가지의 요청 방식이 존재합니다. 이 둘의 구조는 직관적이며 거의 유사합니다. 다만, 일반적으로 GET(R) 작업은 Query로, POST(CUD) 작업은 Mutation으로 정의합니다.
Argument
GraphQL은 쿼리할 때 인자를 건낼 수도 있습니다.
{
human(id: '123') {
name
age
}
}{
"data": {
"human": {
"name": "Neo",
"age": 33
}
}
}GraphQL 리졸버는 어떤 역할을 하며 어떤 식으로 정의되나요?
- GraphQL 리졸버의 성능 향상을 위한 DataLoader는 무엇이고 어떻게 쓰나요?
Root Field & Resolvers
resolvers 는 데이터를 가져오는 구체적인 과정을 담당합니다. 데이터베이스에서 데이터를 가져오거나, 파일에서 데이터를 가져오거나, 다른 네트워크 프로토콜을 활용해서 원격 데이터를 가져오는 것도 가능합니다. 그렇기 때문에 legecy 시스템이 있더라도 GraphQL 기반으로 바꿀 수 있습니다.
GraphQL에서 Query는 각각의 필드마다 일종의 함수가 하나씩 존재합니다. 그리고 이 함수를 통해 해당 타입을 반환합니다. 이때의 함수를 리졸버라고 합니다. 만약 필드가 함수가 아닌 경우, 실행이 종료됩니다.
기본적으로 resolver 호출은 깊이 탐색 방식으로 작동합니다. 따라서 하나의 타입에 대해 재귀적으로 호출하고 그 다음 타입으로 넘어가는 방식입니다.
모든 GraphQL 서버의 최상위 레벨은 GraphQL API에서 사용 가능한 모든 진입점을 나타내는 타입으로, Root 타입 또는 Query 타입이라고도 합니다.
아래 예제에서 Query 타입은 인자 id 를 받아 human 필드를 반환합니다. 이 필드의 resolver 함수는 데이터베이스에 접근한 다음 Human 객체를 생성하고 반환합니다.
Query: {
human(obj, args, context, info) {
return context.db.loadHumanByID(args.id).then(
userData => new Human(userData)
)
}
}resolver 함수는 네 개의 인수를 받습니다.
obj: 대부분 사용되지 않는 루트Query타입의 이전 객체args: GraphQL 쿼리의 필드에 제공된 인수context: 모든resolver함수에 전달되며, 현재 로그인한 사용자, 데이터베이스 액세스와 같은 중요한 문맥 정보를 보유하는 값info: 현재 쿼리, 스키마 정보와 관련된 필드별 정보를 보유하는 값
위 와 같은 리졸버는 아래와 같이 동작합니다.
context에서 데이터베이스 정보를 가져와 해당 데이터베이스에 접근합니다.- GraphQL 쿼리 필드로부터 받은 args의 id를 이용해
loadHumanByID라는 메소드를 호출합니다. userData를 가져와 이를 활용하여Human객체를 생성하고 반환합니다.
Dataloader
GraphQL 에서는 ORM을 사용할 때 처럼 N + 1 문제가 발생할 수 있습니다. 일반적인 ORM 에서의 N + 1 문제는 다음과 같습니다.
예를 들어 Post 엔티티와 Comment 엔티티가 있다고 가정할 때, 이 둘 사이의 관계는 1:N 입니다. 만약 Post 목록과 해당 Post에 해당하는 Comments를 조화하려고 한다면 각각의 Commnets + post, 즉 N + 1 만큼 쿼리가 실행됩니다. 이를 해결하기 위해서 JOIN 등의 방법을 사용할 수 있습니다.
위 문제는 GraphQL에서도 비슷한 방식으로 발생합니다.
type Post {
id: Int!
title: String!
content: String!
comments: [Comment!]!
}
type Comment {
id: Int!
content: String!
}
type Query {
posts: [Post!]!
}
query {
posts {
id
title
content
comments {
id
...
}
}
}const resolver = {
Query: {
posts: async () => {
return await Post.find()
}
},
Post: {
comments: async (root) => {
return Comment.find({ where: { postId: root.id } })
}
}
}보통 위와 같은 방식으로 resolver를 구성하게 되는데, posts에서 post에 대한 쿼리 1번, comments에 대한 쿼리 N번을 실행하게 됩니다. 예를 들어,
{
developers {
name
project {
name
}
}
}위와 같이 쿼리를 보내게 되면, 실제 sql 쿼리문은 아래와 같습니다
SELECT d.id, d.name, d.role FROM developer d - undefined
SELECT a.projectId, p.name, p.description FROM assignments a LEFT JOIN project p ON (p.id = a.projectId) WHERE a.developerId = $id - {"$id":1}
SELECT a.projectId, p.name, p.description FROM assignments a LEFT JOIN project p ON (p.id = a.projectId) WHERE a.developerId = $id - {"$id":2}
SELECT a.projectId, p.name, p.description FROM assignments a LEFT JOIN project p ON (p.id = a.projectId) WHERE a.developerId = $id - {"$id":3}
SELECT a.projectId, p.name, p.description FROM assignments a LEFT JOIN project p ON (p.id = a.projectId) WHERE a.developerId = $id - {"$id":4}
SELECT a.projectId, p.name, p.description FROM assignments a LEFT JOIN project p ON (p.id = a.projectId) WHERE a.developerId = $id - {"$id":5}
SELECT a.projectId, p.name, p.description FROM assignments a LEFT JOIN project p ON (p.id = a.projectId) WHERE a.developerId = $id - {"$id":6}
SELECT a.projectId, p.name, p.description FROM assignments a LEFT JOIN project p ON (p.id = a.projectId) WHERE a.developerId = $id - {"$id":7}
SELECT a.projectId, p.name, p.description FROM assignments a LEFT JOIN project p ON (p.id = a.projectId) WHERE a.developerId = $id - {"$id":8}
SELECT a.projectId, p.name, p.description FROM assignments a LEFT JOIN project p ON (p.id = a.projectId) WHERE a.developerId = $id - {"$id":9}
SELECT a.projectId, p.name, p.description FROM assignments a LEFT JOIN project p ON (p.id = a.projectId) WHERE a.developerId = $id - {"$id":10}
SELECT a.projectId, p.name, p.description FROM assignments a LEFT JOIN project p ON (p.id = a.projectId) WHERE a.developerId = $id - {"$id":11}
SELECT a.projectId, p.name, p.description FROM assignments a LEFT JOIN project p ON (p.id = a.projectId) WHERE a.developerId = $id - {"$id":12}이렇게 많은 쿼리문이 발생하는 이유는, developer와 project가 1:N 관계이기 때문입니다.
이를 DataLoader를 사용하게 되면
SELECT d.id, d.name, d.role FROM developer d - undefined
SELECT d.id, p.id as projectId, p.name, p.description
FROM developer d
LEFT JOIN assignments a
ON (d.id = a.developerId)
LEFT JOIN project p
ON (p.id = a.projectId)
WHERE d.id IN (?,?,?,?,?,?,?,?,?,?,?,?) - ["1","2","3","4","5","6","7","8","9","10","11","12"]위와 같이 짧아지게 됩니다.
DataLoader는 이와 같이 N+1 문제를 batch를 통해 1 + 1 로 변환해주는 라이브러리입니다. 주로 GraphQL에서 많이 사용되지만, 어떤 의존성을 가지고 있지는 않습니다.
DataLoader는 자바스크립트의 Event-Loop 를 이용합니다. 주요 기능으로 batching 을 사용하는데, 이것은 Event-Loop 에서 하나의 tick에 실행된 데이터 fetch에 대한 요청을 하나의 요청으로 모아서 실행하고, 그 결과를 다시 분배하는 역할을 합니다.
위에서 예시로 들었던 Post와 Commnet에 대한 DataLoader를 구현하려면 Post ID를 한번씩 쿼리하는 것이 아니라, 배열 형태로 캐싱해두고 있다가 한번에 batch 함수에 전달해야 합니다.
const batchLoadFn = async (postIds) => {
const posts = await Post.findAll();
return postIds.map((id) => posts.find((post) => post.id === id));
};
const commentsLoader = new DataLoader(batchLoadFn);Post: {
comments: async (post) => commentsLoader.load(post.id)
}출처 : GraphQL 소개
출처 : Basic GraphQL
클라이언트 상에서 GraphQL 요청을 보내려면 어떻게 해야 할까요?
Apollo Client
GraphQL API를 호출할 때 사용하는 클라이언트 라이브러리인 Apollo Client에 대해서 알아보겠습니다.
Apollo Client란, 자바스크립트를 위한 상태 관리 라이브러리입니다. GraphQL 쿼리를 작성하면서 Apollo Client는 데이터를 가져오고 캐싱을 해주고 UI를 업로드 해줍니다. GraphQL의 모든 요청은 POST로 하기 때문에 브라우저에서 캐싱이 되지 않습니다. 물론 캐싱뿐만이 아니라 많은 기능을 제공하기 때문에 사용합니다. 물론, HTTP 기반으로 동작하는 GraphQL API를 호출할 때 반드시 Apollo Client와 같은 전용 클라이언트 라이브러리가 필요한 것은 아닙니다.
장점?
데이터 관리 및 유지보수 능력이 좋습니다. 모든 상태를 전역으로 관리할 필요도 없으며, GraphQL 쿼리 형태 그대로 데이터를 가져올 수 있습니다.
import gql from 'graphql-tag';
import { useQuery } from '@apollo/react-hooks';
const GET_DOGS = gql`
{
dogs {
id
breed
}
}
`;const { loading, error, data } = useQuery(GET_DOGS);Loading, Error, Data등, 데이터 관리를 쉽게 할 수 있습니다.
Reference
GraphQL 이란
GraphQL이란?
아폴로 클라이언트(Apollo Client)란?
[GraphQL] Apollo Client 사용법
